本节书摘来异步社区《hadoop mapreduce性能优化》一书中的第1章,第1.1节,作者: 【法】khaled tannir 译者: 范欢动 责编: 杨海玲,更多章节内容可以访问云栖社区“异步社区”公众号查看。
hadoop mapreduce性能优化
mapreduce编程模型的设计目标是,使用普通硬件的大型集群处理非结构化数据并产生大规模数据集。它能够在数千个计算节点的集群上处理tb级的数据,进行故障处理,完成任务复制并聚合最终结果。
要使用mapreduce,程序员需要编写一个用户定义的map函数和一个(同样是用户定义的)reduce函数来表示期望的计算逻辑。map函数读取键值对,执行用户指定的代码,产生中间结果。然后,通过reduce函数的用户指定代码聚合中间结果并输出最终结果。
mapreduce应用程序的输入按照每个输入规约加入到记录中,每个输入规约产生多个键值对,每个键值对以<k1, v1>形式表述。
因此,mapreduce处理过程包含以下两个主要环节。
map():对所有输入记录逐条执行用户定义的map函数,每条记录产生零到多个中间键值对,也就是<k2,v2>记录。然后所有的<k2,v2>记录都放到<k2,list(v2)>记录中。
reduce():按照键的不同,对每个map输出的<k2, list(v2)>记录调用一次用户定义的reduce函数;对于每条记录,reduce函数输出零到多个<k2, v3>对。所有的<k2, v3>对最后合并为最终结果。
.tifmap和reduce的函数签名如下:
map(<k1, v1>) list(<k2, v2>)
reduce(<k2, list(v2)>) <code></code> <k2, v3>
mapreduce编程模型的设计独立于存储系统。mapreduce通过reader从底层存储系统读取键值对。reader从存储系统读取所有记录,并封装成键值对供后续处理。用户可以通过实现相应的reader增加对新存储系统的支持。这种存储独立的设计使mapreduce能够分析保存在不同存储系统中的数据,为异构系统带来了极大便利。
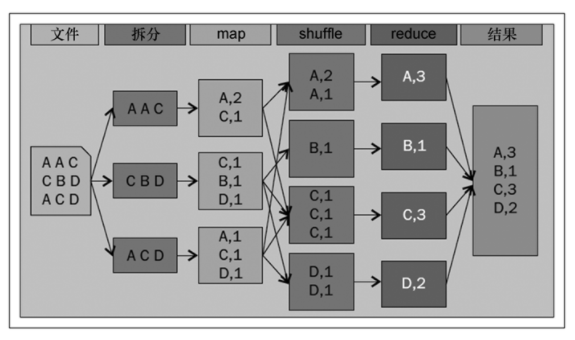
为了理解mapreduce编程模型,我们假设你需要从给定的输入文件中获得每一个单词出现的次数。将其转化成为mapreduce作业,单词计数作业通过以下几个步骤定义。
输入数据拆分成记录。
map函数处理上述记录,并对每个单词生成键值对。
合并map函数输出的所有键值对,并根据键分组、排序。
将中间结果发送给reduce函数,由reduce函数产生最终输出。
这个mapreduce应用的完整步骤如图1-1所示。
进行键值对的聚合操作时,会产生的大量i/o以及网络流量i/o。为了压缩map和reduce步骤间需要的i/o网络流量,程序员可以选择在map一侧进行预聚合,而预聚合通过提供combiner函数完成。combiner函数与reduce函数类似,其不同之处在于,前者并不传递给定键的所有值,而是把传递进来的输入值之和作为输出值传递出去。
![Centos7 下 Hadoop 2.6.4 分布式集群环境搭建 摘要 集群准备 安装JDK 安装 Hadoop 2.6.4 部署 slaver1-slaver4 启动 hadoop 集群 成功了[图]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)