标题:RoadMap: A Light-Weight Semantic Map for Visual Localization towards Autonomous Driving
作者:Tong Qin, Yuxin Zheng, Tongqing Chen, Yilun Chen, and Qing Su
链接:https://arxiv.org/pdf/2106.02527.pdf
机构:IAS BU Smart Driving Product Dept, Huawei Technologies
编辑:李璟
审核:张海晗
摘要
准确的定位是自动驾驶任务的关键。如今,我们已经看到了很多传感器丰富的车辆(如Robo-taxi)在街道上进行自动驾驶任务,它依赖于高精度传感器(如激光雷达和RTK GPS)和高精地图。然而,低成本的量产汽车负担不起在传感器和地图上如此高昂的费用。如何降低成本?传感器丰富的汽车如何使低成本汽车受益?在本文中,我们提出了一种轻量级的定位解决方案,它依赖于低成本的相机和紧凑的视觉语义地图。地图可以由众包的方式利用传感器丰富的车辆进行制作和更新。具体来说,地图由几个语义元素组成,如路面上的车道线、人行横道、地面标志和停车线。我们介绍了车辆建图、云上维护和用户端本地化的整体框架。地图数据在车辆上进行采集和预处理,然后,将众包数据上传到云服务器。来自众多车辆的海量数据在云上进行合并,实现语义地图的及时更新。最后,将语义地图压缩并分发到量产车辆,量产车辆使用该地图进行定位。我们在真实世界的实验中验证了所提出地图性能,并与其他算法进行了比较。语义地图的平均大小为36KB/km。需要强调的是,该框架是一种可靠、实用的自动驾驶定位解决方案。
1 背景与贡献
为了实现自主驾驶,车辆上安装了各种传感器,如GPS、IMU、摄像头、激光雷达、毫米波雷达、轮式里程计等。基于激光雷达和高精地图的自动驾驶定位方案是Robo-taxi的理想选择。然而,有几个缺点限制了它在一般量产汽车上的使用。首先,量产车负担不起激光雷达和高清地图的高昂成本。此外,点云地图占用大量内存,难以批量生产。同时,高精地图的制作需要耗费大量人力,并且难以保证及时的更新。为了克服这些挑战,应该使用依赖低成本传感器和紧凑地图的方法。
本文的主要贡献如下:
- 提出了一种新的用于自动驾驶任务的轻量级定位框架,包括车辆建图、云端地图维护和用户端定位。
- 我们提出了一个新颖的想法,让低成本车辆从传感器丰富的车辆(如Robo-taxi)受益,传感器丰富的车辆每天自动收集数据和更新地图。
- 我们在真实世界中进行了实验,以验证所提出的系统的实用性。
2 方法
本文所提出系统框架如图1。
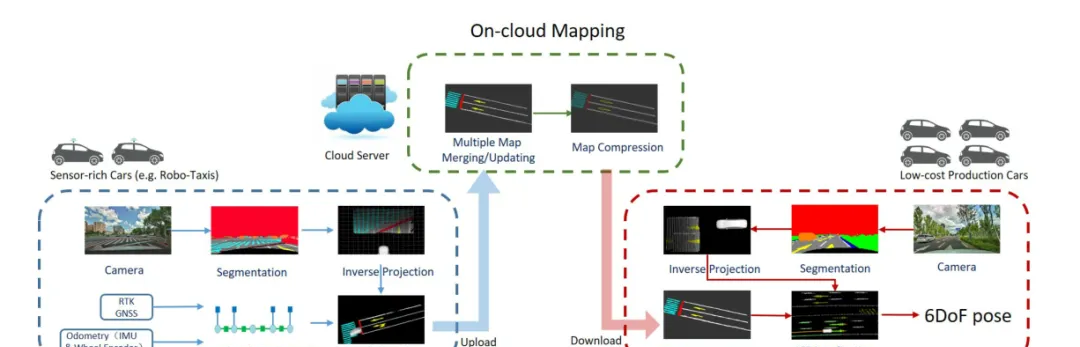
图1.系统结构示意。该系统由三部分组成,第一部分是车端建图,第二部分是云端建图,第三部分是用户端定位。
2.1 车端建图
A.图像分割

图2.(a)为前视相机捕获的原始图像。红框为2.1B节中使用的ROI。(b)为分割结果,将场景划分为多个类别。白色为车道线,蓝色为人行横道,黄色为路标,棕色为停止线,灰色为路面。(c)表示在车辆坐标系下的语义特征。
我们使用一种基于CNN的方法,对场景进行分割。在本文中,前视图像被分割为多个类别,如地面、车道线、停车线、路标、路缘、车辆、自行车和人。其中,地面、车道线、停车线和路标用于语义建图,其他类别可用于其他自动驾驶任务,图像分割的一个例子如图2。
B.逆透视变换
分割后,语义像素点由图像平面反投影到车辆坐标系下的地平面,这一过程称为逆透视变换。离线标定相机内参与其关于车辆中心的外参。由于透视噪声的存在,场景越远,误差越大,因此我们只选择靠近相机中心的一个ROI(Region Of Interest)内的像素进行计算。这个ROI代表了车辆前方的矩形区域,假设地面是一个平面(),那么将像素坐标投影至地平面的过程如下:
其中为相机的畸变校正与投影模型,为相机相对于车辆中心的外参,为像素坐标,为特征在车体中心坐标系下的坐标,是一个标量。表示取矩阵的第列。图2是逆透视变换的一个实例。ROI中每一个被标记的像素都被投影到车辆前方。
C.图优化
图3.蓝线为GNSS信号好的区域,受益于RTK-GNSS的准确性,轨迹信息也是十分准确的。在GNSS阻塞区域,轨迹由绿色线画出,可以看到产生了很大的漂移。为了消除漂移,我们对位姿图进行了优化,优化后的轨迹用红色表示,可以看到轨迹平滑无漂移。
图4.位姿图的示意图。蓝色节点是车辆在某一时刻的状态,包括位置 和方向。图中有两种边,蓝色边表示GNSS约束,其仅在GNSS-good时存在,只影响一个节点。绿色边表示任何时刻都存在的里程计约束,它约束了两个相邻节点。
为了绘制地图,准确的车辆姿态是必要的。虽然采用了RTK-GNSS,但不能保证其能始终提供一个可靠的姿态。RTK-GNSS只能在开放区域提供厘米级的位置。在城市场景中,它的信号很容易被高楼大厦遮挡。导航器件(IMU、轮速计)能够在GNSS阻塞区域提供里程信息。然而,里程计无可避免地存在累计误差(图3),通过位姿图(图4)的优化可以消除累计误差。图优化可以表示为如下方程:
其中为姿态(位置和方向),为里程计的残差因子,为里程计的测量值,包含相邻状态间的位置和姿态,为GNSS残差因子,指GNSS-good区域的状态集合,为GNSS测量值,包含了全局位置。残差因子的形式定义如下,其中为四元数的虚部:
D.本地建图
图5.语义地图压缩与解压缩示例。(a)表示原始语义图,(b)表示语义图的轮廓,(c)表示由轮廓恢复的语义图。
位姿图的优化车辆提供了可靠的姿态信息。在第帧图像中提取的语义特征从车辆坐标系转换到全局坐标系:
从图像分割中,每个点都包含一个类标签(地面、车道线、路标和人行横道)。每个点表示世界系中的一个小区域。当车辆移动时,一个区域可以被多次观察到。然而,由于分割的噪声,这一区域可能被划分为不同的类别。为了克服这个问题,我们使用统计方法来过滤噪声。我们将地图分为小网格,分辨率为0.1 × 0.1 × 0.1m。每个网格的信息包含位置、语义标签和每个语义标签的计数。语义标签包括地面、车道线、停车线、地面标志和人行横道。一开始,每个标签的分数都是零。当语义点插入网格时,相应标签的得分增加1。因此,得分最高的语义标签表示网格的类。通过该方法,语义图对噪声分割具有较好的准确性和鲁棒性。全局建图结果如图5(a)所示。
2.2 云端建图
A.地图合并/更新
云端建图服务器用于聚合多个车辆捕获的大量数据。它及时地合并局部地图,从而使全局语义地图是最新的。为了节省带宽,我们只将局部地图的占用网格上传到云端。与车端建图过程一样,云服务器上的语义地图也被划分为分辨率为0.1 × 0.1 × 0.1m的网格。我们将局部地图的网格根据其位置添加到全局地图中。具体来说,本地地图网格中的分数被添加到全局地图的相应网格中。这个过程是并行运行的。最后,得分最高的标签即为该网格的标签。图8给出了地图更新的详细实例。
B.地图压缩
在云服务器中生成的语义地图将在量产汽车上进行本地化。但是,量产车的传输带宽和车载存储有限。为此,语义地图在云上进一步压缩。由于轮廓线可以有效地表示语义地图,因此采用轮廓提取对语义地图进行压缩。首先,我们生成了语义地图的俯视图图像,每个像素表示一个网格。其次,提取每个语义组的轮廓。最后,将轮廓点保存并分配到量产车上。如图5所示,(a)为原始语义图。图5(b)为该语义图的轮廓。
2.3 用户端定位
A.地图解压
当接收到压缩后的地图后,用户端会从轮廓图中解压得到语义地图。在俯视图图像平面中,我们用相同的语义标签填充轮廓内的点。然后,每个标记像素从图像平面转换到世界系。解压缩后的语义地图示例如图5(c)。对比图5(a)中原始地图和图5(c)中恢复的地图,可见解压方法有效地恢复了语义信息。
B.ICP定位
图6.语义地图定位示意。地图上的白点与黄点分别是车道线和路标。绿色点是观察到的语义特征,橙色线是估计的轨迹。
解压后的语义地图进一步用来进行定位。类似于建图的过程,前视相机图像分割得到的像素投影到车辆坐标系下,生成语义点云。那么,通过将当前特征点与地图进行匹配,就可以得到车体当前姿态,如图6。使用ICP进行估计,公式如下:
其中和分别是四元数和位置。是特征点的集合。是当前车辆坐标系下的特征,是世界系下地图中的最近点。最终采样EKF框架完成里程计与视觉定位结果的融合,该滤波器不仅提高了定位的鲁棒性,而且平滑了轨迹。
3 实验
A.地图生成
制图时,汽车配备有RTK-GPS,前视相机,IMU和轮式编码器。多辆车同时在市区行驶,车辆本地地图通过网络上传到云服务器。最终结果如图7。这一地区的公路总长度为22公里。原始语义地图的整体大小为16.7 MB,压缩后的语义地图的大小为0.786 MB,压缩语义地图的平均大小为36 KB/KM。地图更新的例子如图8。
图7.上海浦东新区一个城市街区的语义地图。该地图已与谷歌地图对齐。
图8.语义更新示例。(a)展示了原始环境,(b)显示行车线重新绘制后的环境,(c)显示了原始语义地图,(d)显示了正在更新的语义地图,(e)显示更新完成的语义地图。
B.定位准确性
在这一部分,我们评估了本方法与基于激光定位方法的精度。车辆配备了摄像头、激光雷达和RTK GPS。RTK GPS被视为真值。由于是自动驾驶场景,我们重点关注x,y方向和偏航角的定位精度。由图9和表1可见,我们的定位方法优于基于lidar的定位方法。
图9.定位误差在x, y,和偏航方向的概率分布图。
表1.定位误差
参考文献
[1] J. Long, E. Shelhamer, and T. Darrell, “Fully convolutional networks for semantic segmentation,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 3431–3440.
[2] O. Ronneberger, P . Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” in International Conference on Medical image computing and computer-assisted intervention.Springer, 2015, pp. 234–241.