本節書摘來異步社群《hadoop mapreduce性能優化》一書中的第1章,第1.1節,作者: 【法】khaled tannir 譯者: 範歡動 責編: 楊海玲,更多章節内容可以通路雲栖社群“異步社群”公衆号檢視。
hadoop mapreduce性能優化
mapreduce程式設計模型的設計目标是,使用普通硬體的大型叢集處理非結構化資料并産生大規模資料集。它能夠在數千個計算節點的叢集上處理tb級的資料,進行故障處理,完成任務複制并聚合最終結果。
要使用mapreduce,程式員需要編寫一個使用者定義的map函數和一個(同樣是使用者定義的)reduce函數來表示期望的計算邏輯。map函數讀取鍵值對,執行使用者指定的代碼,産生中間結果。然後,通過reduce函數的使用者指定代碼聚合中間結果并輸出最終結果。
mapreduce應用程式的輸入按照每個輸入規約加入到記錄中,每個輸入規約産生多個鍵值對,每個鍵值對以<k1, v1>形式表述。
是以,mapreduce處理過程包含以下兩個主要環節。
map():對所有輸入記錄逐條執行使用者定義的map函數,每條記錄産生零到多個中間鍵值對,也就是<k2,v2>記錄。然後所有的<k2,v2>記錄都放到<k2,list(v2)>記錄中。
reduce():按照鍵的不同,對每個map輸出的<k2, list(v2)>記錄調用一次使用者定義的reduce函數;對于每條記錄,reduce函數輸出零到多個<k2, v3>對。所有的<k2, v3>對最後合并為最終結果。
.tifmap和reduce的函數簽名如下:
map(<k1, v1>) list(<k2, v2>)
reduce(<k2, list(v2)>) <code></code> <k2, v3>
mapreduce程式設計模型的設計獨立于存儲系統。mapreduce通過reader從底層存儲系統讀取鍵值對。reader從存儲系統讀取所有記錄,并封裝成鍵值對供後續處理。使用者可以通過實作相應的reader增加對新存儲系統的支援。這種存儲獨立的設計使mapreduce能夠分析儲存在不同存儲系統中的資料,為異構系統帶來了極大便利。
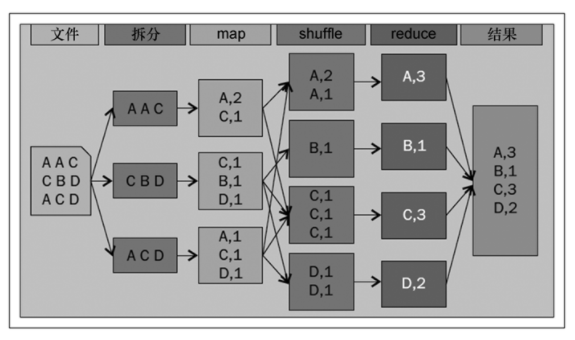
為了了解mapreduce程式設計模型,我們假設你需要從給定的輸入檔案中獲得每一個單詞出現的次數。将其轉化成為mapreduce作業,單詞計數作業通過以下幾個步驟定義。
輸入資料拆分成記錄。
map函數處理上述記錄,并對每個單詞生成鍵值對。
合并map函數輸出的所有鍵值對,并根據鍵分組、排序。
将中間結果發送給reduce函數,由reduce函數産生最終輸出。
這個mapreduce應用的完整步驟如圖1-1所示。
進行鍵值對的聚合操作時,會産生的大量i/o以及網絡流量i/o。為了壓縮map和reduce步驟間需要的i/o網絡流量,程式員可以選擇在map一側進行預聚合,而預聚合通過提供combiner函數完成。combiner函數與reduce函數類似,其不同之處在于,前者并不傳遞給定鍵的所有值,而是把傳遞進來的輸入值之和作為輸出值傳遞出去。
![Centos7 下 Hadoop 2.6.4 分布式叢集環境搭建 摘要 叢集準備 安裝JDK 安裝 Hadoop 2.6.4 部署 slaver1-slaver4 啟動 hadoop 叢集 成功了[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)