本文图片以及文本仅供学习、交流使用,不做商业用途,如有问题请及时联系我们以作处理。
前言
互联网给了我们很多的方便,而网络小说、电子书等也应潮流而发展,方便了人随时查看想要看的图书,方便携带。
在上一期python爬虫中,我们讲解了python如何爬取整本小说:用python爬取全站小说,你想看的都爬下来!
今天教大家爬取豆瓣读书网,获取图书的书名、价格等数据,保存为csv文件。
分析网页
目标网址:
https://book.douban.com/tag/%E7%BC%96%E7%A8%8B?start=0&type=T
复制
我们需要爬取他的书名、作者、编译、出版社、出版时间、定价、纸质版价格、评分、简介。
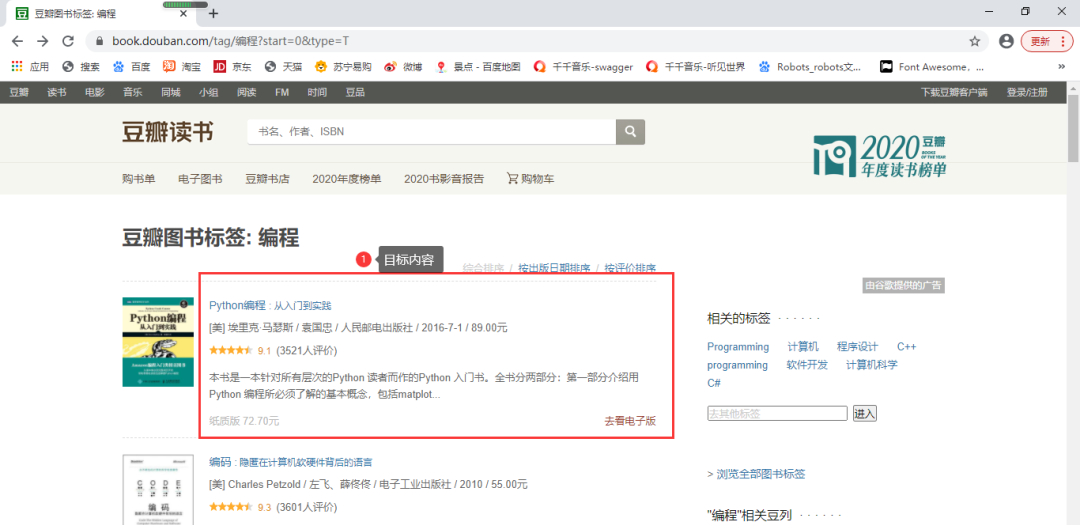
我们需要的内容都在源代码中,可以确定该网页是静态网页。

拉到网页底部,点击下一页查看url变化:
https://book.douban.com/tag/%E7%BC%96%E7%A8%8B?start=0&type=T
https://book.douban.com/tag/%E7%BC%96%E7%A8%8B?start=20&type=T
https://book.douban.com/tag/%E7%BC%96%E7%A8%8B?start=40&type=T
复制
发现url中的start参数会发生递增变化,每次增加20,后期我们只需要更改url后面的offse参数即可进行翻页爬取。
导入模块
今天需要用到time模块进行减速,防止爬取的太快对网页造成负担;requests模块进行数据的请求;lxml模块中xpath进行数据的提取;pandas模块用来保存数据。
import time
import requests
from lxml import etree
import pandas as pd
复制
请求数据
创建数据请求函数,传入page页数参数,用来进行翻页操作;构建headers,伪装请求头,防止被服务器识别;用resposn进行接收请求的数据,然后return 进行回调。
def resposn(page):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11'}
url = 'https://book.douban.com/tag/%E7%BC%96%E7%A8%8B?start={}&type=T'.format(page)
resposn = requests.get(url=url, headers=headers).text
return resposn
复制
提取数据和保存数据
我们需要的数据全部都在li标签里面,所以先用xpath获取li标签,然后在用循环提取里面的内容。
书名等内容在li标签下的多级标签中,所以我们需要向下层层提取:
创建数据提取和数据保存函数,传入resposn参数,然后创建DataFrame,以便后面保存:
def lists(resposn):
df = pd.DataFrame()
复制
转换HTML格式,然后先提取li标签:
etree_html = etree.HTML(resposn)
subject_item = etree_html.xpath('.//ul/li[@class="subject-item"]')
复制
循环取出li标签里面的内容,然后用xpath语法提取我们需要的内容;其中,爬取的书名等数据内容比较杂乱,有很多的空行,这里用列表推导式进行strip去除空行,然后join一下取出数据。
for li in subject_item:
# 书名
title = li.xpath('.//div[@class="info"]/h2/a//text()')
we_title = ''.join([x.strip() for x in title])
# 作者/编译/出版社/出版时间/定价
cbs_pub = li.xpath('.//div[@class="pub"]/text()')[0].strip()
# 纸质版价格
ft = li.xpath('.//div[@class="ft"]/div/span/a/text()')
ft = ''.join([x.strip() for x in ft])
# 评分
star = li.xpath('.//div[@class="star clearfix"]//text()')
we_star = ''.join([x.strip() for x in star])
# 简介
jj_p = li.xpath('.//div[@class="info"]//p/text()')
复制
转换成DataFrame格式,限制爬取速度,防止爬取的太快对网页造成负担,然后以csv的格式进行保存。
data = pd.DataFrame({'书名': [we_title], '纸质版价格': [ft], '作者/编译/出版社/出版时间/定价': [cbs_pub], '评分': [we_star], '简介': [jj_p]})
df = pd.concat([df, data])
time.sleep(2)
#保存数据
df.to_csv('图书.csv', encoding='utf-8', index=False, mode='a')
复制
创建主函数,放入请求函数、提取数据和保存数据函数。
def main(page):
resposn_ = resposn(page)
lists(resposn_)
复制
启动主函数,循环放入数值进行翻页操作。
if __name__ == '__main__':
for page in range(0, 60, 20):
main(page)
复制
小结
1、本文基于Python,利用python爬虫模块,实现爬取图书基本信息数据并保存下来。
2、本文只要讲解如何去掉爬取的内容中一些杂乱字符。
3、有不足之处还请多多指教。