github 地址:https://github.com/nltk/nltk/
官方地址:http://www.nltk.org/
中文文档:http://download.csdn.net/detail/u013378306/9756747
安装及测试
install nltk: run <code>sudo pip install -u nltk</code>
install numpy (optional): run <code>sudo pip install -u numpy</code>
test installation: run <code>python</code> then type <code>import nltk</code>
python nltk库中包含着大量的语料库,但是大部分都是英文,不过有一个sinica(中央研究院)提供的繁体中文语料库,值得我们注意。
在使用这个语料库之前,我们首先要检查一下是否已经安装了这个语料库。
下载数据文件
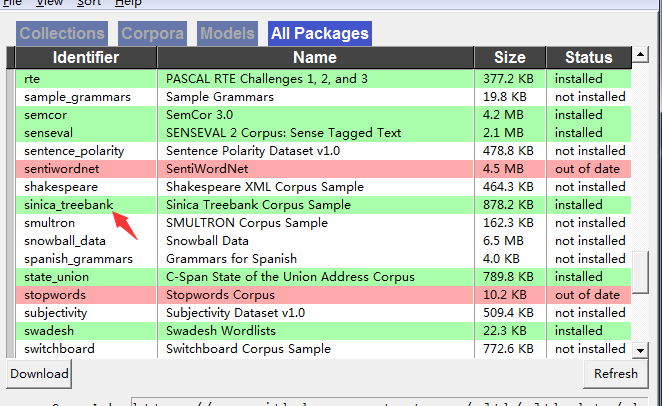
总的数据有300m左右,下载很慢,
提供下载地址:https://pan.baidu.com/s/1nvfr485
nltk 数据文件结构
数据文件存放地址(linux下的搜索路径)
主要功能

使用
结果:['一', '友情', '嘉珍', '和', '我', '住在', '同一條', '巷子', '我們', ...]
(1)来看一下nltk中文语法树。
>>>sinica_treebank.parsed_sents()[33].draw()
python 万岁!!!
(2)搜索中文文本
1
2
3
4
5
<code>import</code> <code>nltk</code>
<code>from</code> <code>nltk.corpus </code><code>import</code> <code>sinica_treebank</code>
<code>sinica_text</code><code>=</code><code>nltk.text(sinica_treebank.words())</code>
<code>print</code><code>(sinica_text.concordance(</code><code>'我'</code><code>))</code>
结果: