flink-DataStream API
- stream执行环境
- DataStream转换
-
- RichFunction
- Operators
- Flink程序
- 本地运行
- 参考链接
stream执行环境
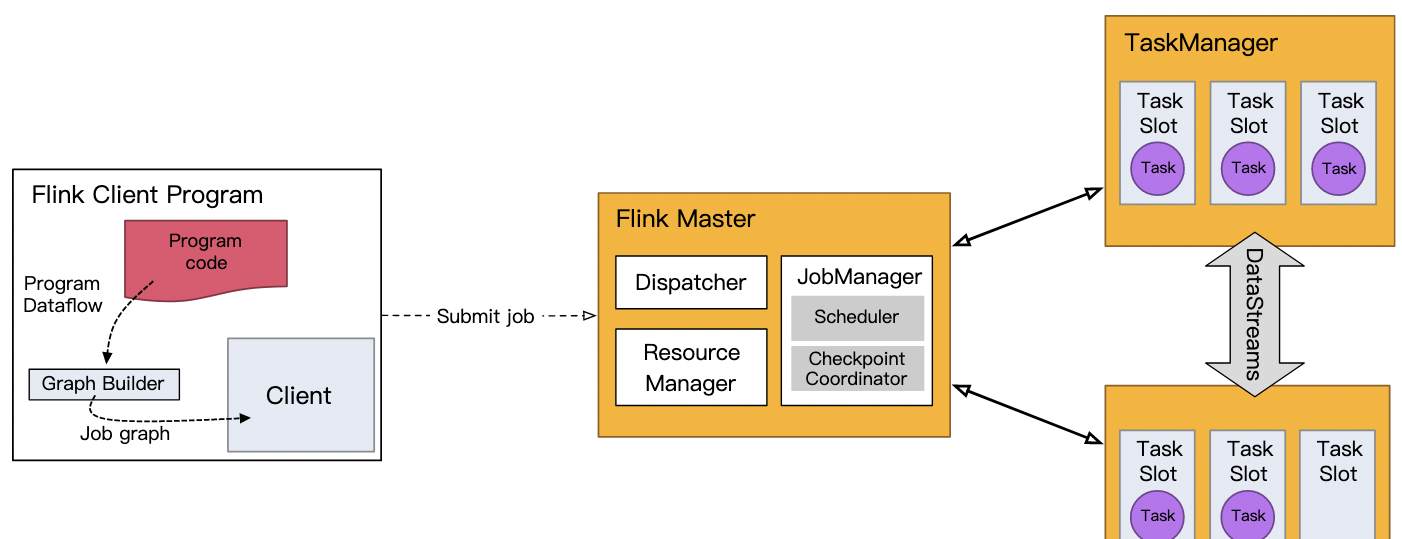
每个 Flink 应用都需要有执行环境,在该示例中为 env。流式应用需要用到 StreamExecutionEnvironment。
DataStream API 将你的应用构建为一个 job graph,并附加到 StreamExecutionEnvironment 。当调用 env.execute() 时此 graph 就被打包并发送到 JobManager 上,后者对作业并行处理并将其子任务分发给 Task Manager 来执行。每个作业的并行子任务将在 task slot 中执行。
如果没有调用 execute(),应用就不会运行。
此分布式运行时取决于你的应用是否是可序列化的。它还要求所有依赖对集群中的每个节点均可用。
DataStream转换
DataStream 是 Flink 流处理 API 中最核心的数据结构。它代表了一个运行在多个分区上的并行流。一 个 DataStream 可以从 StreamExecutionEnvironment 通过env.addSource(SourceFunction) 获得。 DataStream 上的转换操作都是逐条的,比如 map(),flatMap(),filter() 。
下图展示了Flink 中目前支持的主要几种流的类型,以及它们之间的转换关系。

RichFunction
RichFunction中有非常有用的四个方法:open,close,getRuntimeContext 和 setRuntimecontext 这些功能在参数化函数、创建和确定本地状态、获取广播变量、获取运行时信息(例如累加器和计数器)和迭代信息时非常有帮助。
import java.util.Properties
import org.apache.flink.api.common.functions.{IterationRuntimeContext, RichFlatMapFunction, RuntimeContext}
import org.apache.flink.configuration.Configuration
import org.apache.flink.util.Collector
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord}
class KafkaRichFlatMapFunction(topic: String,properites: Properties) extends RichFlatMapFunction[String, Collector[Int]]{
var producer: KafkaProducer[String, String] = null
override def open(parameters: Configuration): Unit = {
// 创建kafka生产者
producer = new KafkaProducer[String, String](properites)
}
override def close(): Unit = {
// 关闭kafka生产者
producer.close()
}
override def getRuntimeContext: RuntimeContext = super.getRuntimeContext
override def setRuntimeContext(t: RuntimeContext): Unit = super.setRuntimeContext(t)
override def getIterationRuntimeContext: IterationRuntimeContext = super.getIterationRuntimeContext
override def flatMap(value: String, out: Collector[Collector[Int]]): Unit = {
//使用RuntimeContext得到子线程ID,比如可以用于多线程写文件
println(getRuntimeContext.getIndexOfThisSubtask)
//发送数据到kafka
producer.send(new ProducerRecord[String, String](topic, value))
}
}
Operators
1.map / flatmap
- 含义:数据映射(1进1出和1进n出)
- 转换关系:DataStream → DataStream
2.filter
- 含义:数据筛选(满足条件event的被筛选出来进行后续处理),根据FliterFunction返回的布尔值来判断是否 保留元素,true为保留,false则丢弃
- 转换关系:DataStream → DataStream
3.keyBy
- 含义: 根据指定的key进行分组(逻辑上把DataStream分成若干不相交的分区,key一样的event会 被划分到相同的partition,内部采用hash分区来实现)
- 转换关系: DataStream → KeyedStream
- 限制: 可能会出现数据倾斜,可根据实际情况结合物理分区来解决
KeyedStream
- KeyedStream用来表示根据指定的key进行分组的数据流。
- 一个KeyedStream可以通过调用DataStream.keyBy()来获得。
- 在KeyedStream上进行任何transformation都将转变回DataStream。
- 在实现中,KeyedStream会把key的信息传入到算子的函数中。
- 每个event只能访问所属key的状态,其上的聚合函数可以方便地操作和保存对应key的状态
4.reduce / fold
- 分组之后当然要对分组之后的数据也就是KeyedStream进行各种聚合操作啦
- KeyedStream → DataStream
- 对于KeyedStream的聚合操作都是滚动的(rolling,在前面的状态基础上继续聚合),千万不要理解为批处理 时的聚合操作(DataSet,其实也是滚动聚合,只不过他只把最后的结果给了我们)
5.connect / union
- connect之后生成ConnectedStreams,会对两个流的数据应用不同的处理方法,并且双流之间可以共享状态 (比如计数)。
- union 合并多个流,新的流包含所有流的数据。
- union是DataStream → DataStream
- connect只能连接两个流,而union可以连接多于两个流
- connect连接的两个流类型可以不一致,而union连接的流的类型必须一致
6.coMap / CoFlatMap
- 跟map and flatMap类似,只不过作用在ConnectedStreams上
- ConnectedStreams → DataStream
7.split / select / SideOutput
- split
- DataStream → SplitStream
- 按照指定标准将指定的DataStream拆分成多个流用SplitStream来表示
- select
- SplitStream → DataStream
- 跟split搭配使用,从SplitStream中选择一个或多个流
8.物理分区
- rebalance
- 含义:再平衡,用来减轻数据倾斜
- 转换关系: DataStream → DataStream
- 使用场景:处理数据倾斜,比如某个kafka的partition的数据比较多
- rescale
- 原理:通过轮询调度将元素从上游的task一个子集发送到下游task的一个子集
- 转换关系:DataStream → DataStream
- 使用场景:数据传输都在一个TaskManager内,不需要通过网络。
- partitioner
- 转换关系:DataStream → DataStream
- 使用场景:自定义数据处理负载
- 实现方法:
- 实现org.apache.flink.api.common.functions.Partitioner接口
- 覆盖partition方法
- 设计算法返回partitionId
Flink程序
Flink程序由几个基本模块组成:
- 获取执行环境
- 加载/创建初始数据
- 指定数据转换
- 数据接收
- 触发程序执行
1.执行环境
StreamExecutionEnvironment是所有Flink程序的基础。可以使用StreamExecutionEnvironment上的这些静态方法获得:
- getExecutionEnvironment()
- createLocalEnvironment()
- createRemoteEnvironment(String host, int port, String… jarFiles)
通常,只需要使用 getExecutionEnvironment() , 因为这将根据上下文做正确的事,如果你执行程序在IDE或普通Java程序将创建一个本地环境,将执行程序在本地机器上。如果您从您的程序创建了一个JAR文件,并通过命令行调用它,那么Flink集群管理器将执行您的主方法,getExecutionEnvironment()将返回一个在集群上执行您的程序的执行环境。
2.加载/创建初始数据
flink的数据源的来源很丰富,文件,hadoop,kafka等都可以作为数据的来源。flink提供的操作如下:
- readTextFile(path)- TextInputFormat逐行读取文本文件,即符合规范的文件,并将它们作为字符串返回。
- readFile(fileInputFormat, path) - 按指定的文件输入格式指定读取(一次)文件。
readFile(fileInputFormat, path, watchType, interval, pathFilter, typeInfo) -
这是前两个内部调用的方法。它path根据给定的内容读取文件fileInputFormat。根据提供的内容watchType,此源可以定期监视(每intervalms)新数据(FileProcessingMode.PROCESS_CONTINUOUSLY)的路径,或者处理当前在路径中的数据并退出(FileProcessingMode.PROCESS_ONCE)。使用该pathFilter,用户可以进一步排除正在处理的文件。
- socketTextStream - 从套接字读取。元素可以用分隔符分隔
- fromCollection(Collection) - 从Java Java.util.Collection创建数据流。集合中的所有元素必须属于同一类型
- fromCollection(Iterator, Class) - 从迭代器创建数据流。该类指定迭代器返回的元素的数据类型。
- fromElements(T …) - 从给定的对象序列创建数据流。所有对象必须属于同一类型
- fromParallelCollection(SplittableIterator, Class) - 并行地从迭代器创建数据流。该类指定迭代器返回的元素的数据类型。
- generateSequence(from, to) - 并行生成给定间隔中的数字序列
- addSource 自定义数据来源,例如kafka的数据来源就需要调用次方法,addSource(new FlinkKafkaConsumer08<>(…));
3.指定数据转换
参考 Datastream转换
4.数据接收
数据接收器可以从数据源中,也可以到数据源中,即源的操作也可以当做数据的接收器,用于存储,从流入flink的数据也可以流入到kafka中,
- print(); 用户数据的打印
- writeAsText(String path) 数据输入到执行文件中
- addSource 自定义数据接收器
5.触发程序执行
触发执行程序调用 execute()上StreamExecutionEnvironment。根据执行的类型,ExecutionEnvironment将在本地计算机上触发执行或提交程序以在群集上执行。
该execute()方法返回一个JobExecutionResult,包含执行时间和累加器结果。
程序的执行并不是从main方法开始,而是任务从调用execute开发,而前面的数据源,数据转化,都在不同的线程中执行,而后调用execute执行。
本地运行
LocalStreamEnvironment在创建Flink系统的同一个JVM进程中启动Flink系统。如果从IDE启动LocalEnvironment,则可以在代码中设置断点,并轻松地调试程序。
创建和使用LocalEnvironment如下:
val env = StreamExecutionEnvironment.createLocalEnvironment
val LocalSources = env.addSource(/* some source */);
//开始执行
env.execute();
参考链接
https://ci.apache.org/projects/flink/flink-docs-release-1.13/docs/learn-flink/overview/
https://www.cnblogs.com/xiexiandong/category/1748467.html
https://blog.csdn.net/springk/article/details/109383292
https://blog.csdn.net/weixin_30613433/article/details/99507272