注意到所有平台都可以遍历确保正确的context 被创建。下面的代码演示了opencl context 的创建。
cl_int lerror = cl_success;
std::string lbuffer;
//
// generic opencl creation.
// get platforms.
cl_uint lnbplatformid = 0;
clgetplatformids( 0 , 0 , &lnbplatformid );
if ( lnbplatformid == 0 )
{
}
// choose the first platform.
std::vector< cl_platform_id > lplatformids( lnbplatformid );
clgetplatformids( lnbplatformid , lplatformids.data() , 0 );
cl_platform_id lplatformid = lplatformids[ 0 ];
// get devices.
cl_uint lnbdeviceid = 0;
clgetdeviceids( lplatformid , cl_device_type_gpu , 0 , 0 , &lnbdeviceid );
if ( lnbdeviceid == 0 )
std::vector< cl_device_id > ldeviceids( lnbdeviceid );
clgetdeviceids( lplatformid , cl_device_type_gpu , lnbdeviceid , ldeviceids.data() , 0 );
// create the properties for this context.
cl_context_properties lcontextproperties[] = {
};
// try to find the device with the compatible context.
cl_device_id ldeviceid = 0;
cl_context lcontext = 0;
for ( size_t i = 0; i < ldeviceids.size(); ++i )
if ( ldeviceid == 0 )
// create a command queue.
cl_command_queue lcommandqueue = clcreatecommandqueue( lcontext , ldeviceid , 0 , &lerror );
if ( !checkforerror( lerror ) )
opencl context创建之后,opencl缓冲对象( typecl_mem类型)才可以创建,用来表示opengl textures共享。这些缓冲区并不会立即被分配内存,他们仅会成为 opengl textures缓冲区的引用,允许opencl进行读写。
为了创建opengl textures的引用,可以如下调用clcreatefromgltexture2d 函数。
注意到该函数在 opencl 1.2已经被clcreatefromgltexture取代,但clcreatefromgltexture2d 依然存在,以确保应用可以仅在opencl-1.1的系统中运行。
这些缓冲区可以像常规的 opencl缓冲区一样使用并被 opencl核心处理,这个核心将在下面的段落分析。
kernel的设计、实现和执行部分(注意这个是指opencl编程里的kernel)
本节的目的不是针opencl的概念和语义细节,而是针对为了描述这个问题提供一些元素(工具);在生成stereogram的算法语境里,设计kernel的设计主要考虑两个因素,其一是同一行的点的数据的从属计算,其二是对kernel来说不可能在运行时同时对一块图像buffer进行读或者写
那么kernel怎么处理数据呢
把kernel设计成只在数据的一个子集上执行,这样就可以让多核运算单元(指支持opencl的设备)并行的处理整个数据块。在opencl的图像处理算法里通常流行使用下面方法处理图像:一个kernel的instance只对图像的一个点处理,这样就可以并行的处理大量的数据。
但是生成stereogram的算法里同一行里每个点的从属性也需要计算,那么把kernel设计成用一行数据来代替一点数据会更合适一些,我们的设计采用把kernel一次对一行数据进行处理
**怎么避免从同一个数据buffer里同时读或写
**
和点数据从属性相关的另一个问题是在opencl的kernel不允许从同一块图像数据同时进行读和写,比如opencl的纹理不能在同一个渲染过程时既要采样(读)又要往里面写,但是对已经处理过的点又要求和后面待处理的点进行计算,这就需要调整一下算法。
我们发现一个简单的现象:一个不断重复的图像里点值是不需要查找它的尺寸。这样可以用一个同样宽度的本地buffer(称为local buffer)保存上次计算的偏移值(offsets),然后再把这个local buffer设计成环形buffer,来避免读/写冲突。当偏移offset计算完后,kernel总是从local buffer里读出,再把计算后的结果同时写入local buffer和output的图像buffer,这样就不会对output的图像buffer读操作。
当算法使用 gpgpu api实现时,这些适配类型是可以共用的。这些api通常提供不同的兼容性以适应不同版本cpu之间的差异,特别是针对同步原语。必要时可以修改api以适应特殊的算法。不管如何,他们可以被优化来使内核变得更快,例如使用更多的内存访问模式。将算法从 cpu 到 gpgpu时需谨记:即使很简单的问题也不容易直接转换。
处理这些设计问题时,可以提出一种内核的实现。下面一些代码讨论上面讨论的关键之处。
内核代码在运行前必须包含opencl驱动一起编译。像下面这样可以在任何opencl内核中编译:
一些参数被定义为常量,他们在整个内核执行过程中都会被使用。例如它可以允许运行环境调整 thekmaxoffsetparameter。这个变量的值可以作为参数传递给内核函数,但是在程序中保持不变因此它应该被定义为kernel-compile-time常量。
内核运行所需要最后一项工作是绑定内核参数,例如,输入和输出图像缓冲:
这些参数设置一次就可以让内核不断执行因为它们不会改变。内核运行在这些缓冲区之上,因此这些参数被set实例化而不是main函数的循环中。
在main循环中运行内核代码需要简单的三步:
1.同步opengl纹理,确保opencl使用它们时opengl 已经渲染完毕。
2.运行 opencl内核。
3.同步opengl纹理确保opencl返回它们时opengl 已经渲染完毕
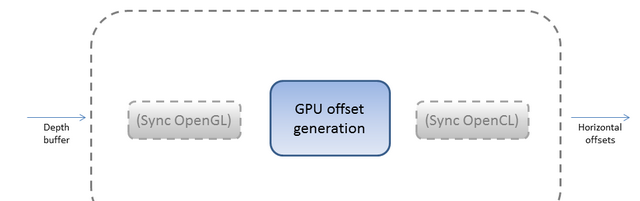
下面的代码展示如何执行这些任务:
偏移量将直接在gpu计算,不需要将数据从gpu传送到cpu再从cpu返回到gpu.
算法中将包含 gpu的实现。它展示了如何联合 opengl和 opencl,在避免内存和显存昂贵的数据往返时仍然保持了足够的灵活性去实现无往返数据的算法。
代码
本文中提供的代码实现了文中阐述的概念。这些代码在设计上不具有可重用性。它们被设计得尽量简单,尽量直接地调用opengl和opencl api,并且尽量减少依赖,来清楚地绘制文中的物体。事实上,文中的应用一开始是在一个个人框架中实现的,之后被精简来获得现在的最小化程序。
这个demo可以成功地在intel和nvidia硬件上运行,并没有在amd上测试,不过应该可以同样运行,或者只需少量修改。它可以在windows vista和windows 7(用microsoft visual studio编译)、ubuntu linux(用gcc编译)和osx mountain lion(用gcc编译)运行。
应用程序支持三种模式,可以通过space bar进行交替转换。第一种通过基本灯光进行场景的渲染绘制。第二是cpu实现的渲染绘制。第三种是gpu实现的渲染绘制。
在intel hd graphics 4000图形绘制硬件中,第一种模式(常规渲染)每秒可以绘制大约1180帧。第二种模式(cpu渲染)每秒可以绘制11帧。第三种模式(gpu渲染)可以绘制260帧。尽管通过每秒绘制的帧数不能精确的度量表现效果,他们仍提供一种结果的评价方法。很明显,通过避免从gpu到cpu的双重数据传送和使用gpu并行计算能力,可以实现更高质量的画面。
结论
这篇文章展示的立体图生成算法是一个证明使用gpgpu与渲染管道交互的能力的很好的机会。算法的一部分已经显示了要么无法仅仅使用可编程渲染管道(glsl着色器)实现,要么是一个非常低效、但可以使用opencl来轻易的获取opengl纹理来实现,以这种方式处理它们显然不是glsl友好的方法。
通过提供灵活的方法在gpu上直接实现更加复杂的算法,渲染管道(opengl)和gpgpu apis(opencl)的交互展示了一个用来处理有意思的(也就是很难的)的gpu数据处理的优雅高效的解决方式。它提供给开发者工具,通过更少的编程劳动来强调这些问题,而在gpu上实现算法是需要大量的编程劳动的,而且它甚至为更多的而不是常规可编程渲染管道提供的那些可能性打开了一扇门。
话虽这么说,这个实现可能仍然需要大量的改进。opencl不是一个魔杖,可以“自动”达到轻便的性能。优化opencl的实现可能是它自身的一个怪兽。。。所以进一步开发这个demo应用,看看它简单的实现是如何提升来达到更好的性能,这是很有意思的一件事。而且,opengl compute shader也是一个值得探索的,解决相似问题的一个有意思的路。
![ubuntu 16.04 源码安装httpd和php[图]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)