本節書摘來自華章出版社《spark大資料分析:核心概念、技術及實踐》一書中的第3章,第3.6節,作者[美] 穆罕默德·古勒(mohammed guller),更多章節内容可以通路雲栖社群“華章計算機”公衆号檢視。
3.6 惰性操作
rdd的建立和轉換方法都是惰性操作。當應用調用一個傳回rdd的方法的時候,spark并不會立即執行運算。比如,當你使用sparkcontext的textfile方法從hdfs中讀取檔案時,spark并不會馬上從硬碟中讀取檔案。類似地,rdd轉換操作(它會傳回新rdd)也是惰性的。spark會記錄作用于rdd上的轉換操作。
讓我們考慮如下示例代碼。
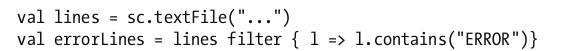
上面三行代碼看起來很快就會執行完,哪怕textfile方法讀取的是一個包含了10tb資料的檔案。這其中的原因是當你調用textfile方法時,它并沒有真正讀取檔案。類似地,filter方法也沒有立即周遊原rdd中的每一個元素。
spark僅僅記錄了這個rdd是怎麼建立的,在它上面做轉換操作會建立怎樣的子rdd等資訊。spark為每一個rdd維護其各自的血統資訊。在需要的時候,spark利用這些資訊建立rdd或重建rdd。
如果rdd的建立和轉換都是惰性操作,那麼spark什麼時候才真正讀取資料和做轉換操作的計算呢?下面将會解答這個問題。
觸發計算的操作
當spark應用調用操作方法或者儲存rdd至存儲系統的時候,rdd的轉換計算才真正執行。儲存rdd至存儲系統也被視為一種操作,盡管它并沒有向驅動程式傳回值。
當spark應用調用rdd的操作方法或者儲存rdd的時候,它觸發了spark中的連鎖反應。當調用操作方法的時候,spark會嘗試建立作為調用者的rdd。如果這個rdd是從檔案中建立的,那麼spark會在worker節點上讀取檔案至記憶體中。如果這個rdd是通過其他rdd的轉換得到的子rdd,spark會嘗試建立其父rdd。這個過程會一直持續下去,直到spark找到根rdd。然後spark就會真正執行這些生成rdd所必需的轉換計算,進而生成作為調用者的rdd。最後,執行操作方法所需的計算,将生成的結果傳回給驅動程式。
惰性轉換使得spark可以高效地執行rdd計算。直到spark應用需要操作結果時才進行計算,spark可以利用這一點優化rdd的操作。這使得操作流水線化,而且還避免了在網絡間不必要的資料傳輸。
![Spark在windows環境裡跑時報錯找不到org.apache.hadoop.fs.FSDataInputStream[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)