在前面几期关于 innodb redo 和 undo 实现的铺垫后,本节我们从上层的角度来阐述 innodb 的事务子系统是如何实现的,涉及的内容包括:innodb的事务相关模块、如何实现mvcc及acid、如何进行事务的并发控制、事务系统如何进行管理等相关知识。本文的目的是让读者对事务系统有一个较全面的理解。
由于不同版本对事务系统都有改变,本文的所有分析基于当前ga的最新版本mysql5.7.9,但也会在阐述的过程中,顺带描述之前版本的一些内容。本文也会介绍5.7版本对事务系统的一些优化点。
另外尽管 innodb 锁系统和事务有着非常密切的联系,但鉴于本文主要介绍事务模块,并且计划中的篇幅已经足够长。而锁系统又是一个非常复杂的模块,将在后面的月报中单独开一篇文章来讲述。
在阅读本文之前,强烈建议先阅读下之前两节的内容,因为事务系统和这些模块有着非常紧密的联系:
<a href="http://mysql.taobao.org/monthly/2015/04/01/" target="_blank">mysql · 引擎特性 · innodb undo log 漫游</a>
<a href="http://mysql.taobao.org/monthly/2015/05/01/" target="_blank">mysql · 引擎特性 · innodb redo log漫游</a>
<a href="http://mysql.taobao.org/monthly/2015/06/01/" target="_blank">mysql · 引擎特性 · innodb 崩溃恢复过程</a>
innodb 提供了多种方式来开启一个事务,最简单的就是以一条 begin 语句开始,也可以以 start transaction 开启事务,你还可以选择开启一个只读事务还是读写事务。所有显式开启事务的行为都会隐式的将上一条事务提交掉。
所有显示开启事务的入口函数均为<code>trans_begin</code>,如下列出了几种常用的事务开启方式。
当以begin开启一个事务时,首先会去检查是否有活跃的事务还未提交,如果没有提交,则调用<code>ha_commit_trans</code>提交之前的事务,并释放之前事务持有的mdl锁。
执行begin命令并不会真的去引擎层开启一个事务,仅仅是为当前线程设定标记,表示为显式开启的事务。
和begin等效的命令还有“begin work”及“start transaction”。
使用该选项开启一个只读事务,当以这种形式开启事务时,会为当前线程的<code>thd->tx_read_only</code>设置为true。当server层接受到任何数据更改的sql时,都会直接拒绝请求,返回错误码<code>er_cant_execute_in_read_only_transaction</code>,不会进入引擎层。
这个选项可以强约束一个事务为只读的,而只读事务在引擎层可以走优化过的逻辑,相比读写事务的开销更小,例如不用分配事务id、不用分配回滚段、不用维护到全局事务链表中。
该事务开启的方式从5.6版本开始引入。我们知道,在mysql5.6版本中引入的一个对事务模块的重要优化:将全局事务链表拆成了两个链表:一个用于维护只读事务,一个用于维护读写事务。这样我们在构建一个一致性视图时,只需要遍历读写事务链表即可。但是在5.6版本中,innodb并不具备事务从只读模式自动转换成读写事务的能力,因此需要用户显式的使用以下两种方式来开启只读事务:
执行start transaction read only
或者将变量<code>tx_read_only</code>设置为true
5.7版本引入了模式自动转换的功能,但该语法依然保留了。
另外一个有趣的点是,在5.7版本中,你可以通过设置<code>session_track_transaction_info</code>变量来跟踪事务的状态,这货主要用于官方的分布式套件(例如fabric),例如在一个负载均衡系统中,你需要知道哪些 statement 开启或处于一个事务中,哪些 statement 允许连接分配器调度到另外一个 connection。只读事务是一种特殊的事务状态,因此也需要记录到线程的<code>transaction_state_tracker</code>中。
和上述相反,该sql用于开启读写事务,这也是默认的事务模式。但有一点不同的是,如果当前实例的 read_only 打开了且当前连接不是超级账户,则显示开启读写事务会报错。
同样的事务状态<code>tx_read_write</code>也要加入到session tracker中。另外包括上述几种显式开启的事务,其标记<code>tx_explicit</code>也加入到session tracker中。
读写事务并不意味着一定在引擎层就被认定为读写事务了,5.7版本innodb里总是默认一个事务开启时的状态为只读的。举个简单的例子,如果你事务的第一条sql是只读查询,那么在innodb层,它的事务状态就是只读的,如果第二条sql是更新操作,就将事务转换成读写模式。
和上面几种方式不同的是,在开启事务时还会顺便创建一个视图(read view),在innodb中,视图用于描述一个事务的可见性范围,也是多版本特性的重要组成部分。
这里会进入innodb层,调用函数<code>innobase_start_trx_and_assign_read_view</code>,注意只有你的隔离级别设置成repeatable read(可重复读)时,才会显式开启一个read view,否则会抛出一个warning。
使用这种方式开启事务时,事务状态已经被设置成active的。
状态变量<code>tx_with_snapshot</code>会加入到session tracker中。
当autocommit设置成0时,就无需显式开启事务,如果你执行多条sql但不显式的调用commit(或者执行会引起隐式提交的sql)进行提交,事务将一直存在。通常我们不建议将该变量设置成0,因为很容易由于程序逻辑或使用习惯造成事务长时间不提交。而事务长时间不提交,在mysql里简直就是噩梦,各种诡异的问题都会纷纷出现。一种典型的场景就是,你开启了一条查询,但由于未提交,导致后续对该表的ddl堵塞住,进而导致随后的所有sql全部堵塞,简直就是灾难性的后果。
另外一种情况是,如果你长时间不提交一个已经构建read view的事务,purge线程就无法清理一些已经提交的事务锁产生的undo日志,进而导致undo空间膨胀,具体的表现为ibdata文件疯狂膨胀。我们曾在线上观察到好几百g的ibdata文件。
tips:所幸的是从5.7版本开始提供了可以在线truncate undo log的功能,前提是开启了独立的undo表空间,并保留了足够的 undo 回滚段配置(默认128个),至少需要35个回滚段。其truncate 原理也比较简单:当purge线程发现一个undo文件超过某个定义的阀值时,如果没有活跃事务引用这个undo文件,就将其设置成不可分配,并直接物理truncate文件。
事务的提交分为两种方式,一种是隐式提交,一种是显式提交。
当你显式开启一个新的事务,或者执行一条非临时表的ddl语句时,就会隐式的将上一个事务提交掉。另外一种就是显式的执行“commit” 语句来提交事务。
然而,在不同的场景下,mysql在提交时进行的动作并不相同,这主要是因为 mysql 是一种服务器层-引擎层的架构,并存在两套日志系统:binary log及引擎事务日志。mysql支持两种xa事务方式:隐式xa和显式xa;当然如果关闭binlog,并且仅使用一种事务引擎,就没有xa可言了。
关于隐式xa的控制对象,在实例启动时决定使用何种xa模式,如下代码段:
若打开binlog,且使用了事务引擎,则xa控制对象为<code>mysql_bin_log</code>;
若关闭了binlog,且存在不止一种事务引擎时,则xa控制对象为<code>tc_log_mmap</code>;
其他情况,使用<code>tc_log_dummy</code>,这种场景下就没有什么xa可言了,无需任何协调者来进行xa。
这三者是<code>tc_log</code>的子类,关系如下图所示:
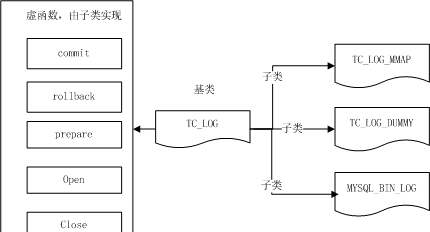
tc log
具体的,包含以下几种类型的xa(不对数据产生变更的只读事务无需走xa)
当开启binlog时, mysql默认使用该隐式xa模式。 在5.7版本中,事务的提交流程包括:
binlog prepare
设置<code>thd->durability_property= ha_ignore_durability</code>, 表示在innodb prepare时,不刷redo log。
innodb prepare (入口函数<code>innobase_xa_prepare --> trx_prepare</code>):
更新innodb的undo回滚段,将其设置为prepare状态(<code>trx_undo_prepared</code>)。
进入组提交 (<code>ordered_commit</code>)
flush stage:此时形成一组队列,由leader依次为别的线程写binlog文件
sync stage:如果<code>sync_binlog</code>计数超过配置值,则进行一次文件fsync,注意,参数<code>sync_binlog</code>的含义不是指的这么多个事务之后做一次fsync,而是这么多组事务队列后做一次fsync。
semisync stage (rds mysql only):如果我们在事务commit之前等待备库ack(设置成after_sync模式),用户线程会释放上一个stage的锁,并等待ack。这意味着在等待ack的过程中,我们并不堵塞上一个stage的binlog写入,可以增加一定的吞吐量。
tips:如果你关闭了<code>binlog_order_commits</code>选项,那么事务就各自进行提交,这种情况下不能保证innodb commit顺序和binlog写入顺序一致,这不会影响到数据一致性,在高并发场景下还能提升一定的吞吐量。但可能影响到物理备份的数据一致性,例如使用 xtrabackup(而不是基于其上的innobackup脚本)依赖于事务页上记录的binlog位点,如果位点发生乱序,就会导致备份的数据不一致。
当binlog关闭时,如果事务跨引擎了,就可以在事务引擎间进行xa了,典型的例如innodb和tokudb(在rds mysql里已同时支持这两种事务引擎)。当支持超过1种事务引擎时,并且binlog关闭了,就走tc log mmap逻辑。对应的xa控制对象为<code>tc_log_mmap</code>。
由于需要持久化事务信息以用于重启恢复,因此在该场景下,<code>tc_log_mmap</code>模块会创建一个文件,名为tc.log,文件初始化大小为24kb,使用mmap的方式映射到内存中。
tc.log 以page来进行划分,每个page大小为8k,至少需要3个page,初始化的文件大小也为3个page(<code>tc_log_min_size</code>),每个page对应的结构体对象为st_page,因此需要根据page数,完成文件对应的内存控制对象的初始化。初始化第一个page的header,写入magic number以及当前的2pc引擎数(也就是<code>total_ha_2pc</code>)
下图描述了tc.log的文件结构:

tc.log 文件结构
在事务执行的过程中,例如遇到第一条数据变更sql时,会注册一个唯一标识的xid(实际上通过当前查询的query_id来唯一标识),之后直到事务提交,这个xid都不会改变。事务引擎本身在使用undo时,必须加上这个xid标识。
在进行事务prepare阶段,若事务涉及到多个引擎,先在各自引擎里做事务prepare。
然后进入commit阶段,这时候会将xid记录到tc.log中(如上图所示),这类涉及到相对复杂的page选择流程,这里不展开描述,具体的参阅函数<code>tc_log_mmap::commit</code>
在完成记录到tc.log后,就到引擎层各自提交事务。这样即使在引擎提交时失败,我们也可以在crash recovery时,通过读取tc.log记录的xid,指导引擎层将符合xid的事务进行提交。
当关闭binlog时,且事务只使用了一个事务引擎时,就无需进行xa了,相应的事务commit的流程也有所不同。
首先事务无需进入prepare状态,因为对单引擎事务做xa没有任何意义。
其次,因为没有prepare状态的保护,事务在commit时需要对事务日志进行持久化。这样才能保证所有成功返回的事务变更, 能够在崩溃恢复时全部完成。
mysql支持显式的开启一个带命名的xa事务,例如:
一个有趣的问题是,在5.7之前的版本中,如果执行xa的过程中,在完成xa prepare后,如果kill掉session,事务就丢失了,而不是像崩溃恢复那样,可以直接恢复出来。这主要是因为mysql对kill session的行为处理是直接回滚事务。
为了解决这个问题,mysql5.7版本做了不小的改动,将xa的两阶段都记录到了binlog中。这样状态是持久化了的,一次干净的shutdown后,可以通过扫描binlog恢复出xa事务的状态,对于kill session导致的xa事务丢失,逻辑则比较简单:内存中使用一个transaction_cache维护了所有的xa事务,在断开连接调用thd::cleanup时不做回滚,仅设置事务标记即可。
当由于各种原因(例如死锁,或者显式rollback)需要将事务回滚时,会调用handler接口<code>ha_rollback_low</code>,进而调用innodb函数<code>trx_rollback_for_mysql</code>来回滚事务。回滚的方式是提取undo日志,做逆向操作。
由于innodb的undo是单独写在表空间中的,本质上和普通的数据页是一样的。如果在事务回滚时,undo页已经被从内存淘汰,回滚操作(特别是大事务变更回滚)就可能伴随大量的磁盘io。因此innodb的回滚效率非常低。有的数据库管理系统,例如postgresql,通过在数据页上冗余数据产生版本链的方式来实现多版本,因此回滚起来非常方便,只需要设置标记即可,但额外带来的问题就是无效数据清理开销。
在事务执行的过程中,你可以通过设置savepoint的方式来管理事务的执行过程。
在介绍savepoint之前,需要先介绍下<code>trx_t::undo_no</code>。在事务每次成功写入一次undo后,这个计数都会递增一次(参阅函数<code>trx_undo_report_row_operation</code>)。事务的<code>undo_no</code>也会记录到undo page中进行持久化,因此在undo链表上的<code>undo_no</code>总是有序递增的。
总的来说,主要有以下几种操作类型。
设置savepoint
语法:savepoint sp_name
入口函数:<code>trans_savepoint</code>
在事务中设置一个savepoint,你可以随意命名一个名字,在事务中设置的所有 savepoint 实际上维护了两份链表,一份挂在thd变量上(<code>thd->get_transaction()->m_savepoints</code>),包含了基本的savepoint信息及到引擎层的映射,另一份在引擎层的事务对象上(维持在链表<code>trx_t::trx_savepoints</code>中)。
如下图所示:
savepoint 链表
总共分为以下几步:
在增加新的savepoint时,总是先判断下是否同名的savepoint已经存在,如果存在,就用后者替换前者;
server层维护的savepoint信息记录了命名信息及mdl锁的savepoint点。其中mdl锁的savepoint,可以实现回滚操作时释放该savepoint之后再获得的mdl锁;
在当前线程的binlog cache中写入设置savepoint的sql, 并保存binlog cache中的位点 (<code>binlog_savepoint_set</code>);
引擎层的savepoint中记录了最近一次的<code>trx_t::undo_no</code>及savepoint名字。通过这些信息可以准确的定位在设置savepoint点时undo位点。(参阅引擎层入口函数:<code>trx_savepoint_for_mysql</code>)。
回滚savepoint
语法:rollback to [ savepoint ] sp_name
入口函数:<code>trans_rollback_to_savepoint</code>
检查点的回滚主要包括:
如果事务是一个xa事务,且已经处于xa prepare状态时是不允许回滚到某个savepoint的;
如果涉及非事务引擎,在binlog中写入回滚sql,否则直接将binlog cache truncate到之前设置sp时保存的位点。(<code>binlog_savepoint_rollback</code>)
在引擎层进行回滚(<code>trx_rollback_to_savepoint_for_mysql</code>)
根据之前记录的undo_no,可以逆向操作当前事务占用的undo slot上的undo记录来进行回滚。
判断是否允许回滚mdl锁:
binlog关闭的情况下,总是允许回滚mdl锁
或者由引擎来确认(<code>ha_rollback_to_savepoint_can_release_mdl</code>),同时满足:
innodb:如果当前事务不持有任何事务锁(表级或者行级),则认为可以回滚mdl锁
binlog:如果没有更改非事务引擎,则可以释放mdl锁
如果允许回滚mdl,则通过之前记录的<code>st_savepoint::mdl_savepoint</code>进行回滚
释放savepoint
语法为:release savepoint sp_name
顾名思义,就是删除一个savepoint,操作也很简单,直接根据命名从server层和innodb层的清理掉,并释放对应的内存。
隐式savepoint
在innodb中,还有一种隐式的savepoint,通过变量<code>trx_t::last_sql_stat_start</code>来维护。
初始状态下<code>trx_t::last_sql_stat_start</code>的值为0,当执行完一条sql时,会调用函数<code>trx_mark_sql_stat_end</code>将当前的<code>trx_t::undo_no</code>保存到<code>trx_t::last_sql_stat_start</code>中。
如果sql执行失败,就可以据此进行statement级别的回滚操作(<code>trx_rollback_last_sql_stat_for_mysql</code>)。
无论是显式savepoint还是隐式savepoint,都是通过undo_no来指示回滚到哪个事务状态。
两个有趣的bug
<a href="http://bugs.mysql.com/bug.php?id=79493" target="_blank">bug#79493</a>
在一个只读事务中,如果设置了savepoint,任意执行一次<code>rollback to savepoint</code>都会将事务从只读模式改变成读写模式。这主要是因为在活跃事务中执行rollback 操作会强制转换read-write模式。实际上这是没必要的,因为并没有造成任何的数据变更。
<a href="http://bugs.mysql.com/bug.php?id=79596" target="_blank">bug#79596</a>
这个bug可以认为是一个相当严重的bug:在一个活跃的做过数据变更操作的事务中,任意执行一次rollback to savepoint(即使savepoint不存在),然后kill掉客户端,会发现事务却提交了,并且没有写到binlog中。这会导致主备的数据不一致。
重现步骤如下:
最后一步直接对session的进程kill -9时会导致事务commit。这主要是因为如果直接kill客户端,服务器端在清理线程资源,进行事务回滚时,相关的变量并没有被重设,thd的command类型还是<code>sqlcom_rollback_to_savepoint</code>,在函数<code>mysql_bin_log::rollback</code>函数中将不会调用<code>ha_rollback_low</code>的引擎层回滚逻辑。原因是回滚到某个savepoint有特殊的处理流程,如果是通过ctrl+c的方式关闭client端,实际上会发送一个类型为<code>com_quit</code>的command,它会将<code>thd->lex->sql_command</code>设置为<code>sqlcom_end</code>,这时候会走正常的回滚逻辑。
在事务执行的过程中,需要多个模块来辅助事务的正常执行:
server层的mdl锁模块,维持了一个事务过程中所有涉及到的表级锁对象。通过mdl锁,可以堵塞ddl,避免ddl和dml记录binlog乱序;
innodb的trx_sys子系统,维持了所有的事务状态,包括活跃事务、非活跃事务对象、读写事务链表、负责分配事务id、回滚段、readview等信息,是事务系统的总控模块;
innodb的lock_sys子系统,维护事务锁信息,用于对修改数据操作做并发控制,保证了在一个事务中被修改的记录,不可以被另外一个事务修改;
innodb的log_sys子系统,负责事务redo日志管理模块;
innodb的purge_sys子系统,则主要用于在事务提交后,进行垃圾回收,以及数据页的无效数据清理。
总的来说,事务管理模块的架构图,如下图所示:
innodb 事务管理
下面就几个事务模块的关键点展开描述。
在innodb中一直维持了一个不断递增的整数,存储在<code>trx_sys->max_trx_id</code>中;每次开启一个新的读写事务时,都将该id分配给事务,同时递增全局计数。事务id可以看做一个事务的唯一标识。
在mysql5.6及之前的版本中,总是为事务分配id。但实际上这是没有必要的,毕竟只有做过数据更改的读写事务,我们才需要去根据事务id判断可见性。因此在mysql5.7版本中,只有读写事务才会分配事务id,只读事务的id默认为0。
那么问题来了,怎么去区分不同的只读事务呢?这里在需要输出事务id时(例如执行<code>show engine innodb status</code> 或者查询information_schema.innodb_trx表),使用只读事务对象的指针或上一个常量来标识其唯一性,具体的计算方式见函数<code>trx_get_id_for_print</code>。所以如果你show出来的事务id看起来数字特别庞大,千万不要惊讶。
对于全局最大事务id,每做256次赋值(<code>trx_sys_trx_id_write_margin</code>)就持久化一次到ibdata的事务页(<code>trx_sys_page_no</code>)中。
已分配的事务id会加入到全局读写事务id集合中(<code>trx_sys->rw_trx_ids</code>),事务id和事务对象的map加入到<code>trx_sys->rw_trx_set</code>中,这是个有序的集合(<code>std::set</code>),可以用于通过trx id快速定位到对应的事务对象。
事务分配得到的id并不是立刻就被使用了,而是在做了数据修改时,需要创建或重用一个undo slot时,会将当前事务的id写入到undo page头,状态为<code>trx_undo_active</code>。这也是崩溃恢复时,innodb判断是否有未完成事务的重要依据。
在执行数据更改的过程中,如果我们更新的是聚集索引记录,事务id + 回滚段指针会被写到聚集索引记录中,其他会话可以据此来判断可见性以及是否要回溯undo链。
对于普通的二级索引页更新,则采用回溯聚集索引页的方式来判断可见性(如果需要的话)。关于mvcc,后文会有单独描述。
事务子系统维护了三个不同的链表,用来管理事务对象。
trx_sys->mysql_trx_list
包含了所有用户线程的事务对象,即使是未开启的事务对象,只要还没被回收到trx_pool中,都被放在该链表上。当session断开时,事务对象从链表上摘取,并被回收到trx_pool中,以待重用。
trx_sys->rw_trx_list
读写事务链表,当开启一个读写事务,或者事务模式转换成读写模式时,会将当前事务加入到读写事务链表中,链表上的事务是按照<code>trx_t::id</code>有序的;在事务提交阶段将其从读写事务链表上移除。
trx_sys->serialisation_list
序列化事务链表,在事务提交阶段,需要先将事务的undo状态设置为完成,在这之前,获得一个全局序列号<code>trx->no</code>,从<code>trx_sys->max_trx_id</code>中分配,并将当前事务加入到该链表中。随后更新undo等一系列操作后,因此进入提交阶段的事务并不是trx->id有序的,而是根据trx->no排序。当完成undo更新等操作后,再将事务对象同时从<code>serialisation_list</code>和<code>rw_trx_list</code>上移除。
这里需要说明下<code>trx_t::no</code>,这是个不太好理清的概念,从代码逻辑来看,在创建readview时,会用到序列化链表,链表的第一个元素具有最小的<code>trx_t::no</code>,会赋值给<code>readview::m_low_limit_no</code>。purge线程据此创建的readview,只有小于该值的undo,才可以被purge掉。
总的来说,<code>mysql_trx_list</code>包含了<code>rw_trx_list</code>上的事务对象,<code>rw_trx_list</code>包含了<code>serialisation_list</code>上的事务对象。
事务id集合有两个:
trx_sys->rw_trx_ids
记录了当前活跃的读写事务id集合,主要用于构建readview时快速拷贝一个快照
trx_sys->rw_trx_set
这是<trx_id, trx_t>的映射集合,根据trx_id排序,用于通过trx_id快速获得对应的事务对象。一个主要的用途就是用于隐式锁转换,需要为记录中的事务id所对应的事务对象创建记录锁,通过该集合可以快速获得事务对象
对于普通的读写事务,总是为其指定一个回滚段(默认128个回滚段)。而对于只读事务,如果使用到了innodb临时表,则为其分配(1~32)号回滚段。(回滚段指定参阅函数<code>trx_assign_rseg_low</code>)
当为事务指定了回滚段后,后续在事务需要写undo页时,就从该回滚段上分别分配两个slot,一个用于<code>update_undo</code>,一个用于<code>insert_undo</code>。分别处理的原因是事务提交后,update_undo需要purge线程来进行回收,而insert_undo则可以直接被重利用。
在介绍事务引用计数之前,我们首先要了解下什么是隐式锁。所谓隐式锁,其实并不是一个真正的事务锁对象,可以理解为一个标记:对于聚集索引页的更新,记录本身天然带事务id,对于二级索引页,则在page上记录最近一次更新的最大事务id,通过回表的方式判断可见性。
由于事务锁涉及到全局资源,创建锁的开销高昂,innodb对于新插入的记录,在没有冲突的情况下是不创建记录锁的。举个例子,session 1插入一条记录,并保持未提交状态。另外一个session想更新这条记录,从数据页上读取到这条记录后,发现对应的事务id还处于活跃状态,根据当前的并发规则,这个更新需要被阻塞住。因此第二个session需要为session 1创建一条记录锁,然后将自己放入等待队列中。
在mysql5.7版本之前,隐式锁转换的逻辑为(函数<code>lock_rec_convert_impl_to_expl</code>)
首先判断记录对应的事务id是否还处于活跃状态
聚集索引: <code>lock_clust_rec_some_has_impl</code>
二级索引: <code>lock_sec_rec_some_has_impl</code>
如果不活跃,说明事务已提交,我们可以对这条记录做任何更改操作,直接返回;否则返回获取的trx_id
持有lock_sys->mutex;
持有trx_sys->mutex ,并获取当前记录中的事务id对应的内存事务对象trx_t;
为该事务创建一个锁对象,并加入到锁队列中;
释放lock_sys->mutex。
上述流程中长时间持有<code>lock_sys->mutex</code>,目的是防止在为其转换隐式锁为显式锁时事务被提交掉。尤其是在第三步,同时持有两把大锁去查找事务对象。在5.6官方版本中,这种查找操作还需要遍历链表,开销巨大,推高了临界资源的竞争。
因此在5.7中引入事务计数<code>trx_t::n_ref</code>来辅助判断,在隐式锁转换时,通过读写事务集合(<code>rw_trx_set</code>)快速获得事务对象,同时对<code>trx_t::n_def</code>递增。这个过程无需加<code>lock_sys->mutex</code>锁。随后再持有lock_sys->mutex去创建显式锁。在完成创建后,递减<code>trx_t::n_ref</code>。
为了防止为一个已提交的事务创建显式锁;在事务提交阶段也做了处理:在事务释放事务锁之前,如果引用计数非0,则表示有人正在做隐式锁转换,这里需要等待其完成。(参考函数<code>lock_trx_release_locks</code>)。
实际上上述修改是在官方优化读写事务链表之前完成的。由于在5.7里已经使用一个有序的集合保存了<code>trx_id</code>到<code>trx_t</code>的关联,可以非常快速的定位到事务对象,这个优化带来的性能提升已经没那么明显了。
关于隐式锁更详细的信息,我们将在之后专门讲述“事务锁”的月报中再单独描述。
在mysql5.7中,由于消除了大量临界资源的竞争,innodb只读查询的性能非常优化,几乎可以随着cpu线性扩展。但如果进入到读写混合的场景,就不可避免的使用到一些临界资源,例如事务、锁、日志等子系统。当竞争越激烈,就可能导致性能的下降。通常系统会有个吞吐量和响应时间最优的性能拐点。
innodb本身提供了并发控制机制,一种是语句级别的并发控制,另外一种是事务提交阶段的并发控制。
语句级别的并发通过参数<code>innodb_thread_concurrency</code>来控制,表示允许同时在innodb层活跃的并发sql数。
每条sql在进入innodb层进行操作之前都需要先递增全局计数,并为当前sql分配<code>innodb_concurrency_tickets</code>个ticket。也就是说,如果当前sql需要进出innodb层很多次(例如一个大查询需要扫描很多行数据时),<code>innodb_concurrency_tickets</code>次都可以自由进入innodb,无需判断<code>innodb_thread_concurrency</code>。当ticket用完时,就需要重新进入,当sql执行完成后,会将ticket重置为0。
如果当前innodb层的并发度已满,用户线程就需要等待,目前的实现使用sleep一段时间的方式,sleep的时间是自适应的,但你可以通过参数<code>innodb_adaptive_max_sleep_delay</code>来设置一个最大sleep事件,具体的算法参阅函数<code>srv_conc_enter_innodb_with_atomics</code>。
提到并发控制,另外一个不得不提的问题就是热点更新问题。事务在进入innodb层,准备更新一条数据,但发现行记录被其他线程锁住,这时候该线程会强制退出innodb并发控制,同时将自己suspend住,进入睡眠等待。如果有大量并发的更新同一条记录,就意味着大量线程进入innodb层,访问热点竞争资源锁系统,然后再退出。最终会呈现出大量线程在innodb中suspend住,相当于并发控制并没有达到降低临界资源争用的效果。早期我们对该问题的优化就是将线程从堵在innodb层,转移到堵在进入innodb层时的外部排队中,这样就不涉及到innodb的资源争用了。具体的实现是将statement级别的并发控制提升为事务级别的并发控制,因此这个方案的缺陷是对长事务不友好。
另外还有一些并发控制方案,例如线程池、水位限流、按pk排队等策略,我们的rds mysql也很早就支持了。如果你存在热点争用(例如秒杀场景),并且正在使用rds mysql,你可以去咨询售后如何使用这些特性。
除了语句级别的并发外,innodb也提供了提交阶段的并发控制,主要通过参数<code>innodb_commit_concurrency</code>来控制。该参数的默认值为0,表示不控制commit阶段的并发。在进入函数<code>innobase_commit</code>时,如果该参数被设置,且当前并发度超过,就需要等待。然而由于当前在默认配置下所有事务都走组提交(<code>ordered_commit</code>),innodb层的提交大多数情况下只会有一个活跃线程。你只有关闭binlog或者关闭参数<code>binlog_order_commits</code>,这个参数设置才有意义。
mysql5.7 实现了一种高优先级的事务调度方式。当事务处于高优先级模式时,它将永远不会被选作deadlock场景的牺牲者,拥有获得锁的最高优先级,并能kill掉阻塞它的的低优先级事务。这个特性主要是为了支持官方开发的group replication plugin套件,以保证事务总是能在所有的节点上提交。
如何使用
目前ga版本还没有提供公共接口来使用该功能,但代码实现都是完备的,如果想使用该功能,直接写一个设置变量的接口即可,非常简单。在server层,每个thd上新增了两个变量来标识事务的优先级:
<code>thd::tx_priority</code> 事务级别有效,当两个事务在innodb层冲突时,拥有更高值的事务将赢得锁;
<code>thd::thd_tx_priority</code> 线程级别有效,当该变量被设置时,选择该值作为事务优先级,否则选择tx_priority。
死锁检测
在进行死锁检测时,需要对死锁的两个事务的优先级进行比较,低优先级的总是会被优先回滚掉,以保证高优先级的事务正常执行(<code>deadlockchecker::check_and_resolve</code>)。
处理锁等待
在对记录尝试加锁时,如果发现有别的事务和当前事务冲突(<code>lock_re_other_has_conflicting</code>),需要判断是否要加入到等待队列中(<code>reclock::add_to_wait</code>):
如果两个事务都设置了高优先级、但当前事务优先级较低,或者冲突的事务是一个后台进程开启的事务(例如dict_stat线程进行统计信息更新),则立刻失败该事务,并返回db_deadlock错误码;
尝试将当前锁对象加入到等待队列中(<code>reclock::enqueue_priority</code>),高优先级的事务可以跳过锁等待队列(<code>reclock::jump_queue</code>),被跳过的事务需要被标记为异步回滚状态(<code>reclock::mark_trx_for_rollback</code>),搜集到当前事务的<code>trx_t::hit_list</code>链表中。当阻塞当前事务的另外一个事务也处于等待状态、但等待另外一个不同的记录锁时,调用<code>rollback_blocking_trx</code>直接回滚掉,否则在进入锁等待之前再调用<code>trx_kill_blocking</code>依次回滚。
阅读代码时发现这个在5.7版本新加的变量,从它的命名可以看出,其应该和脏页flush相关。<code>flush_observer</code>可以认为是一个标记,当某种操作完成时,对于带这种标记的page(<code>buf_page_t::flush_observer</code>),需要保证完全刷到磁盘上。
为了解决这一问题,引入了<code>flush_observer</code>,在建索引之前创建一个<code>flushobserver</code>并分配给事务对象(<code>trx_set_flush_observer</code>),同时传递给<code>btrbulk::m_flush_observer</code>。
在构建索引的过程中产生的脏页,通过<code>mtr_commit</code>将脏页转移到flush_list上时,顺便标记上flush_observer(<code>add_dirty_page_to_flush_list —> buf_flush_note_modification</code>)。
当做完索引构建操作后,由于bulk load操作不记redo,需要保证ddl产生的所有脏页都写到磁盘,因此调用<code>flushobserver::flush</code>,将脏页写盘(<code>buf_lru_flush_or_remove_pages</code>)。在做完这一步后,才开始apply online ddl过程中产生的row log(<code>row_log_apply</code>)。
如果ddl被中断(例如session被kill),也需要调用<code>flushobserver::flush</code>,将这些产生的脏页从内存移除掉,无需写盘。
为了减少构建事务对象时的内存操作开销,尤其是短连接场景下的性能,innodb引入了一个池结构,可以很方便的分配和释放事务对象。实际上事务的事务锁对象也引用了池结构。
事务池对应的全局变量为<code>trx_pools</code>,初始化为:
<code>trx_pools</code>是操作trx pool的接口,类型为<code>trx_pools_t</code>,其定义如下:
其中,<code>trx_t</code>表示事务对象类型,trxfactory封装了事务的初始化,trxpoollock封装了pool锁的创建、销毁、加锁、解锁,poolmanager封装了池的管理方法。
这里涉及到多个类:
pool 及 poolmanager 是公共用的类;
trxfactory 和 trxpoollock, trxpoolmanagerlock是trx pool私有的类;
trxfactory用于定义池中事务对象的初始化和销毁动作;
trxpoollock用于定义每个池中对象的互斥锁操作;
由于pool的管理结构支持多个pool对象,trxpoolmanagerlock用于互斥操作增加pool对象。支持多个pool对象的目的是分拆单个pool对象的锁开销,避免引入热点。因为从pool中获取和返还对象,都是需要排他锁的。
相关类的关系如下图所示:
事务池相关类
innodb有两个非常重要的模块来实现mvcc,一个是undo日志,用于记录数据的变化轨迹,另外一个是readview,用于判断该session对哪些数据可见,哪些不可见。实际上我们已经在之前的月报中介绍过这部分内容,这里再简要介绍下。
前面已经多次提到过readview,也就是事务视图,它用于控制数据的可见性。在innodb中,只有查询才需要通过readview来控制可见性,对于dml等数据变更操作,如果操作了不可见的数据,则直接进入锁等待。
readview包含几个重要的变量:
<code>readview::id</code> 创建该视图的事务id;
<code>readview::m_ids</code> 创建readview时,活跃的读写事务id数组,有序存储;
<code>readview::m_low_limit_id</code> 设置为当前最大事务id;
<code>readview::m_up_limit_id</code> m_ids集合中的最小值,如果m_ids集合为空,表示当前没有活跃读写事务,则设置为当前最大事务id。
很显然readview的创建需要在<code>trx_sys->mutex</code>的保护下进行,相当于拿到了当时的一个全局事务快照。基于上述变量,我们就可以判断数据页上的记录是否对当前事务可见了。
为了管理readview,mvcc子系统使用多个链表进行分配、维护、回收readview:
<code>mvcc::m_free</code> 用于维护空闲的readview对象,初始化时创建1024个readview对象(<code>trx_sys_create</code>),当释放一个活跃的视图时,会将其加到该链表上,以便下次重用;
<code>mvcc::m_views</code> 这里存储了两类视图,一类是当前活跃的视图,另一类是上次被关闭的只读事务视图。后者主要是为了减少视图分配开销。因为当系统的读占大多数时,如果在两次查询中间没有进行过任何读写操作,那我们就可以重用这个readview,而无需去持有<code>trx_sys->mutex</code>锁重新分配;
另外purge系统在开始purge任务时,需去克隆<code>mvcc::m_views</code>链表上未被close的最老视图,并在本地视图中将该最老事务的事务id也加入到不可见的事务di集合<code>readview::m_ids</code>中(<code>mvcc::clone_oldest_view</code>)。
回滚段undo是实现innodb mvcc的根基。每次修改聚集索引页上的记录时,变更之前的记录都会写到undo日志中。回滚段指针包括undo log所在的回滚段id、日志所在的page no、以及page内的偏移量,可以据此找到最近一次修改之前的undo记录,而每条undo记录又能再次找到之前的变更。
当有可能undo被访问到时,purge_sys将不会去清理undo log,如上所述,purge_sys只会去清理最老readview不会看到的事务。这意味着,如果你运行了一个长时间的查询sql,或者以大于rc的隔离级别开启了一个事务视图但没有提交事务,purge系统将一直无法前行,即使你的会话并不活跃。这时候undo日志将无法被及时回收,最直观的后果就是undo空间急剧膨胀。
如上所述,聚集索引的可见性判断和二级索引的可见性判断略有不同。因为二级索引记录并没有存储事务id信息,相应的,只是在数据页头存储了最近更新该page的trx_id。
对于聚集索引记录,当我们从btree获得一条记录后,先判断(<code>lock_clust_rec_cons_read_sees</code>)当前的readview是否满足该记录的可见性:
如果记录的<code>trx_id</code>小于<code>readview::m_up_limit_id</code>,则说明该事务在创建readview时已经提交了,肯定可见;
如果记录的<code>trx_id</code>大于等于<code>readview::m_low_limit_id</code>,则说明该事务是创建readview之后开启的,肯定不可见;
当<code>trx_id</code>在<code>m_up_limit_id</code>和<code>m_low_limit_id</code>之间时,如果在<code>readview::m_ids</code>数组中,说明创建readview时该事务是活跃的,其做的变更对当前视图不可见,否则对该<code>trx_id</code>的变更可见。
如果基于上述判断,该数据变更不可见时,就尝试通过undo去构建老版本记录(<code>row_sel_build_prev_vers_for_mysql -->row_vers_build_for_consistent_read</code>),直到找到可见的记录,或者到达undo链表头都未找到。
注意当隔离级别设置为read uncommitted时,不会去构建老版本。
如果我们查询得到的是一条二级索引记录:
首先将page头的<code>trx_id</code>和当前视图相比较:如果小于<code>readview::m_up_limit_id</code>,当前事务肯定可见;否则就需要去找到对应的聚集索引记录(<code>lock_sec_rec_cons_read_sees</code>);
如果需要进一步判断,先根据icp条件,检查是否该记录满足push down的条件,以减少回聚集索引的次数;
满足icp条件,则需要查询聚集索引记录(<code>row_sel_get_clust_rec_for_mysql</code>),之后的判断就和上述聚集索引记录的判断一致了。
在innodb中,只有读查询才会去构建readview视图,对于类似dml这样的数据更改,无需判断可见性,而是单纯的发现事务锁冲突,直接堵塞操作。
然而在不同的隔离级别下,可见性的判断有很大的不同。
read-uncommitted
在该隔离级别下会读到未提交事务所产生的数据更改,这意味着可以读到脏数据,实际上你可以从函数<code>row_search_mvcc中</code>发现,当从btree读到一条记录后,如果隔离级别设置成read-uncommitted,根本不会去检查可见性或是查看老版本。这意味着,即使在同一条sql中,也可能读到不一致的数据。
read-committed
在该隔离级别下,可以在sql级别做到一致性读,当事务中的sql执行完成时,readview被立刻释放了,在执行下一条sql时再重建readview。这意味着如果两次查询之间有别的事务提交了,是可以读到不一致的数据的。
repeatable-read
可重复读和read-committed的不同之处在于,当第一次创建readview后(例如事务内执行的第一条seelct语句),这个视图就会一直维持到事务结束。也就是说,在事务执行期间的可见性判断不会发生变化,从而实现了事务内的可重复读。
serializable
序列化的隔离是最高等级的隔离级别,当一个事务在对某个表做记录变更操作时,另外一个查询操作就会被该操作堵塞住。同样的,如果某个只读事务开启并查询了某些记录,那么另外一个session对这些记录的更改操作是被堵塞的。内部的实现其实很简单:
对innodb表级别加<code>lock_is</code>锁,防止表结构变更操作
对查询得到的记录加<code>lock_s</code>共享锁,这意味着在该隔离级别下,读操作不会互相阻塞。而数据变更操作通常会对记录加<code>lock_x</code>锁,和<code>lock_s</code>锁相冲突,innodb通过给查询加记录锁的方式来保证了序列化的隔离级别。
注意不同的隔离级别下,数据具有不同的隔离性,甚至事务锁的加锁策略也不尽相同,你需要根据自己实际的业务情况来进行选择。
在read-committed隔离级别下,我们考虑如下执行序列:
查询条件不同,但指向的确是同一条已插入未提交的记录,为什么会有两种不同的表现呢? 这主要是不同索引在数据检索时的策略不同造成的。
实际上session2的第一条update也为session1做了隐式锁转换,但是在返回到<code>row_search_mvcc</code>时,会走到如下判断:
对于第一条和第二条update,<code>prebuilt->row_read_type</code>值均为<code>row_read_try_semi_consistent</code>,不满足第一个条件;
均不满足<code>unique_search</code>(通过pk,或uk作为where条件进行查询);
第一个使用的聚集索引,三个条件都不满足;而第二个update使用的二级索引,因此走<code>lock_wait_or_error</code>的逻辑,进入锁等待。
第一条update继续往下走,根据undo去构建老版本记录(<code>row_sel_build_committed_vers_for_mysql</code>),一条新插入的记录老版本就是空了,所以认为这条更新没有查询到目标记录,从而忽略了锁阻塞的逻辑。
如果使用pk或者二级索引作为where条件查询的话,都会走到锁等待条件。
推而广之,如果表上没有索引的话,那么对于任意插入的记录,更新操作都见不到插入的记录(但是会为插入操作创建记录锁)。
本小节针对acid这四种数据库特性分别进行简单描述。
所谓原子性,就是一个事务要么全部完成变更,要么全部失败。如果在执行过程中失败,回滚操作需要保证“好像”数据库从没执行过这个事务一样。
从用户的角度来看,用户发起一个commit语句,要保证事务肯定成功完成了;若发起rollback语句,则干净的回滚掉事务所有的变更。
从内部实现的角度看,innodb对事务过程中的数据变更总是维持了undo log,若用户想要回滚事务,能够通过undo追溯最老版本的方式,将数据全部回滚回来。若用户需要提交事务,则将提交日志刷到磁盘。
一致性指的是数据库需要总是保持一致的状态,即使实例崩溃了,也要能保证数据的一致性,包括内部数据存储的准确性,数据结构(例如btree)不被破坏。innodb通过doublewrite buffer 和crash recovery实现了这一点:前者保证数据页的准确性,后者保证恢复时能够将所有的变更apply到数据页上。如果崩溃恢复时存在还未提交的事务,那么根据xa规则提交或者回滚事务。最终实例总能处于一致的状态。
另外一种一致性指的是数据之间的约束不应该被事务所改变,例如外键约束。mysql支持自动检查外键约束,或是做级联操作来保证数据完整性,但另外也提供了选项<code>foreign_key_checks</code>,如果您关闭了这个选项,数据间的约束和一致性就会失效。有些情况下,数据的一致性还需要用户的业务逻辑来保证。
隔离性是指多个事务不可以对相同数据同时做修改,事务查看的数据要么就是修改之前的数据,要么就是修改之后的数据。innodb支持四种隔离级别,如上文所述,这里不再重复。
当一个事务完成了,它所做的变更应该持久化到磁盘上,永不丢失。这个特性除了和数据库系统相关外,还和你的硬件条件相关。innodb给出了许多选项,你可以为了追求性能而弱化持久性,也可以为了完全的持久性而弱化性能。
和大多数dbms一样,innodb 也遵循wal(write-ahead logging)的原则,在写数据文件前,总是保证日志已经写到了磁盘上。通过redo日志可以恢复出所有的数据页变更。
为了保证数据的正确性,redo log和数据页都做了checksum校验,防止使用损坏的数据。目前5.7版本默认支持使用crc32的数据校验算法。
为了解决半写的问题,即写一半数据页时实例crash,这时候数据页是损坏的。innodb使用double write buffer来解决这个问题,在写数据页到用户表空间之前,总是先持久化到double write buffer,这样即使没有完整写页,我们也可以从double write buffer中将其恢复出来。你可以通过innodb_doublewrite选项来开启或者关闭该特性。
innodb通过这种机制保证了数据和日志的准确性的。你可以将实例配置成事务提交时将redo日志fsync到磁盘(<code>innodb_flush_log_at_trx_commit = 1</code>),数据文件的flush策略(<code>innodb_flush_method</code>)修改为0_direct,以此来保证强持久化。你也可以选择更弱化的配置来保证实例的性能。