本节书摘来自华章出版社《spark大数据分析:核心概念、技术及实践》一书中的第3章,第3.6节,作者[美] 穆罕默德·古勒(mohammed guller),更多章节内容可以访问云栖社区“华章计算机”公众号查看。
3.6 惰性操作
rdd的创建和转换方法都是惰性操作。当应用调用一个返回rdd的方法的时候,spark并不会立即执行运算。比如,当你使用sparkcontext的textfile方法从hdfs中读取文件时,spark并不会马上从硬盘中读取文件。类似地,rdd转换操作(它会返回新rdd)也是惰性的。spark会记录作用于rdd上的转换操作。
让我们考虑如下示例代码。
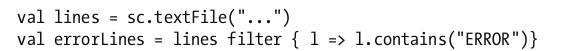
上面三行代码看起来很快就会执行完,哪怕textfile方法读取的是一个包含了10tb数据的文件。这其中的原因是当你调用textfile方法时,它并没有真正读取文件。类似地,filter方法也没有立即遍历原rdd中的每一个元素。
spark仅仅记录了这个rdd是怎么创建的,在它上面做转换操作会创建怎样的子rdd等信息。spark为每一个rdd维护其各自的血统信息。在需要的时候,spark利用这些信息创建rdd或重建rdd。
如果rdd的创建和转换都是惰性操作,那么spark什么时候才真正读取数据和做转换操作的计算呢?下面将会解答这个问题。
触发计算的操作
当spark应用调用操作方法或者保存rdd至存储系统的时候,rdd的转换计算才真正执行。保存rdd至存储系统也被视为一种操作,尽管它并没有向驱动程序返回值。
当spark应用调用rdd的操作方法或者保存rdd的时候,它触发了spark中的连锁反应。当调用操作方法的时候,spark会尝试创建作为调用者的rdd。如果这个rdd是从文件中创建的,那么spark会在worker节点上读取文件至内存中。如果这个rdd是通过其他rdd的转换得到的子rdd,spark会尝试创建其父rdd。这个过程会一直持续下去,直到spark找到根rdd。然后spark就会真正执行这些生成rdd所必需的转换计算,从而生成作为调用者的rdd。最后,执行操作方法所需的计算,将生成的结果返回给驱动程序。
惰性转换使得spark可以高效地执行rdd计算。直到spark应用需要操作结果时才进行计算,spark可以利用这一点优化rdd的操作。这使得操作流水线化,而且还避免了在网络间不必要的数据传输。
![Spark在windows环境里跑时报错找不到org.apache.hadoop.fs.FSDataInputStream[图]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)