我们知道gan的过程是对生成分布拟合真实分布的一个过程,理想目标是让判别器无法识别输入数据到底是来源于生成器生成的数据还是真实的数据。
当然这是一个博弈的过程并且相互促进的过程,其真实的过程在于首先判别器会先拟合真实数据的分布,然后生成器拟合判别器的分布,从而达到生成器对真实数据分布的拟合。

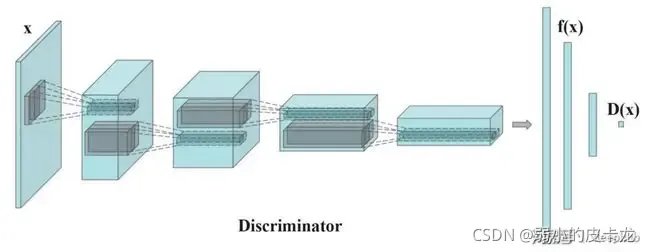
图中蓝色部分为生成器,生成器的功能在于输入一个随机向量经过生成器一系列层的处理输出一个与真实数据尺寸一样的图片。 然后将生成器产生的图片与真实的图片信息一同的输入到判别器中,让判别器去区分该图片信息的源头,如果是判别器产生的图片则识别为fake,如果是生成器产生的图片,则判定为real,因此对于判别器的损失函数就为MSELoss(Pg,torch.zeros_like(Pg)) + MSELoss(Pr, torch.ones_like(Pr))
Pg表示生成器生成的数据,Pr表示真实数据)
而对于生成器来说它的目的在于生成的数据要欺骗判别器,也就是说让判别器都认为它产生的图片就是真实的图片数据(与真实图片无差别),所以生成器的损失函数就是
MSELoss(Pg, torch.ones_like(Pg))
DCGAN相对于普通的GAN只不过是在网络模型中采用了CNN模型
其中主要包含以下几点:
(1)使用指定步长的卷积层代替池化层
(2)生成器和判别器中都使用BatchNormlization
(3)移除全连接层
(4)生成器除去输出层采用Tanh外,全部使用ReLU作为激活函数
(5)判别器所有层都使用LeakyReLU作为激活函数

class Gernerator(nn.Module):
def __init__(self, IMAGE_CHANNELS, NOISE_CHANNELS, feature_channels):
super(Gernerator, self).__init__()
self.features = nn.Sequential(
self._Conv_block(in_channels=NOISE_CHANNELS, out_channels=feature_channels*4, stride=1, kernel_size=4,
padding=0),
self._Conv_block(in_channels=feature_channels*4, out_channels=feature_channels*8, stride=2, kernel_size=3,
padding=1),
self._Conv_block(in_channels=feature_channels*8, out_channels=feature_channels*4, stride=2, kernel_size=3,
padding=1),
nn.ConvTranspose2d(in_channels=feature_channels*4, out_channels=IMAGE_CHANNELS, stride=2, kernel_size=3,
padding=1),
nn.Tanh(),
)
def _Conv_block(self, in_channels, out_channels, kernel_size, stride, padding):
feature = nn.Sequential(
nn.ConvTranspose2d(
in_channels=in_channels,
out_channels=out_channels,
stride=stride,
padding=padding,
kernel_size=kernel_size,
bias=False
),
# nn.BatchNorm2d(num_features=out_channels),
nn.ReLU()
)
return feature
def forward(self, x):
return self.features(x)
```
```python
class Discriminator(nn.Module):
def __init__(self, IMAGE_CHANNELS, feature_channels):
super(Discriminator, self).__init__()
self.features = nn.Sequential(
self._Conv_block(in_channels=IMAGE_CHANNELS, out_channels=feature_channels, stride=2, kernel_size=3,
padding=1),
self._Conv_block(in_channels=feature_channels, out_channels=feature_channels * 2, stride=2, kernel_size=3,
padding=1),
self._Conv_block(in_channels=feature_channels * 2, out_channels=feature_channels * 4, stride=2, kernel_size=3,
padding=1),
self._Conv_block(in_channels=feature_channels * 4, out_channels=feature_channels * 2, stride=2, kernel_size=3,
padding=1),
nn.Conv2d(in_channels=feature_channels * 2, out_channels=IMAGE_CHANNELS, stride=2, kernel_size=3,
padding=1),
nn.Sigmoid()
)
def _Conv_block(self, in_channels, out_channels, kernel_size, stride, padding):
feature = nn.Sequential(
nn.Conv2d(
in_channels=in_channels,
out_channels=out_channels,
stride=stride,
padding=padding,
kernel_size=kernel_size,
bias=False
),
# nn.BatchNorm2d(num_features=out_channels),
nn.LeakyReLU(negative_slope=0.2)
)
return feature
def forward(self, x):
return torch.sigmoid(self.features(x))
具体的情况需要具体设计相应的Generator和Discriminator
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
from torch.utils.data import Dataset, DataLoader
import torchvision.transforms as Transforms
from torchvision.datasets import ImageFolder
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
import os
class Gernerator(nn.Module):
def __init__(self, IMAGE_CHANNELS, NOISE_CHANNELS, feature_channels):
super(Gernerator, self).__init__()
self.features = nn.Sequential(
self._Conv_block(in_channels=NOISE_CHANNELS, out_channels=feature_channels*4, stride=1, kernel_size=4,
padding=0),
self._Conv_block(in_channels=feature_channels*4, out_channels=feature_channels*8, stride=2, kernel_size=3,
padding=1),
self._Conv_block(in_channels=feature_channels*8, out_channels=feature_channels*4, stride=2, kernel_size=3,
padding=1),
nn.ConvTranspose2d(in_channels=feature_channels*4, out_channels=IMAGE_CHANNELS, stride=2, kernel_size=3,
padding=1),
nn.Tanh(),
)
def _Conv_block(self, in_channels, out_channels, kernel_size, stride, padding):
feature = nn.Sequential(
nn.ConvTranspose2d(
in_channels=in_channels,
out_channels=out_channels,
stride=stride,
padding=padding,
kernel_size=kernel_size,
bias=False
),
# nn.BatchNorm2d(num_features=out_channels),
nn.ReLU()
)
return feature
def forward(self, x):
return self.features(x)
class Discriminator(nn.Module):
def __init__(self, IMAGE_CHANNELS, feature_channels):
super(Discriminator, self).__init__()
self.features = nn.Sequential(
self._Conv_block(in_channels=IMAGE_CHANNELS, out_channels=feature_channels, stride=2, kernel_size=3,
padding=1),
self._Conv_block(in_channels=feature_channels, out_channels=feature_channels * 2, stride=2, kernel_size=3,
padding=1),
self._Conv_block(in_channels=feature_channels * 2, out_channels=feature_channels * 4, stride=2, kernel_size=3,
padding=1),
self._Conv_block(in_channels=feature_channels * 4, out_channels=feature_channels * 2, stride=2, kernel_size=3,
padding=1),
nn.Conv2d(in_channels=feature_channels * 2, out_channels=IMAGE_CHANNELS, stride=2, kernel_size=3,
padding=1),
nn.Sigmoid()
)
def _Conv_block(self, in_channels, out_channels, kernel_size, stride, padding):
feature = nn.Sequential(
nn.Conv2d(
in_channels=in_channels,
out_channels=out_channels,
stride=stride,
padding=padding,
kernel_size=kernel_size,
bias=False
),
# nn.BatchNorm2d(num_features=out_channels),
nn.LeakyReLU(negative_slope=0.2)
)
return feature
def forward(self, x):
return torch.sigmoid(self.features(x))
def initialize_weights(model):
# Initializes weights according to the DCGAN paper
for m in model.modules():
if isinstance(m, (nn.Conv2d, nn.ConvTranspose2d, nn.BatchNorm2d)):
nn.init.normal_(m.weight.data, 0.0, 0.02)
IMAGE_CHANNELS = 3
NOISE_CHANNELS = 100
FEATURE_CHANNELS = 32
BATCH_SIZE = 16
NUM_EPOCHS = 5
LEARN_RATE = 2e-4
IMAGE_SIZE = 64
D_PATH = 'logs/121_D.pth'
G_PATH = 'logs/41q_G.pth'
mytransformers = Transforms.Compose([
Transforms.Resize((IMAGE_SIZE, IMAGE_SIZE)),
Transforms.ToTensor(),
Transforms.Normalize(std=[0.6585589, 0.55756074, 0.54101795], mean=[0.28972548, 0.28038123, 0.26353073]),
])
trainset = ImageFolder(root=r'D:\QQPCmgr\Desktop\gan\A', transform=mytransformers)
trainloader = DataLoader(
dataset=trainset,
batch_size=BATCH_SIZE,
shuffle=True
)
writer_real = SummaryWriter(f"logs/real")
writer_fake = SummaryWriter(f"logs/fake")
step = 0
if __name__ == '__main__':
device = torch.device("cpu" if torch.cuda.is_available() else "cpu")
print("cuda:0" if torch.cuda.is_available() else "cpu")
Dnet = Discriminator(IMAGE_CHANNELS, FEATURE_CHANNELS).to(device)
initialize_weights(Dnet)
# Dnet.load_state_dict(torch.load(D_PATH))
Gnet = Gernerator(IMAGE_CHANNELS, NOISE_CHANNELS, FEATURE_CHANNELS).to(device)
initialize_weights(Gnet)
Dnet.train()
Gnet.train()
# Gnet.load_state_dict(torch.load(G_PATH))
noise = torch.randn((BATCH_SIZE, NOISE_CHANNELS, 1, 1)).to(device)
ceritionG = nn.BCELoss(reduction='mean')
ceritionD = nn.BCELoss(reduction='mean')
optimizerG = torch.optim.Adam(params=Gnet.parameters(), lr=0.0002, betas=(0.5, 0.999))
optimizerD = torch.optim.Adam(params=Dnet.parameters(), lr=0.0002, betas=(0.5, 0.999))
for epoch in range(1000):
for i, data in enumerate(trainloader, 1):
optimizerD.zero_grad()
optimizerG.zero_grad()
r_img, _ = data
r_img = r_img.to(device)
fake_img = Gnet.forward(noise)
r_label = (torch.ones_like(Gnet.forward(r_img))).to(device)
f_label = torch.ones_like(Gnet.forward(r_img)).to(device)
lossG = ceritionD(Dnet.forward(Gnet.forward(noise)), r_label)
lossD = ceritionD(Dnet.forward(r_img), r_label) / 2 + ceritionD(Dnet.forward(Gnet.forward(noise)), f_label) / 2
lossG.backward()
lossD.backward()
optimizerD.step(retain_graph=True)
optimizerG.step(retain_graph=True)
print('[epoch:%d],[lossD:%f],[lossG:%f]...........%d/10000' % (epoch, lossD.item(), lossG.item(), i*BATCH_SIZE))
if i % 50 == 0:
with torch.no_grad():
img_grid_real = torchvision.utils.make_grid(
r_img, normalize=True,
)
img_grid_fake = torchvision.utils.make_grid(
fake_img, normalize=True
)
writer_fake.add_image("fake_img", img_grid_fake, global_step=step)
writer_real.add_image("real_img", img_grid_real, global_step=step)
step += 1