負載均衡(server load balancer,下文簡稱 slb)的引入,可以降低單台雲伺服器 ecs(下文簡稱 ecs)出現異常時對業務的沖擊,提升業務的可用性。同時,結合彈性伸縮服務,通過動态調整後端伺服器,可以快速對業務進行彈性調整(擴容或縮容),以快速應對業務的發展。
本文,會先對 slb 的使用限制和常見誤區進行說明,然後介紹 slb 的使用最佳實踐。
在開始使用 slb 之前,建議您務必閱讀如下文章,了解 slb 的相關基礎原理:
<a href="https://help.aliyun.com/knowledge_detail/39444.html">負載均衡技術原理淺析</a>
<a href="https://help.aliyun.com/knowledge_detail/39455.html">負載均衡健康檢查原理淺析</a>
<a href="https://help.aliyun.com/knowledge_detail/39440.html">負載均衡網絡流量路徑說明</a>
<a href="https://help.aliyun.com/knowledge_detail/39449.html">負載均衡高可用概要說明</a>
在使用 slb 進行業務部署之前,請您務必了解 slb 的相關使用限制,以免對後續使用造成困擾或對業務造成影響。
slb 在技術層面還在逐漸增強和完善,截止本文發稿,還存在如下技術限制:
在 4 層(tcp 協定)服務中,不支援添加進後端雲伺服器池的 ecs 既作為 real server,又作為用戶端向所在的 slb 執行個體發送請求。因為,傳回的資料包隻在雲伺服器内部轉發,不經過負載均衡,是以通過配置在 slb 後端的 ecs 去通路其 vip 是不通的。
僅支援 tcp/udp(4 層) 和 http/https(7 層) 這 4 種協定。
後端伺服器僅支援 ecs,不支援第三方雲伺服器。
僅支援輪詢(rr)、權重輪詢(wrr)和最小權重連接配接數(wlc)這 3 中排程算法。
不支援 7 層 ssl session 逾時時間的調整。目前全局統一為 300s。
不支援 7 層 http keep-alive 逾時時間的調整。目前配置為 15s。
說明:如果用戶端通路 slb http 監聽時使用長連接配接, 那麼這條連接配接最長的空閑時間為 15 秒, 即如果超過 15 秒沒有發送任何 http 請求, 這條連接配接将會被 slb 主動斷開。如果您的業務可能會出現超過 15 秒的空閑, 需要從業務層面檢測連接配接的斷開并重新發起連接配接。
不支援轉發逾時時間的調整:
目前配置: tcp 900s,udp 300s,http 60s,https 60s
上述配置是指 slb 服務端從後端接收資料并進行轉發的逾時時間,并非健康檢查逾時時間間隔。如果逾時,通常會向用戶端傳回 504 錯誤碼。
金融雲 slb 基于安全性考慮,僅允許開放特定的端口:80,443,2800-3300,6000-10000,13000-14000
從曆史案例看,使用者在 slb 的規劃和使用過程中有很多常見誤區。接下來逐一說明。
使用者在 slb 後端隻添加一台伺服器時,雖然鍊路能跑通,用戶端也能正常通路。但卻失去了 slb 消除 ecs 單點的基本能力。如果這台僅有的 ecs 出現異常,那邊整個業務通路也會出現異常。
建議:至少在 slb 後端加入兩台以上 ecs。以便單一伺服器出現異常時,業務還能持續正常通路。
使用者通過 slb 通路業務出現異常。但 hosts 綁定後端 ecs 的公網 ip 能正常通路。使用者據此推斷後端業務是正常的,是 slb 服務端出現異常導緻業務通路異常。
其實,由于負載均衡的資料轉發和健康檢查都是通過内網進行的。是以,從後端 ecs 的公網 ip 進行對比通路測試,并沒有可比性,并不能反應真實通路情況。
建議:出現異常時,在後端 ecs 之間,通過内網 ip 做對比通路測試。
使用者通過 ping slb 的 vip 位址來判斷 slb 服務的有效性。
其實,這種測試非常不可靠。因為 ping 響應是由 slb 服務端直接完成的,與後端 ecs 無關。是以,正常情況下:
隻要配置了任意監聽,即便相應監聽處于異常狀态,slb vip ping 也是正常的。
相反,如果 slb 沒有配置任何監聽,其 vip 是 ping 不通的。
建議:對于 4 層服務,通過 telnet 監聽端口進行業務可用性測試;對于 7 層服務,通過實際的業務通路進行可用性測試。
使用者回報已經調大了健康檢查的最大間隔時間,但用戶端訪還是由于通路逾時收到 504 錯誤。
其實,雖然健康檢查及業務轉發都是由 slb 服務端相同的伺服器承載,但卻是完全不同次元的處理邏輯。來自用戶端的請求,經由 slb 轉發給後端 ecs 後,slb 服務端會有接收資料的逾時視窗。而另一方面,slb 服務端持續的對後端 ecs 根據檢查間隔配置進行健康檢查。這兩者之間沒有直接關系,唯一的影響是在後端 ecs 健康檢查失敗後,slb 不會再對其進行資料轉發。
建議:用戶端通路逾時時,結合業務與 slb 預設逾時時間進行比對分析;健康檢查逾時時,結合健康檢查與業務逾時時間進行比對分析。
使用者回報通過 slb 後端 ecs 的業務日志進行統計分析,發現健康檢查的間隔非常短,與之前在建立監聽時配置的健康檢查間隔時間不一緻。
使用者認為 slb 服務端使用上百台機器進行健康檢查,大量健康檢查請求會形成 ddos 攻擊,造成後端 ecs 性能降低。
實際上,無論何種模式的健康檢查,其規模均不足以達到類似于 ddos 攻擊的量級:slb 叢集會利用多台機器(假定為 m 個,個位數級别),對後端 ecs 的每個服務監聽端口 (假定為 n 個) ,按照配置的健康檢查間隔(假定為 o 秒,一般建議最少 2 秒)進行健康檢查。以 tcp 協定健康檢查為例,那麼每秒由健康檢查産生的 tcp 連接配接建立數為:<code>m*n/o</code>。
從該公式可以看出,m 和 n 都是固定的,而且值很小。是以,最終健康檢查帶來的每秒 tcp 并發請求數,主要取決于建立的監聽端口數量。是以,除非有巨量的監聽端口,否則由健康檢查産生的連接配接請求,根本無法達到 syn flood 的攻擊級别,實際對後端 ecs 的網絡壓力也極低。
使用者為了降低健康檢查對業務的影響,将檢查間隔時間設定得很長。
這樣配置會導緻當後端 ecs 出現異常時,負載均衡需要經過較長時間才能偵測到後端 ecs 出現不可用。尤其是當後端 ecs 間歇性不可用時,由于需要【連續多次】檢測失敗時才會移除異常 ecs。是以,檢查間隔過長,會導緻負載均衡叢集可能根本無法發現後端 ecs 不可用。
使用者在進行業務調整時,認為直接将伺服器從 slb 後端移除,或将其權重置零即可,兩者效果是一樣的。
其實,兩者有很大差別,相關操作對業務的影響也不一緻:
移除伺服器:已經建立的連接配接會一并中斷,建立連接配接也不會再轉發到該 ecs。
權重置零:已經建立的連接配接不會中斷,直至逾時或主動斷開。新連接配接不會轉到該 ecs。
建議:在業務調整或伺服器維護時,提前将相應伺服器的權重置零,直至連接配接持續衰減至零。操作完成後,再恢複權重配置,以降低對業務的影響。
slb 在建立監聽時可以指定帶寬峰值。但使用者通過單一用戶端進行測試時,發現始終無法達到該峰值。
由于 slb 是基于叢集方式部署和提供服務的。是以,所有前端請求會被均分到叢集内不同的 slb 伺服器上進行轉發。相應的,在監聽上設定的帶寬峰值也會被平分後設定到各伺服器。是以,單個連接配接下載下傳的流量上限公式為:
示例:
假設在控制台上設定的帶寬峰值為 10mb,那麼單個用戶端可下載下傳的最大流量為: <code>10/(4-1)≈3.33mb</code>
建議:建議在配置單個監聽的帶寬峰值時,根據實際的業務情況并結合上述實作方式設定一個較為合理的值,進而確定業務的正常對外服務不會受到影響和限制。
接下來,結合 slb 的産品特性與曆史案例,從多個次元闡述使用 slb 的最佳實踐。
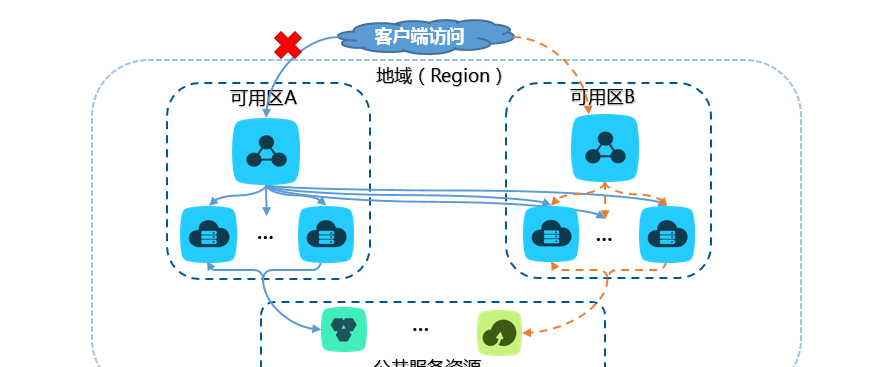
注:内網環境下,不支援多可用區,隻看圖例的單邊即可。
slb 在公網環境下的典型業務架構如上圖所示。基于多可用區特性,當主可用區出現異常時,slb 會自動将流量切換到備可用區。但在實際的業務架構設計過程中,建議關注如下要點:
執行個體類型與計費方式
如果隻用于内部服務分發,則建立私網執行個體即可。
按流量計費,适用于波峰波谷效應明顯的業務。
按帶寬計費,适用于帶寬較為平穩的業務。
區域與多可用區
為了降低延遲,建議選擇離您客戶最近的地域進行 slb 部署。
并非所有區域都支援多可用區特性(具體支援情況以您在控制台所見為準),請您結合業務情況選擇合适的可用區。
在配合使用多可用區特性時,後端 ecs 也必須同時在相應的主備可用區部署,才能保障出現異常時,相應可用區有 ecs 能進行業務承載。

如上圖所示,slb 支援建立多種協定監聽,然後按轉發政策,将前端業務請求轉發到後端多種邏輯伺服器集。在 slb 服務配置的各主要步驟中,請關注如下要點。
slb 支援建立 tcp/ucp/http/https 這 4 種協定的監聽。您可參考以下表格,根據業務情況選擇适合的協定建立監聽:
協定類型
建議的應用場景
特性
tcp
●注重可靠性,對資料準确性要求高,速度可以相對較慢的場景;
●示例:檔案傳輸、發送或接收郵件、遠端登入、無特殊要求的 web 應用
●面向連接配接的協定;
●在正式收發資料前,必須和對方建立可靠的連接配接;
●基于源位址會話保持,在網絡層可直接看到來源位址;
●監聽支援 tcp 和 http 兩種方式進行健康檢查;
●轉發路徑短,是以性能比 7 層更好,資料傳輸速度更快
http
需要對資料内容進行識别的應用,如 web 應用、小的手機遊戲等
●應用層協定,主要解決如何包裝資料;
●基于 cookie 會話保持;使用 x-forward-for 擷取源位址;
●監聽隻支援 http 方式健康檢查
https
有更高的安全性需求,需要加密傳輸的應用
●加密傳輸資料,可以阻止未經授權的通路;
●統一的證書管理服務,使用者可以将證書上傳到負載均衡,解密操作直接在負載均衡上完成
udp
●關注實時性而相對不注重可靠性的場景;
●示例:視訊聊天、金融實時行情推送
●面向非連接配接的協定;
●在資料發送前不與對方進行三次握手,直接進行資料包發送,不提供差錯恢複和資料重傳;
●可靠性相對低;資料傳輸快
補充說明
并非隻要 web 網站就必須使用 http 協定。大部分沒有特殊 http 要求的 web 網站,使用 tcp 監聽 80 端口就可以滿足業務需求。
slb 叢集采用 lvs 和 tengine 實作。其中 4 層監聽(tcp/udp)經過 lvs 後直接到達後端伺服器,而 7 層監聽(http/https)經過 lvs 後,還需要再經過 tengine 轉發,最後達到後端伺服器,由于比 4 層多了一個處理環節。是以,7 層監聽的性能相對要差一些。
slb 後端伺服器支援按 3 種邏輯建立伺服器集。要點如下:
集合模式
配置權重
指定服務端口
伺服器數量限制
其它特性
後端伺服器
支援
不支援
無限制
建立監聽時的預設映射伺服器集
虛拟伺服器組
有更大的靈活性
主備伺服器組
2 台
隻能在 tcp/udp 監聽上使用
建議
按業務邏輯建立不同的虛拟伺服器組,然後建立相應的監聽與之對應。
無論建立何種伺服器集合,均結合 slb 多可用區特性,同時加入位于不同可用區的伺服器,以實作跨可用區容災。
設定過多轉發規則會增加業務維護的複雜度,建議盡量精簡政策條目。
權重代表相應伺服器所承載的業務的相對占比,而非絕對值。目前 slb 支援 3 種轉發政策,其使用場景及要點如下:
轉發政策
算法說明
使用要點
權重輪詢(wrr)
按比重輪流配置設定新增連接配接。
●根據後端 ecs 規格的不同,配置相應的權重。
●如果是長連接配接業務,可能會導緻老伺服器的連接配接數持續增加, 而新加入伺服器的連接配接數相對非常低,造成負載不均的假象。
權重最小連接配接數(wlc)
●在 slb 服務端,實時統計與後端 ecs 已建立的 established 狀态連接配接數,來評估相應伺服器的負載情況。
●按權重比例,将新增連接配接配置設定給活動連接配接數少的伺服器,最終盡可能使伺服器的已建立連接配接數與其權重成正例。
目前暫未實作新增伺服器的過載保護或緩沖機制。是以,如果業務并發非常高,可能會導緻新增伺服器連接配接數陡增,對業務造成影響。建議新增伺服器時,逐漸調高權重。
輪詢(rr)
按順序逐一分發新增連接配接。
必須手工確定後端 ecs 的業務承載能力一緻。
示例:假設有 100 個新增連接配接,則在不同的排程算法下,不同伺服器的配置設定連接配接數示意如下:
伺服器
權重
占比
權重輪詢
權重最小連接配接數
輪詢
a
50
50/
(100+50+50)
=25%
将 100*25%=25 個連接配接分發給伺服器 a
實時統計連接配接數,逐一将新增連接配接配置設定給活動連接配接數最少的伺服器。最終使其新增連接配接數占比大緻為 25%
不考慮權重,按順序分發新增連接配接到伺服器 a/b/c
b
100
100/
=50%
将 100*50%=50 個連接配接分發給伺服器 b
↑ 同上,最終使其新增連接配接數占比大緻為 50%
↑ 同上
c
(100+50+50)=
25%
将 100*25%=25 個連接配接分發給伺服器 c
↑ 同上,最終使其新增連接配接數占比大緻為 25%
d
0/
=0%
伺服器下線,不配置設定任何連接配接
← 同左
健康檢查用于實時探測後端 ecs 上的業務可用性,以避免新增連接配接被分發到異常伺服器對業務造成影響。由于是 slb 依賴的核心服務,是以 4 層協定(tcp/ucp)的健康檢查無法關閉。
在配置健康檢查時,注意如下要點:
根據業務情況合理選擇 tcp 或 http 模式健康檢查
tcp 模式健康檢查隻能檢查端口的可用性,對 7 層 http 狀态無法感覺。是以,web 類 7 層業務建議配置 http 模式健康檢查。
如果使用 http 健康檢查模式,建議合理調整後端日志配置,避免健康檢查 head 請求過多對 io 性能造成影響。
合理配置健康檢查間隔
合理配置檢查端口與檢查 url
對于 4 層 tcp 協定,由于虛拟伺服器組可以由後端 ecs 不同的端口承載業務,是以在配置健康檢查時不要設定檢查端口,而應該"預設使用後端伺服器的端口進行健康檢查"。否則可能導緻後端 ecs 健康檢查失敗。
對于 7 層 http 協定,使用虛拟伺服器組合轉發政策時,確定健康檢查配置政策中的 url 在後端每台機器上都可以通路成功。
使用 http 模式健康檢查時,不要對根目錄進行檢查。建議配置為對某個靜态頁面或檔案進行檢查以降低對首頁的沖擊。但是,相應的,這可能會導緻誤判:健康檢查 url 雖然通路是正常的,但首頁實際上已經出現異常。
udp 健康檢查
目前 udp 協定健康檢查可能存在服務真實狀态與健康檢查不一緻的問題:
如果後端 ecs 伺服器是 linux 伺服器,在大并發場景下,由于 linux 的防 icmp 攻擊保護機制,會限制伺服器發送 icmp 的速度。此時,即便服務已經出現異常,但由于無法向前端傳回 “port xx unreachable” 報錯資訊,會導緻負載均衡由于沒收到 icmp 應答進而判定健康檢查成功,最終導緻服務真實狀态與健康檢查不一緻。
如果相應伺服器非正常關機,由于也不會傳回 “port xx unreachable” 報錯資訊。是以也會導緻健康檢查處于"正常"狀态的誤報。
在後端 ecs 的選擇與配置時,注意如下要點:
在同一個伺服器集中,同時加入不同可用區的伺服器,以實作同城容災
根據伺服器規格的差異,配置與之成正比的權重
slb 後端最少配置兩台以上 ecs,以避免單台 ecs 出現異常導緻整個業務也出現異常
後端 ecs 建議無狀态部署:即隻用于計算,而資料調用與存儲後連至後端的 oss、rds 等公共服務。這樣可以無需為 ecs 之間的資料同步問題而困擾。
建議基于相同的鏡像或自定義鏡像建立後端 ecs 伺服器,以保障配置的一緻性。
後端 ecs 歸屬安全組及系統内部防火牆必須對 slb 服務端位址段進行通路放行。
在往 slb 内新增伺服器時,注意如下要點:
建議新增伺服器時,将權重置零,在確定業務正常運作後,再調整權重使其上線。
如果業務是長連接配接,在新增伺服器時,建議先将相應監聽的排程算法修改為輪詢模式,然後逐漸調高新增伺服器的權重,以降低對該新增伺服器的過高沖擊。
在後端 ecs 伺服器的日常調整、維護過程中,注意如下要點:
選擇合适的業務視窗,定期對後端 ecs 進行重新開機操作(操作前先建立快照進行備份),以便應用系統更新檔,并主動觸發、感覺系統内部錯誤導緻的伺服器無法正常啟動等問題。
業務更新或系統維護時建議的操作步驟:
如果确認伺服器不再使用,不建議直接移除伺服器。而是參閱前述步驟,将相應伺服器權重置零。待已建立連接配接全部正常斷開後,再移除該伺服器。
slb 在使用過程中的常見問題與排查思路可以參閱下列文檔,本文不再詳述:
<a href="https://help.aliyun.com/document_detail/27702.html">健康檢查異常的排查思路</a>
<a href="https://help.aliyun.com/knowledge_detail/39481.html">負載均衡傳回 http 500/502/504 錯誤的處理</a>
<a href="https://help.aliyun.com/knowledge_detail/39491.html">後端 ecs 負載不均衡問題的處理</a>
問題場景:
後端 ecs 規格均一緻,但其中幾台伺服器的 pps 一直非常高。而新加入的伺服器,相對負載非常低。
業務高峰期,相關伺服器健康檢查異常,導緻伺服器下線,并進一步導緻其它伺服器負載升高,引發整個 slb 後端出現雪崩式異常,業務受到嚴重影響。
排查思路:
業務監聽使用 wrr 排程算法,在 slb 服務端統計,在機關時間内分發到各伺服器的連接配接數是均衡的。
異常伺服器上的連接配接數持續居高不下,嘗試調高 os 層面的 tcp 連接配接數限制等配置,無明顯效果。
和客戶交流,結合業務分析,相關連接配接來源正常,都是正常的業務連接配接。但業務場景是物聯網的監控資料上報,使用的是長連接配接。是以除非主動斷開相關連接配接,否則相關連接配接會持續堆積。
應對措施:
将負載較低的伺服器的權重值調低。
将監聽的排程算法修改為 wlc。
将異常伺服器的權重值置零。
将負責較低的伺服器的權重值逐漸調高。
以上步驟用于将負載逐漸轉移到新加入的伺服器,并避免對新增伺服器及異常伺服器的沖擊。
待異常伺服器的連接配接數下降到合理水準後,将其重新上線(重新配置權重)。
由于後端伺服器負載總體偏高,導緻業務高峰期多台伺服器無法滿足業務需求,出現雪崩式異常。是以,同步建議客戶對 slb 後端伺服器進行擴容。