哈喽,大家好,今天我将和你一起研读CV领域中一篇2021 CVPR的论文《SiamMOT: Siamese Multi-Object Tracking》,该篇论文由Amazon亚马逊研究团队发布。我将按照论文内容格式,给大家梳理论文中每一部分的内容精华。闲言少叙,我们进入正题:
第一部分:Abstract
作者聚焦于在线多目标跟踪,因而提出了基于region的Siamese Multi-object Tracking network(连体多目标跟踪网络),简称:SiamMOT。SiamMOT包含一移动模型(motion model),该模型估计两帧之间实例的移动,从而关联检测到的实例(instances)。作者为了探索移动模型如何影响其跟踪能力,引入了两种连体跟踪器(Siamese tracker)的变体,一种是隐式地对移动建模,另一种是显示地对移动建模。整个消融研究(ablation study)基于三个数据集,分别是:MOT17, TAO-person 以及 Caltech Roadside Pedestrians。实验结果表明,SiamMOT算法高效,且基于单个GPU,在720P的视频中检测速度达到17FPS。
【个人观点:目前目标检测领域的算法基本上是两种类型:one-stage 和 two-stage,典型的one-stage算法有YOLO系列,SSD系列,典型的two-stage算法有RCNN系列。本篇论文中的SiamMOT基于Faster RCNN进行改进,主要是对移动目标检测算法进行了创新。现在,在目标检测与识别算法领域,挑战点仍然有很多,比如:小目标,密集目标,快速移动目标,畸变环境下的目标等等。】
第二部分:Introduction
在多目标跟踪领域,早期做法是基于离线的图化来解决。近期,一些在线跟踪算法专注于提升连续帧(consecutive frames)上的本地连接,而不是构建离线图(offline graph)以跨较大的时间间隙重新标识实例。
SiamMOT整合了基于region的检测网络(Faster RCNN)和两个移动模型(隐式移动模型IMM 和 显示移动模型EMM),开发了显示的模板匹配(template matching)来预估实例移动(instance motion),这对于具有挑战性的跟踪场景(例如快速移动)更加具有鲁棒性(robust)。
【个人观点:快速移动目标的检测,其实YOLO v4就已经做的非常好了,速度和准确性都很高。不过,本篇论文中的算法SiamMOT仍然值得我们好好研究一番。】
第三部分:Related work
1. Siamese trackers in SOT (单目标跟踪的连体跟踪器)
SOT(Single object tracking)通常是指对第一帧图片中感兴趣目标的跟踪,SOT通常会为感兴趣的目标移动直接建模,预测其移动轨迹。连体跟踪器(siamese tracker)对一组帧(frames)进行操作,其目标是通过匹配跟踪在第一帧上的目标物体,以及在第二帧上的搜索区域(search region)。这里需要注意连体跟踪器(siamese trackers)与连体网络(siamese networks)的区别: 前者学习一个匹配函数(matching function),后者通常学习两个检测实例之间的关联函数(affinity function)。
2. Tracking-by-Detection in MOT(多目标跟踪的跟踪检测)
(1)Online MOT : 聚焦于精确的局部关联,而非全局最优关联。
(2)概率框架(probabilistic framework) : 一种寻找轨迹的多变期望最大化算法。
(3)马尔科夫决策过程和强化学习;
(4)SORT(simple object and realtime tracking) : 快速在线实例关联
3. Motion modelling in SORT(基于SORT移动建模)
原始的SORT仅使用通用的跟踪特征(位置,box形状,等),之后,引入了视觉特征。Tracktor利用两阶段检测器从前一个人的位置回归到当前帧;中心轨迹(center-track)采用轨迹分支来回归帧之间对象中心的位移。
【个人观点:这部分提及的一些算法,我是没有听过的,CV领域太广,很难每一个方面都深入研究、学习、掌握,路漫漫,我还需要持续积累。】
第四部分:SiamMOT: Siamese Multi-Object Tracking(连体多目标跟踪)
SiamMOT构建于Faster-RCNN目标检测器之上,Faster-RCNN由RPN和region-based 检测网络构成。SiamMOT增加了region-based Siamese tracker(连体跟踪器)用于实例阶段移动的建模。
如图-01所示(SiamMOT示意图):
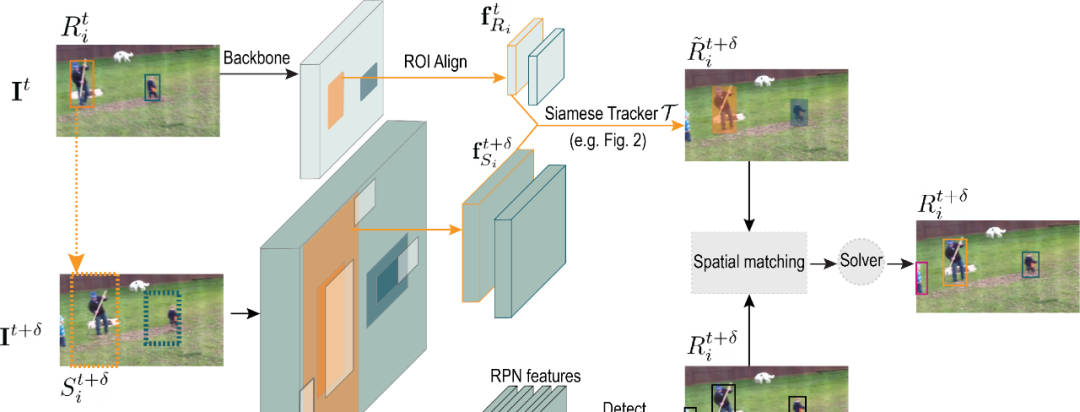
如图所示,在t时刻,SiamMOT将两帧(I_t, I_t+1)和一组检测实例(R_t = {R_t_1, ... , R_t_i, ...)作为输入,检测网络的输出是一组检测实例(R_t+δ),同时,检测器传播R_t到(t+δ)时刻,生成~R_t+δ。我们看一段论文中的原文解释:
如图-02所示:

1. Motion modelling with Siamese tracker(使用Siamese跟踪器进行移动建模)
SiamMOT会在时刻t给定的检测实例i的情况下,Siamese跟踪器会在I_t帧位置处的上下文窗口中第I_t+δ帧处搜索指定实例。
公式如图-03所示:
参数解析:【由于这些公式不好编辑,这里截取部分公式解释】
如图-04所示:
SiamMOT 架构允许这些操作并行运行,并且只需要计算一次主干特征,从而提高在线跟踪推理效率。
2. IMM(Implicit motion model 隐式的移动模型)
IMM使用MLP隐式地估计两帧之间的实例移动(或目标移动)。
这里我们看一下Loss公式,截取论文中部分内容:
如图-05所示:
3. EMM(Explicit motion model 显示的移动模型)
EMM使用channel-wise cross-correlation operator (*) 来生成pixel-level reponse map r_i,这在建模密集光流预估过程中和实例级移动预估过程中非常有效。
这里我们看一下Loss公式,截取论文中部分内容:
如图-06所示:
EMM 在两个方面改进了 IMM 设计。首先,它使用与通道无关的相关操作来允许网络显式地学习连续帧中相同实例之间的匹配函数。其次,它实现了一种更细粒度的像素级监督机制,这对于减少与干扰项错误匹配的情况很重要。
4. Training and Inference
以端到端的方式进行训练,损失函数由三部分构成:如图-07所示:
公式解析:如图08所示:
【个人观点:这部分内容主要对IMM和EMM两种算法模型进行了详细介绍,IMM和EMM分别采用了时间步紧邻的帧进行feature map提取,并进行spatial matching融合,EMM整体上由于IMM。这部分内容比较细,由于个人能力有限,无法完全理解。感兴趣的同学,可以拿论文读。
第五部分:Experimental settings
1. Datasets and Metrics(数据集和衡量指标)
主要基于MOT17,TAO-person,Caltech Roadside Pedestrians (CRP)数据集进行实验。
2. Implementation details(实施细节)
这里分为:Network, Training samples, Training 和 Inference。【详细看论文】
Network部分如图-09所示:
第六部分:Ablation analysis(消融分析)
(1)Results on MOT17 train, Caltech Roadside Pedestrians and TAO-Person datasets.
如图-10所示:
(2)Effects of sampled triplets for training forward tracker in SiamMOT. P / N / H are positive / negative / hard training triplet.
如图-11所示:
(3)Results of SiamMOT inference that terminates active trajectories after they are unseen within τ consecutive frames.
如图-12所示:
第七部分:Comparison to State-of-the-art
将我们的 SiamMOT 与最先进的模型进行比较(三个具有挑战性的多人跟踪数据集:MOT17、TAO-person 和 HiEve):
(1)Results on MOT17 test set with public detection.
如图-13所示:
(2)HiEve benchmark leaderboard (public detection)
如图-14所示:
(3)Results on TAO-person validation set
如图-15所示:
论文下载地址:
https://arxiv.org/pdf/2105.11595.pdf
项目开源地址:
https://github.com/amazon-research/siam-mot