今天在开发时候,存在这样一个需求场景:需要获取数据库中的数据记录,如果存在该记录则更新该记录中的某些字段值;如果查询结果为空即不存在该记录,则要插入一条新的纪录;
接手过来的代码模块是这样实现的:
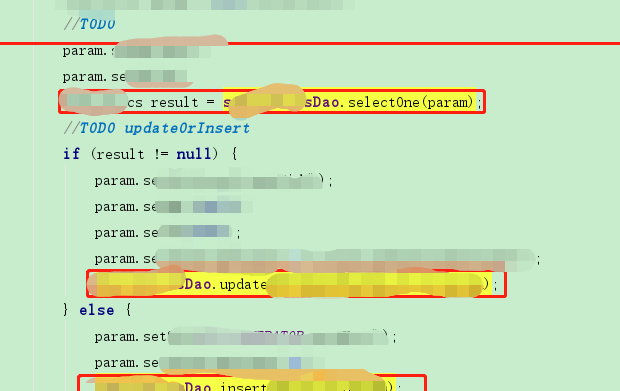
先通过sql查询数据,然后判断是否为空,再去update或者insert~
然后就想去把代码优化一下,了解到MySQL一条语句可以解决这个问题:ON DUPLICATE KEY UPDATE
该语句的语法如下:
INSERT INTO tablename(field1,field2, field3, ...) VALUES(value1, value2, value3, ...) ON DUPLICATE KEY UPDATE field1=value1,field2=value2, field3=value3, ...;
这个语法的目的是为了解决重复性,当数据库中存在某个记录时,执行这条语句会更新它,而不存在这条记录时,会插入它。
该语句规则如下:如果你插入的记录导致一个UNIQUE索引或者primary key(主键)出现重复,那么就会认为该条记录存在,则执行update语句而不是insert语句,反之,则执行insert语句而不是更新语句。
得到了这个方法,果断替换掉原有方法,代码简洁明了多了,如下:

原以为万事大吉,搞定完事了。
结果自测时候发现了实际效果不跟预期结果一样,经排查发现这个方法使用存在问题:
当操作的存在主键跟索引不一致的情况时,比如表主键是id,索引是a_b;
该语句会先执行insert,判断主键id是否存在重复,不存在则插入新数据;但这个时候如果a_b是有重复的,则该语句会正常执行(即不报错)但是并不会更新数据或者插入新纪录;
这种情况下,我们期待的数据更新就没有如期进行,会造成严重的数据丢失问题!!!