注意到所有平台都可以周遊確定正确的context 被建立。下面的代碼示範了opencl context 的建立。
cl_int lerror = cl_success;
std::string lbuffer;
//
// generic opencl creation.
// get platforms.
cl_uint lnbplatformid = 0;
clgetplatformids( 0 , 0 , &lnbplatformid );
if ( lnbplatformid == 0 )
{
}
// choose the first platform.
std::vector< cl_platform_id > lplatformids( lnbplatformid );
clgetplatformids( lnbplatformid , lplatformids.data() , 0 );
cl_platform_id lplatformid = lplatformids[ 0 ];
// get devices.
cl_uint lnbdeviceid = 0;
clgetdeviceids( lplatformid , cl_device_type_gpu , 0 , 0 , &lnbdeviceid );
if ( lnbdeviceid == 0 )
std::vector< cl_device_id > ldeviceids( lnbdeviceid );
clgetdeviceids( lplatformid , cl_device_type_gpu , lnbdeviceid , ldeviceids.data() , 0 );
// create the properties for this context.
cl_context_properties lcontextproperties[] = {
};
// try to find the device with the compatible context.
cl_device_id ldeviceid = 0;
cl_context lcontext = 0;
for ( size_t i = 0; i < ldeviceids.size(); ++i )
if ( ldeviceid == 0 )
// create a command queue.
cl_command_queue lcommandqueue = clcreatecommandqueue( lcontext , ldeviceid , 0 , &lerror );
if ( !checkforerror( lerror ) )
opencl context建立之後,opencl緩沖對象( typecl_mem類型)才可以建立,用來表示opengl textures共享。這些緩沖區并不會立即被配置設定記憶體,他們僅會成為 opengl textures緩沖區的引用,允許opencl進行讀寫。
為了建立opengl textures的引用,可以如下調用clcreatefromgltexture2d 函數。
注意到該函數在 opencl 1.2已經被clcreatefromgltexture取代,但clcreatefromgltexture2d 依然存在,以確定應用可以僅在opencl-1.1的系統中運作。
這些緩沖區可以像正常的 opencl緩沖區一樣使用并被 opencl核心處理,這個核心将在下面的段落分析。
kernel的設計、實作和執行部分(注意這個是指opencl程式設計裡的kernel)
本節的目的不是針opencl的概念和語義細節,而是針對為了描述這個問題提供一些元素(工具);在生成stereogram的算法語境裡,設計kernel的設計主要考慮兩個因素,其一是同一行的點的資料的從屬計算,其二是對kernel來說不可能在運作時同時對一塊圖像buffer進行讀或者寫
那麼kernel怎麼處理資料呢
把kernel設計成隻在資料的一個子集上執行,這樣就可以讓多核運算單元(指支援opencl的裝置)并行的處理整個資料塊。在opencl的圖像處理算法裡通常流行使用下面方法處理圖像:一個kernel的instance隻對圖像的一個點處理,這樣就可以并行的處理大量的資料。
但是生成stereogram的算法裡同一行裡每個點的從屬性也需要計算,那麼把kernel設計成用一行資料來代替一點資料會更合适一些,我們的設計采用把kernel一次對一行資料進行處理
**怎麼避免從同一個資料buffer裡同時讀或寫
**
和點資料從屬性相關的另一個問題是在opencl的kernel不允許從同一塊圖像資料同時進行讀和寫,比如opencl的紋理不能在同一個渲染過程時既要采樣(讀)又要往裡面寫,但是對已經處理過的點又要求和後面待處理的點進行計算,這就需要調整一下算法。
我們發現一個簡單的現象:一個不斷重複的圖像裡點值是不需要查找它的尺寸。這樣可以用一個同樣寬度的本地buffer(稱為local buffer)儲存上次計算的偏移值(offsets),然後再把這個local buffer設計成環形buffer,來避免讀/寫沖突。當偏移offset計算完後,kernel總是從local buffer裡讀出,再把計算後的結果同時寫入local buffer和output的圖像buffer,這樣就不會對output的圖像buffer讀操作。
當算法使用 gpgpu api實作時,這些适配類型是可以共用的。這些api通常提供不同的相容性以适應不同版本cpu之間的差異,特别是針對同步原語。必要時可以修改api以适應特殊的算法。不管如何,他們可以被優化來使核心變得更快,例如使用更多的記憶體通路模式。将算法從 cpu 到 gpgpu時需謹記:即使很簡單的問題也不容易直接轉換。
處理這些設計問題時,可以提出一種核心的實作。下面一些代碼讨論上面讨論的關鍵之處。
核心代碼在運作前必須包含opencl驅動一起編譯。像下面這樣可以在任何opencl核心中編譯:
一些參數被定義為常量,他們在整個核心執行過程中都會被使用。例如它可以允許運作環境調整 thekmaxoffsetparameter。這個變量的值可以作為參數傳遞給核心函數,但是在程式中保持不變是以它應該被定義為kernel-compile-time常量。
核心運作所需要最後一項工作是綁定核心參數,例如,輸入和輸出圖像緩沖:
這些參數設定一次就可以讓核心不斷執行因為它們不會改變。核心運作在這些緩沖區之上,是以這些參數被set執行個體化而不是main函數的循環中。
在main循環中運作核心代碼需要簡單的三步:
1.同步opengl紋理,確定opencl使用它們時opengl 已經渲染完畢。
2.運作 opencl核心。
3.同步opengl紋理確定opencl傳回它們時opengl 已經渲染完畢
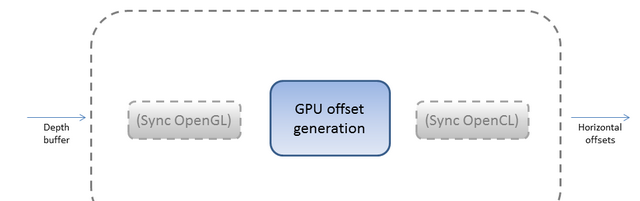
下面的代碼展示如何執行這些任務:
偏移量将直接在gpu計算,不需要将資料從gpu傳送到cpu再從cpu傳回到gpu.
算法中将包含 gpu的實作。它展示了如何聯合 opengl和 opencl,在避免記憶體和顯存昂貴的資料往返時仍然保持了足夠的靈活性去實作無往返資料的算法。
代碼
本文中提供的代碼實作了文中闡述的概念。這些代碼在設計上不具有可重用性。它們被設計得盡量簡單,盡量直接地調用opengl和opencl api,并且盡量減少依賴,來清楚地繪制文中的物體。事實上,文中的應用一開始是在一個個人架構中實作的,之後被精簡來獲得現在的最小化程式。
這個demo可以成功地在intel和nvidia硬體上運作,并沒有在amd上測試,不過應該可以同樣運作,或者隻需少量修改。它可以在windows vista和windows 7(用microsoft visual studio編譯)、ubuntu linux(用gcc編譯)和osx mountain lion(用gcc編譯)運作。
應用程式支援三種模式,可以通過space bar進行交替轉換。第一種通過基本燈光進行場景的渲染繪制。第二是cpu實作的渲染繪制。第三種是gpu實作的渲染繪制。
在intel hd graphics 4000圖形繪制硬體中,第一種模式(正常渲染)每秒可以繪制大約1180幀。第二種模式(cpu渲染)每秒可以繪制11幀。第三種模式(gpu渲染)可以繪制260幀。盡管通過每秒繪制的幀數不能精确的度量表現效果,他們仍提供一種結果的評價方法。很明顯,通過避免從gpu到cpu的雙重資料傳送和使用gpu并行計算能力,可以實作更高品質的畫面。
結論
這篇文章展示的立體圖生成算法是一個證明使用gpgpu與渲染管道互動的能力的很好的機會。算法的一部分已經顯示了要麼無法僅僅使用可程式設計渲染管道(glsl着色器)實作,要麼是一個非常低效、但可以使用opencl來輕易的擷取opengl紋理來實作,以這種方式處理它們顯然不是glsl友好的方法。
通過提供靈活的方法在gpu上直接實作更加複雜的算法,渲染管道(opengl)和gpgpu apis(opencl)的互動展示了一個用來處理有意思的(也就是很難的)的gpu資料處理的優雅高效的解決方式。它提供給開發者工具,通過更少的程式設計勞動來強調這些問題,而在gpu上實作算法是需要大量的程式設計勞動的,而且它甚至為更多的而不是正常可程式設計渲染管道提供的那些可能性打開了一扇門。
話雖這麼說,這個實作可能仍然需要大量的改進。opencl不是一個魔杖,可以“自動”達到輕便的性能。優化opencl的實作可能是它自身的一個怪獸。。。是以進一步開發這個demo應用,看看它簡單的實作是如何提升來達到更好的性能,這是很有意思的一件事。而且,opengl compute shader也是一個值得探索的,解決相似問題的一個有意思的路。
![ubuntu 16.04 源碼安裝httpd和php[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)