文章目录
- 0 背景
- 1 常识
- 2 SELECT语句
- 2.0 别名
- 2.1 筛选
- 2.2 函数
- 2.3 过滤分组
- 3 联结(最重要的特性)
- 3.1 完全限定名
- 3.2 笛卡尔积(叉联结)
- 3.2,等值联结(内联结)
- 3.3 自联结和子查询、自然联结
- 3.4 外联结
- 3.4 全联结(SQLite不支持)
- 4 并/复合查询
- 4.1 UNION(会自动去重)
- 4.2 UNION ALL
- 5 插入语句
- 5.1 插入检索的数据
- 5.2 从一个表复制到另一个表
- 6 更新值
- 7 删除值
- 7.1 删除列值
- 7.2 删除行值
- 7.3 删除表
- 8 创建表/更新表
- 9 视图
- 10 存储过程(SQLite不支持)
- 11 事务
- 12 游标/步骤(Step)
- 13 约束
- 13.1 主键
- 13.2 外键
- 13.3 唯一约束
- 14 索引
- 15 触发器(特殊的存储过程)
- 16 安全性
- 17 数据规范
0 背景
因为项目要涉及到大量的操作数据库的操作,所以要熟练掌握基本的SQL(Structured Query Language)语句。其实大二的时候,学校就开设有专门的数据库课程(使用的是SQL Server),但是没有好好的学习,学过后,又很少接触到涉及到这方面的项目,于是大部分知识都忘记了。这次就是通过再次系统的学习一遍SQL语句,捡起曾经学过的知识。由于项目用到的数据库为SQLite,本文就是这次学习SQLite的一个笔记,因此可能不适用于其他数据库。
1 常识
- 1,数据库软件是指DBMS(Data base manager system),而数据库是指有组织的数据库容器(一个数据库文件或一组文件,如带有db后缀的数据库文件)
- 2,市场上有很多数据库软件如SQL Server、Orccle、MySQL、MariaDB、PostgreSQL、SQLite等等,不同的数据库软件数据类型和名称是不同的,这就造成了SQL不兼容,我们学习的话一般可以学习ANSI SQL(美国标准学会SQL)的语法规范,然后再根据自己实际使用的数据库学习对应特有的语法(如存储过程SQLite就没有)
- 3,一般使用全大写的书写SQL的关键词,对列名和表名使用小写,来让代码更易阅读和理解,虽然SQL不区分大小写
2 SELECT语句
SELECT 列名/(列名 ,COUNT(*) AS 别名)/(列名 || 拼接字符串) FROM 表名
WHERE 条件
GROUP BY 列名 HAVING COUNT(*) >/=/<=/!= 值
LIMIT 显示的行数 OFFSET 从第几行显示的行数
ORDER BY 依据的排序的列 DESC(降序)/ASC(默认升序) 混淆点:
- WHERE:过滤行,在分组前过滤;HAVING:过滤分组,在分组后过滤
- GROUP BY:只能对选择的列和表达式使用,在有聚集函数的时候必须使用;ORDER BY:对非选择列也可以使用,对输出顺序排序(GROUP BY不排序)
2.0 别名
AS(Oracle中不使用它,直接把取得名字用于表名和列名后)
作用:给导出的列命名
2.1 筛选
WHERE:
- 1
WHERE 条件 BETWEEN 值 AND 值 - 2,
WHERE 条件 AND 条件 - 3,
- AND的优先级大于OR
WHERE 条件 OR 条件 - 4,
- OR与IN作用相等,一般推荐使用IN
WHERE 条件 IN(值1、值2) - 5,
WHERE NOT 条件 - 6,
- 通配符
- %:任何字符出现任何次数,但不匹配NULL
- _:匹配单个字符
- 不要过度使用通配符
WHERE 条件 LIKE 值 2.2 函数
- 1,文本处理函数
-
1,去空格
RTRIM(去空格右边),LIRIM(去空格左边),TRIM(去空格左右两边)
-
2,大小写转换
UPPER(转大写),LOWE(将字符转转小写)
-
3,SOUNDEX
将任何文串转换为其语音表示的字母数字模式的算法
- 2,时间处理函数
-
1 strftime(’%格式’, 列名)
作用:根据第一个参数指定的格式字符串返回格式化的日期
时间格式:
%d 日期, 01-31
%f 小数形式的秒,SS.SSS
%H 小时, 00-23
%j 算出某一天是该年的第几天,001-366
%m 月份,00-12
%M 分钟, 00-59
%s 从1970年1月1日到现在的秒数
%S 秒, 00-59
%w 星期, 0-6 (0是星期天)
%W 算出某一天属于该年的第几周, 01-53
%Y 年, YYYY
%% 百分号 - 2,返回时间
date(timestring, modifier, modifier, ...):以 YYYY-MM-DD 格式返回日期。
time(timestring, modifier, modifier, ...):以 HH:MM:SS 格式返回时间。
datetime(timestring, modifier, modifier, ...):以 YYYY-MM-DD HH:MM:SS 格式返回。
julianday(timestring, modifier, modifier, ...):这将返回从格林尼治时间的公元前 4714 年 11 月 24 日正午算起的天数。 timestring:
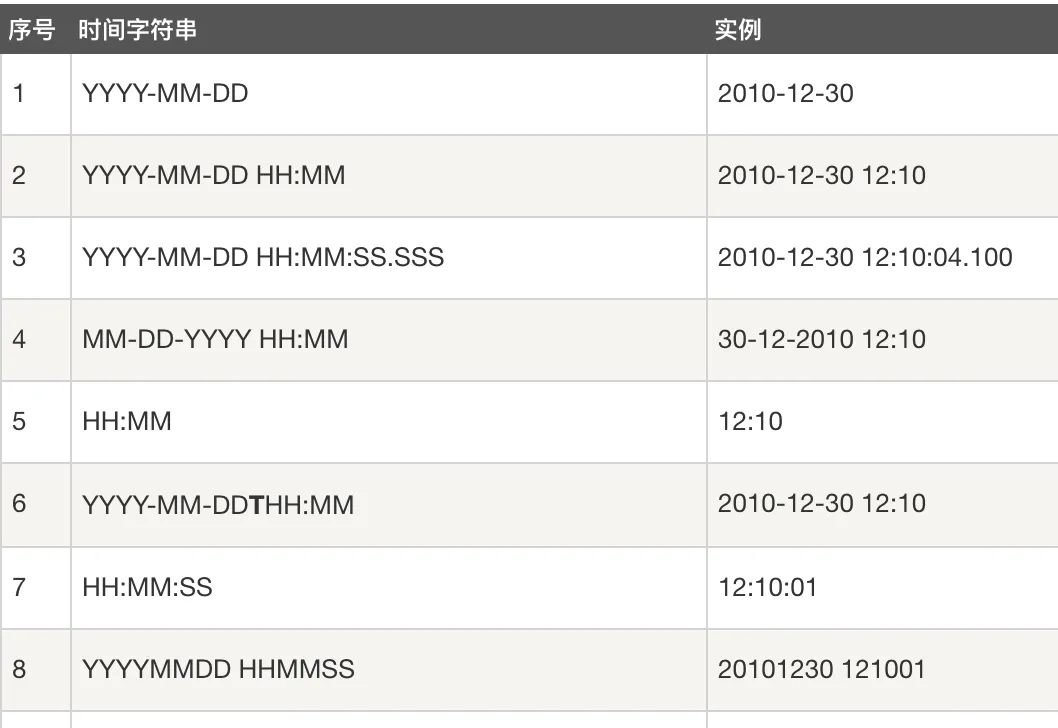
修饰语(modifier):
NNN days
NNN hours
NNN minutes
NNN.NNNN seconds
NNN months
NNN years
start of month
start of year
start of day
weekday N
unixepoch
localtime
utc 示例:
计算本月最后一天:
SELECT date('now','start of month','+1 month','-1 day'); 由时间戳得到相对本地的日期:
SELECT datetime(1092941466, 'unixepoch', 'localtime'); 由日期得到时间戳:
SELECT strftime('%s','now'); 计算美国"独立宣言"签署以来的天数
SELECT julianday('now') - julianday('1776-07-04'); 从 2004 年某一特定时刻以来的秒数:
SELECT strftime('%s','now') - strftime('%s','2004-01-01 02:34:56'); 下面是计算当年 10 月的第一个星期二的日期:
SELECT date('now','start of year','+9 months','weekday 2'); 本小节的列子和图片摘自runoob网站
-
3,数值处理函数
ABS()绝对值、COS()余弦值、TAN()正切、SIN()正弦、EXP()返回一个数的指数、PI()返回圆周率、SQRT()一个数的平方根、
- 4,聚集函数(对某些列运行的并计算出一个值)
- AVG:某列平均值
- COUNT:某列的行数
- COUNT(*):对空值也计算
- DISTINCT:只包含不同值;只能用于COUNT(),不用于CONT(*),必须使用列名;
-
SELECT AVG(DISTINCT price) AS avg_price FROM product WHERE id = '1'
- ALL:对所有行执行(默认)
- MAX:某列的最大值
- MIN:某列的最小值
- SUM:某列之和
2.3 过滤分组
-
1 GROUP BY(分组)
将数据分为多个逻辑组,然后对每个组进行聚集计算
- 2,HAVING(过滤分组)
3 联结(最重要的特性)
3.1 完全限定名
在使用列名的时候,指名表名,例如
SELECT goods.id,price.id FROM goods,price
,用于当两个表中有相同的列名时避免混淆;
3.2 笛卡尔积(叉联结)
返回两个第一个表的行数*第二个表的行数的检索列数

3.2,等值联结(内联结)
返回两个表得中的相等的值
SELECT name FROM students,teachers WHERE students.id = teachers.id 等同于
SELECT name FROM students JOIN teachers ON students.id = teachers.id 3.3 自联结和子查询、自然联结
-
1,self-join(不止一次使用相同的表)
例如:
子联结:
SELECT id FROM students WHERE name = (SELECT course FROM students WHERE = 'math') 使用联结:
SELECT s1.id FROM students AS s1 ,students AS s2 WHERE s1.name = s2.name AND s2.course = 'math' 一般使用联结要比使用子查询快许多
-
2,nature join(自然联结)
自动使用所有匹配的列名进行连接【未能证实:可以排除相同列的多次出现,使每一个列值返回一次 】
要求两个表中要有相同的列名和属性值,否则返回笛卡尔积
SELECT C.*,O.* FROM Customers C NATURAL JOIN Orders O 3.4 外联结
下图是外联结中的左联结,SQLite中不支持右联结,但是只要挑换FROM或WHERE中的表顺序即可将左联结转为右联结。
3.4 全联结(SQLite不支持)
FULL OUTER JOIN:返回两个表中的所有行,并关联可以关联的行。
4 并/复合查询
对不同表或者一个表进行多次查询。
4.1 UNION(会自动去重)
- 1,两条及以上的SELECT语句使用;
- 2,每个查询包含相同的列表达式、聚集函数;
- 3,只允许使用一条ORDER BY语句。
4.2 UNION ALL
不取消重复行,
5 插入语句
INSERT INTO/IGNORE 表名(列名) VALUES(值1,值2,。。。) IGNORE:如果中已经存在相同的记录,则忽略当前新数据,并忽略错误;INTO:如果有相同数据则报错
5.1 插入检索的数据
INSERT INTO 表名(列名) SELECT 列名 FROM 表名 5.2 从一个表复制到另一个表
SELECT 列名 INTO 表名 FROM 表名 DB2不支持上述语法
CREATE TABLE 表名 AS SELECT 列名 FROM 表名 6 更新值
更改值前,先用WHERE确定一遍WHERE过滤的值是否正确
UPDATE 表名 SET 列名 = 值 WHERE 过滤条件 7 删除值
7.1 删除列值
UPDATE 表名 SET 列名 = 值 WHERE 过滤条件 设值为NULL,即可删除列值
7.2 删除行值
删除行值:
DELETE FROM 表名 过滤条件 删除所有行一般使用:
TRUNCATE TABLE 表名 SQLite没有上述语法,一般使用
DELETE FROM 表名
7.3 删除表
DROP TABLE 表名 8 创建表/更新表
创建表
CRETAE TABLE表名(列名 类型 是否为空 DEFAULT 默认值,...列名 类型 是否为空 DEFAULT 默认值) 更新表
ALTER TABLE 表名 (ADD 列名 属性)/(RENAME TO 新表名) SQLite不支持ALTER TABLE定义主键和外键
9 视图
SQLite支持可读视图
- 1, 把查询包装成一个虚拟表
- 2,重用SQL语句,使用表的一部分,保护数据、更改数据格式和表示
创建视图:
CREATE VIEW 表名 AS 别名 语句 删除视图:
DROP VIEW 表名 10 存储过程(SQLite不支持)
关键词:PROCEDURE
作用:为以后使用而保存一条而多条SQL语句
11 事务
创建事务:
BEGIN TRANSACTION/BEGIN -- 开始事务
..事务
COMMIT/END TRANSACTION -- 提交 回退(不能回退CRETAE、DROP、SELECT操作):
ROLLBACK; 保留点:事务处理的临时占位符,可对它发布回退
12 游标/步骤(Step)
作用:操作结果集的行
用于:
- 1,滚动屏幕上的数据,并对数据左出游览或更改;
- 2,一旦声明,就必须打开游标以供使用,结束使用时,必须关闭游标
13 约束
作用:管理插入或处理数据库的规则
13.1 主键
- 1,任意两行的主键值不同
- 2,每行只有一个主键且唯一,且不为NULL
- 3,主键列不修改、不更新
-
4,主键不重复
关键词:PRIMARY KEY
SQLite不允许使用ALTER TABLE定义主键
13.2 外键
含义:表中一列,其值为另一个表中的主键
-
1,防止意外删除(有些DBMS可用级联删除)
关键词:REFERENCES
13.3 唯一约束
- 1,不能用于定义外键
-
2,区别与外键,它可以是多个、可包含NULL、可修改、可更新、可重复使用
关键词:UNIQUE
检查约束:CHECK
14 索引
作用:恰当的排序
- 1,改善检查操作的性能,降低了数据插入、删除、修改的性能
- 2,占用大量的存储空间
- 3,尽量用于数据过滤或排序的列
- 4,可在索引定义多个列
- 5,定期检查索引并调整
15 触发器(特殊的存储过程)
作用: 在特定的数据活动发生时出发
- 1,数据访问权:INSERT/UPDATE/DELETE 所有数据库
- 2,常见用途:保证数据一致,基于表的变动在其他表执行活动,进行额外的验证并根据需要回退;计算值或更新时间戳
约束比出发器更快,应尽量使用约束
CREATE TRIGGER trigger_name [BEFORE|AFTER] event_name
ON table_name
BEGIN
-- 触发器逻辑....
END; event_name:INSERT/UPDATE 等
16 安全性
GRANT/REVOKE:管理访问
17 数据规范
- 1,变长性能远低于鼎昌的
- 2,值在单引号内
- 3,计算的值存在数据类型,否则存在字符串(如0123,在数值中可能会丢值)