负载均衡(server load balancer,下文简称 slb)的引入,可以降低单台云服务器 ecs(下文简称 ecs)出现异常时对业务的冲击,提升业务的可用性。同时,结合弹性伸缩服务,通过动态调整后端服务器,可以快速对业务进行弹性调整(扩容或缩容),以快速应对业务的发展。
本文,会先对 slb 的使用限制和常见误区进行说明,然后介绍 slb 的使用最佳实践。
在开始使用 slb 之前,建议您务必阅读如下文章,了解 slb 的相关基础原理:
<a href="https://help.aliyun.com/knowledge_detail/39444.html">负载均衡技术原理浅析</a>
<a href="https://help.aliyun.com/knowledge_detail/39455.html">负载均衡健康检查原理浅析</a>
<a href="https://help.aliyun.com/knowledge_detail/39440.html">负载均衡网络流量路径说明</a>
<a href="https://help.aliyun.com/knowledge_detail/39449.html">负载均衡高可用概要说明</a>
在使用 slb 进行业务部署之前,请您务必了解 slb 的相关使用限制,以免对后续使用造成困扰或对业务造成影响。
slb 在技术层面还在逐步增强和完善,截止本文发稿,还存在如下技术限制:
在 4 层(tcp 协议)服务中,不支持添加进后端云服务器池的 ecs 既作为 real server,又作为客户端向所在的 slb 实例发送请求。因为,返回的数据包只在云服务器内部转发,不经过负载均衡,所以通过配置在 slb 后端的 ecs 去访问其 vip 是不通的。
仅支持 tcp/udp(4 层) 和 http/https(7 层) 这 4 种协议。
后端服务器仅支持 ecs,不支持第三方云服务器。
仅支持轮询(rr)、加权轮询(wrr)和最小加权连接数(wlc)这 3 中调度算法。
不支持 7 层 ssl session 超时时间的调整。当前全局统一为 300s。
不支持 7 层 http keep-alive 超时时间的调整。当前配置为 15s。
说明:如果客户端访问 slb http 监听时使用长连接, 那么这条连接最长的空闲时间为 15 秒, 即如果超过 15 秒没有发送任何 http 请求, 这条连接将会被 slb 主动断开。如果您的业务可能会出现超过 15 秒的空闲, 需要从业务层面检测连接的断开并重新发起连接。
不支持转发超时时间的调整:
当前配置: tcp 900s,udp 300s,http 60s,https 60s
上述配置是指 slb 服务端从后端接收数据并进行转发的超时时间,并非健康检查超时时间间隔。如果超时,通常会向客户端返回 504 错误码。
金融云 slb 基于安全性考虑,仅允许开放特定的端口:80,443,2800-3300,6000-10000,13000-14000
从历史案例看,用户在 slb 的规划和使用过程中有很多常见误区。接下来逐一说明。
用户在 slb 后端只添加一台服务器时,虽然链路能跑通,客户端也能正常访问。但却失去了 slb 消除 ecs 单点的基本能力。如果这台仅有的 ecs 出现异常,那边整个业务访问也会出现异常。
建议:至少在 slb 后端加入两台以上 ecs。以便单一服务器出现异常时,业务还能持续正常访问。
用户通过 slb 访问业务出现异常。但 hosts 绑定后端 ecs 的公网 ip 能正常访问。用户据此推断后端业务是正常的,是 slb 服务端出现异常导致业务访问异常。
其实,由于负载均衡的数据转发和健康检查都是通过内网进行的。所以,从后端 ecs 的公网 ip 进行对比访问测试,并没有可比性,并不能反应真实访问情况。
建议:出现异常时,在后端 ecs 之间,通过内网 ip 做对比访问测试。
用户通过 ping slb 的 vip 地址来判断 slb 服务的有效性。
其实,这种测试非常不可靠。因为 ping 响应是由 slb 服务端直接完成的,与后端 ecs 无关。所以,正常情况下:
只要配置了任意监听,即便相应监听处于异常状态,slb vip ping 也是正常的。
相反,如果 slb 没有配置任何监听,其 vip 是 ping 不通的。
建议:对于 4 层服务,通过 telnet 监听端口进行业务可用性测试;对于 7 层服务,通过实际的业务访问进行可用性测试。
用户反馈已经调大了健康检查的最大间隔时间,但客户端访还是由于访问超时收到 504 错误。
其实,虽然健康检查及业务转发都是由 slb 服务端相同的服务器承载,但却是完全不同维度的处理逻辑。来自客户端的请求,经由 slb 转发给后端 ecs 后,slb 服务端会有接收数据的超时窗口。而另一方面,slb 服务端持续的对后端 ecs 根据检查间隔配置进行健康检查。这两者之间没有直接关系,唯一的影响是在后端 ecs 健康检查失败后,slb 不会再对其进行数据转发。
建议:客户端访问超时时,结合业务与 slb 默认超时时间进行比对分析;健康检查超时时,结合健康检查与业务超时时间进行比对分析。
用户反馈通过 slb 后端 ecs 的业务日志进行统计分析,发现健康检查的间隔非常短,与之前在创建监听时配置的健康检查间隔时间不一致。
用户认为 slb 服务端使用上百台机器进行健康检查,大量健康检查请求会形成 ddos 攻击,造成后端 ecs 性能降低。
实际上,无论何种模式的健康检查,其规模均不足以达到类似于 ddos 攻击的量级:slb 集群会利用多台机器(假定为 m 个,个位数级别),对后端 ecs 的每个服务监听端口 (假定为 n 个) ,按照配置的健康检查间隔(假定为 o 秒,一般建议最少 2 秒)进行健康检查。以 tcp 协议健康检查为例,那么每秒由健康检查产生的 tcp 连接建立数为:<code>m*n/o</code>。
从该公式可以看出,m 和 n 都是固定的,而且值很小。所以,最终健康检查带来的每秒 tcp 并发请求数,主要取决于创建的监听端口数量。所以,除非有巨量的监听端口,否则由健康检查产生的连接请求,根本无法达到 syn flood 的攻击级别,实际对后端 ecs 的网络压力也极低。
用户为了降低健康检查对业务的影响,将检查间隔时间设置得很长。
这样配置会导致当后端 ecs 出现异常时,负载均衡需要经过较长时间才能侦测到后端 ecs 出现不可用。尤其是当后端 ecs 间歇性不可用时,由于需要【连续多次】检测失败时才会移除异常 ecs。所以,检查间隔过长,会导致负载均衡集群可能根本无法发现后端 ecs 不可用。
用户在进行业务调整时,认为直接将服务器从 slb 后端移除,或将其权重置零即可,两者效果是一样的。
其实,两者有很大区别,相关操作对业务的影响也不一致:
移除服务器:已经建立的连接会一并中断,新建连接也不会再转发到该 ecs。
权重置零:已经建立的连接不会中断,直至超时或主动断开。新连接不会转到该 ecs。
建议:在业务调整或服务器维护时,提前将相应服务器的权重置零,直至连接持续衰减至零。操作完成后,再恢复权重配置,以降低对业务的影响。
slb 在创建监听时可以指定带宽峰值。但用户通过单一客户端进行测试时,发现始终无法达到该峰值。
由于 slb 是基于集群方式部署和提供服务的。所以,所有前端请求会被均分到集群内不同的 slb 服务器上进行转发。相应的,在监听上设定的带宽峰值也会被平分后设定到各服务器。因此,单个连接下载的流量上限公式为:
示例:
假设在控制台上设置的带宽峰值为 10mb,那么单个客户端可下载的最大流量为: <code>10/(4-1)≈3.33mb</code>
建议:建议在配置单个监听的带宽峰值时,根据实际的业务情况并结合上述实现方式设定一个较为合理的值,从而确保业务的正常对外服务不会受到影响和限制。
接下来,结合 slb 的产品特性与历史案例,从多个维度阐述使用 slb 的最佳实践。
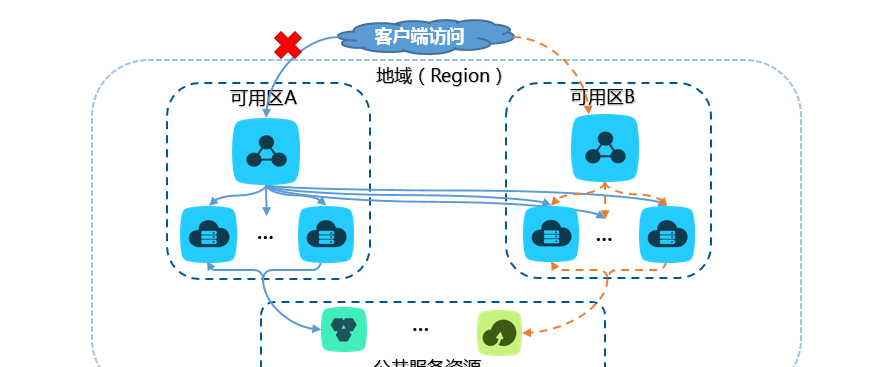
注:内网环境下,不支持多可用区,只看图例的单边即可。
slb 在公网环境下的典型业务架构如上图所示。基于多可用区特性,当主可用区出现异常时,slb 会自动将流量切换到备可用区。但在实际的业务架构设计过程中,建议关注如下要点:
实例类型与计费方式
如果只用于内部服务分发,则创建私网实例即可。
按流量计费,适用于波峰波谷效应明显的业务。
按带宽计费,适用于带宽较为平稳的业务。
区域与多可用区
为了降低延迟,建议选择离您客户最近的地域进行 slb 部署。
并非所有区域都支持多可用区特性(具体支持情况以您在控制台所见为准),请您结合业务情况选择合适的可用区。
在配合使用多可用区特性时,后端 ecs 也必须同时在相应的主备可用区部署,才能保障出现异常时,相应可用区有 ecs 能进行业务承载。

如上图所示,slb 支持创建多种协议监听,然后按转发策略,将前端业务请求转发到后端多种逻辑服务器集。在 slb 服务配置的各主要步骤中,请关注如下要点。
slb 支持创建 tcp/ucp/http/https 这 4 种协议的监听。您可参考以下表格,根据业务情况选择适合的协议创建监听:
协议类型
建议的应用场景
特性
tcp
●注重可靠性,对数据准确性要求高,速度可以相对较慢的场景;
●示例:文件传输、发送或接收邮件、远程登录、无特殊要求的 web 应用
●面向连接的协议;
●在正式收发数据前,必须和对方建立可靠的连接;
●基于源地址会话保持,在网络层可直接看到来源地址;
●监听支持 tcp 和 http 两种方式进行健康检查;
●转发路径短,所以性能比 7 层更好,数据传输速度更快
http
需要对数据内容进行识别的应用,如 web 应用、小的手机游戏等
●应用层协议,主要解决如何包装数据;
●基于 cookie 会话保持;使用 x-forward-for 获取源地址;
●监听只支持 http 方式健康检查
https
有更高的安全性需求,需要加密传输的应用
●加密传输数据,可以阻止未经授权的访问;
●统一的证书管理服务,用户可以将证书上传到负载均衡,解密操作直接在负载均衡上完成
udp
●关注实时性而相对不注重可靠性的场景;
●示例:视频聊天、金融实时行情推送
●面向非连接的协议;
●在数据发送前不与对方进行三次握手,直接进行数据包发送,不提供差错恢复和数据重传;
●可靠性相对低;数据传输快
补充说明
并非只要 web 网站就必须使用 http 协议。大部分没有特殊 http 要求的 web 网站,使用 tcp 监听 80 端口就可以满足业务需求。
slb 集群采用 lvs 和 tengine 实现。其中 4 层监听(tcp/udp)经过 lvs 后直接到达后端服务器,而 7 层监听(http/https)经过 lvs 后,还需要再经过 tengine 转发,最后达到后端服务器,由于比 4 层多了一个处理环节。因此,7 层监听的性能相对要差一些。
slb 后端服务器支持按 3 种逻辑创建服务器集。要点如下:
集合模式
配置权重
指定服务端口
服务器数量限制
其它特性
后端服务器
支持
不支持
无限制
创建监听时的默认映射服务器集
虚拟服务器组
有更大的灵活性
主备服务器组
2 台
只能在 tcp/udp 监听上使用
建议
按业务逻辑创建不同的虚拟服务器组,然后创建相应的监听与之对应。
无论创建何种服务器集合,均结合 slb 多可用区特性,同时加入位于不同可用区的服务器,以实现跨可用区容灾。
设置过多转发规则会增加业务维护的复杂度,建议尽量精简策略条目。
权重代表相应服务器所承载的业务的相对占比,而非绝对值。当前 slb 支持 3 种转发策略,其使用场景及要点如下:
转发策略
算法说明
使用要点
加权轮询(wrr)
按比重轮流分配新增连接。
●根据后端 ecs 规格的不同,配置相应的权重。
●如果是长连接业务,可能会导致老服务器的连接数持续增加, 而新加入服务器的连接数相对非常低,造成负载不均的假象。
加权最小连接数(wlc)
●在 slb 服务端,实时统计与后端 ecs 已建立的 established 状态连接数,来评估相应服务器的负载情况。
●按权重比例,将新增连接分配给活动连接数少的服务器,最终尽可能使服务器的已建立连接数与其权重成正例。
当前暂未实现新增服务器的过载保护或缓冲机制。所以,如果业务并发非常高,可能会导致新增服务器连接数陡增,对业务造成影响。建议新增服务器时,逐步调高权重。
轮询(rr)
按顺序逐一分发新增连接。
必须手工确保后端 ecs 的业务承载能力一致。
示例:假设有 100 个新增连接,则在不同的调度算法下,不同服务器的分配连接数示意如下:
服务器
权重
占比
加权轮询
加权最小连接数
轮询
a
50
50/
(100+50+50)
=25%
将 100*25%=25 个连接分发给服务器 a
实时统计连接数,逐一将新增连接分配给活动连接数最少的服务器。最终使其新增连接数占比大致为 25%
不考虑权重,按顺序分发新增连接到服务器 a/b/c
b
100
100/
=50%
将 100*50%=50 个连接分发给服务器 b
↑ 同上,最终使其新增连接数占比大致为 50%
↑ 同上
c
(100+50+50)=
25%
将 100*25%=25 个连接分发给服务器 c
↑ 同上,最终使其新增连接数占比大致为 25%
d
0/
=0%
服务器下线,不分配任何连接
← 同左
健康检查用于实时探测后端 ecs 上的业务可用性,以避免新增连接被分发到异常服务器对业务造成影响。由于是 slb 依赖的核心服务,所以 4 层协议(tcp/ucp)的健康检查无法关闭。
在配置健康检查时,注意如下要点:
根据业务情况合理选择 tcp 或 http 模式健康检查
tcp 模式健康检查只能检查端口的可用性,对 7 层 http 状态无法感知。所以,web 类 7 层业务建议配置 http 模式健康检查。
如果使用 http 健康检查模式,建议合理调整后端日志配置,避免健康检查 head 请求过多对 io 性能造成影响。
合理配置健康检查间隔
合理配置检查端口与检查 url
对于 4 层 tcp 协议,由于虚拟服务器组可以由后端 ecs 不同的端口承载业务,因此在配置健康检查时不要设置检查端口,而应该"默认使用后端服务器的端口进行健康检查"。否则可能导致后端 ecs 健康检查失败。
对于 7 层 http 协议,使用虚拟服务器组合转发策略时,确保健康检查配置策略中的 url 在后端每台机器上都可以访问成功。
使用 http 模式健康检查时,不要对根目录进行检查。建议配置为对某个静态页面或文件进行检查以降低对主页的冲击。但是,相应的,这可能会导致误判:健康检查 url 虽然访问是正常的,但主页实际上已经出现异常。
udp 健康检查
当前 udp 协议健康检查可能存在服务真实状态与健康检查不一致的问题:
如果后端 ecs 服务器是 linux 服务器,在大并发场景下,由于 linux 的防 icmp 攻击保护机制,会限制服务器发送 icmp 的速度。此时,即便服务已经出现异常,但由于无法向前端返回 “port xx unreachable” 报错信息,会导致负载均衡由于没收到 icmp 应答进而判定健康检查成功,最终导致服务真实状态与健康检查不一致。
如果相应服务器非正常关机,由于也不会返回 “port xx unreachable” 报错信息。所以也会导致健康检查处于"正常"状态的误报。
在后端 ecs 的选择与配置时,注意如下要点:
在同一个服务器集中,同时加入不同可用区的服务器,以实现同城容灾
根据服务器规格的差异,配置与之成正比的权重
slb 后端最少配置两台以上 ecs,以避免单台 ecs 出现异常导致整个业务也出现异常
后端 ecs 建议无状态部署:即只用于计算,而数据调用与存储后连至后端的 oss、rds 等公共服务。这样可以无需为 ecs 之间的数据同步问题而困扰。
建议基于相同的镜像或自定义镜像创建后端 ecs 服务器,以保障配置的一致性。
后端 ecs 归属安全组及系统内部防火墙必须对 slb 服务端地址段进行访问放行。
在往 slb 内新增服务器时,注意如下要点:
建议新增服务器时,将权重置零,在确保业务正常运行后,再调整权重使其上线。
如果业务是长连接,在新增服务器时,建议先将相应监听的调度算法修改为轮询模式,然后逐步调高新增服务器的权重,以降低对该新增服务器的过高冲击。
在后端 ecs 服务器的日常调整、维护过程中,注意如下要点:
选择合适的业务窗口,定期对后端 ecs 进行重启操作(操作前先创建快照进行备份),以便应用系统补丁,并主动触发、感知系统内部错误导致的服务器无法正常启动等问题。
业务更新或系统维护时建议的操作步骤:
如果确认服务器不再使用,不建议直接移除服务器。而是参阅前述步骤,将相应服务器权重置零。待已建立连接全部正常断开后,再移除该服务器。
slb 在使用过程中的常见问题与排查思路可以参阅下列文档,本文不再详述:
<a href="https://help.aliyun.com/document_detail/27702.html">健康检查异常的排查思路</a>
<a href="https://help.aliyun.com/knowledge_detail/39481.html">负载均衡返回 http 500/502/504 错误的处理</a>
<a href="https://help.aliyun.com/knowledge_detail/39491.html">后端 ecs 负载不均衡问题的处理</a>
问题场景:
后端 ecs 规格均一致,但其中几台服务器的 pps 一直非常高。而新加入的服务器,相对负载非常低。
业务高峰期,相关服务器健康检查异常,导致服务器下线,并进一步导致其它服务器负载升高,引发整个 slb 后端出现雪崩式异常,业务受到严重影响。
排查思路:
业务监听使用 wrr 调度算法,在 slb 服务端统计,在单位时间内分发到各服务器的连接数是均衡的。
异常服务器上的连接数持续居高不下,尝试调高 os 层面的 tcp 连接数限制等配置,无明显效果。
和客户交流,结合业务分析,相关连接来源正常,都是正常的业务连接。但业务场景是物联网的监控数据上报,使用的是长连接。所以除非主动断开相关连接,否则相关连接会持续堆积。
应对措施:
将负载较低的服务器的权重值调低。
将监听的调度算法修改为 wlc。
将异常服务器的权重值置零。
将负责较低的服务器的权重值逐步调高。
以上步骤用于将负载逐步转移到新加入的服务器,并避免对新增服务器及异常服务器的冲击。
待异常服务器的连接数下降到合理水平后,将其重新上线(重新配置权重)。
由于后端服务器负载总体偏高,导致业务高峰期多台服务器无法满足业务需求,出现雪崩式异常。所以,同步建议客户对 slb 后端服务器进行扩容。