flink-DataStream API
- stream執行環境
- DataStream轉換
-
- RichFunction
- Operators
- Flink程式
- 本地運作
- 參考連結
stream執行環境
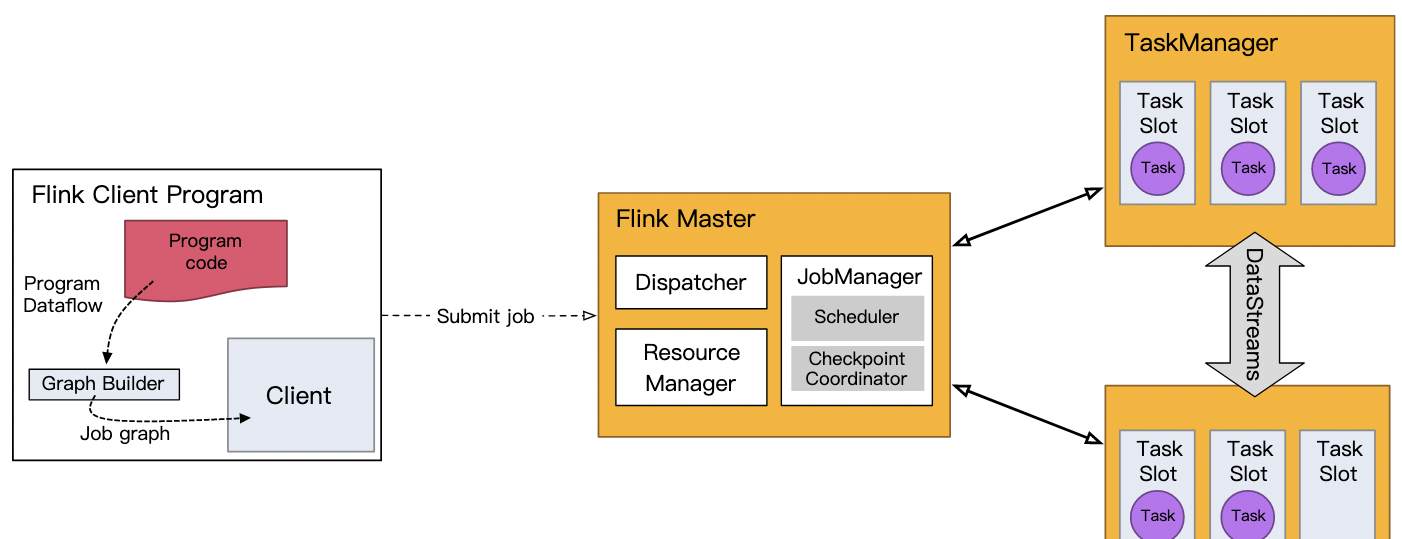
每個 Flink 應用都需要有執行環境,在該示例中為 env。流式應用需要用到 StreamExecutionEnvironment。
DataStream API 将你的應用建構為一個 job graph,并附加到 StreamExecutionEnvironment 。當調用 env.execute() 時此 graph 就被打包并發送到 JobManager 上,後者對作業并行處理并将其子任務分發給 Task Manager 來執行。每個作業的并行子任務将在 task slot 中執行。
如果沒有調用 execute(),應用就不會運作。
此分布式運作時取決于你的應用是否是可序列化的。它還要求所有依賴對叢集中的每個節點均可用。
DataStream轉換
DataStream 是 Flink 流處理 API 中最核心的資料結構。它代表了一個運行在多個分區上的并行流。一 個 DataStream 可以從 StreamExecutionEnvironment 通過env.addSource(SourceFunction) 獲得。 DataStream 上的轉換操作都是逐條的,比如 map(),flatMap(),filter() 。
下圖展示了Flink 中目前支援的主要幾種流的類型,以及它們之間的轉換關系。

RichFunction
RichFunction中有非常有用的四個方法:open,close,getRuntimeContext 和 setRuntimecontext 這些功能在參數化函數、建立和确定本地狀态、擷取廣播變量、擷取運行時資訊(例如累加器和計數器)和疊代資訊時非常有幫助。
import java.util.Properties
import org.apache.flink.api.common.functions.{IterationRuntimeContext, RichFlatMapFunction, RuntimeContext}
import org.apache.flink.configuration.Configuration
import org.apache.flink.util.Collector
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord}
class KafkaRichFlatMapFunction(topic: String,properites: Properties) extends RichFlatMapFunction[String, Collector[Int]]{
var producer: KafkaProducer[String, String] = null
override def open(parameters: Configuration): Unit = {
// 建立kafka生産者
producer = new KafkaProducer[String, String](properites)
}
override def close(): Unit = {
// 關閉kafka生産者
producer.close()
}
override def getRuntimeContext: RuntimeContext = super.getRuntimeContext
override def setRuntimeContext(t: RuntimeContext): Unit = super.setRuntimeContext(t)
override def getIterationRuntimeContext: IterationRuntimeContext = super.getIterationRuntimeContext
override def flatMap(value: String, out: Collector[Collector[Int]]): Unit = {
//使用RuntimeContext得到子線程ID,比如可以用于多線程寫檔案
println(getRuntimeContext.getIndexOfThisSubtask)
//發送資料到kafka
producer.send(new ProducerRecord[String, String](topic, value))
}
}
Operators
1.map / flatmap
- 含義:資料映射(1進1出和1進n出)
- 轉換關系:DataStream → DataStream
2.filter
- 含義:資料篩選(滿足條件event的被篩選出來進行後續處理),根據FliterFunction傳回的布爾值來判斷是否 保留元素,true為保留,false則丢棄
- 轉換關系:DataStream → DataStream
3.keyBy
- 含義: 根據指定的key進行分組(邏輯上把DataStream分成若幹不相交的分區,key一樣的event會 被劃分到相同的partition,内部采用hash分區來實作)
- 轉換關系: DataStream → KeyedStream
- 限制: 可能會出現資料傾斜,可根據實際情況結合物理分區來解決
KeyedStream
- KeyedStream用來表示根據指定的key進行分組的資料流。
- 一個KeyedStream可以通過調用DataStream.keyBy()來獲得。
- 在KeyedStream上進行任何transformation都将轉變回DataStream。
- 在實作中,KeyedStream會把key的資訊傳入到算子的函數中。
- 每個event隻能通路所屬key的狀态,其上的聚合函數可以方便地操作和儲存對應key的狀态
4.reduce / fold
- 分組之後當然要對分組之後的資料也就是KeyedStream進行各種聚合操作啦
- KeyedStream → DataStream
- 對于KeyedStream的聚合操作都是滾動的(rolling,在前面的狀态基礎上繼續聚合),千萬不要理解為批處理 時的聚合操作(DataSet,其實也是滾動聚合,隻不過他隻把最後的結果給了我們)
5.connect / union
- connect之後生成ConnectedStreams,會對兩個流的資料應用不同的處理方法,并且雙流之間可以共享狀态 (比如計數)。
- union 合并多個流,新的流包含所有流的資料。
- union是DataStream → DataStream
- connect隻能連接配接兩個流,而union可以連接配接多于兩個流
- connect連接配接的兩個流類型可以不一緻,而union連接配接的流的類型必須一緻
6.coMap / CoFlatMap
- 跟map and flatMap類似,隻不過作用在ConnectedStreams上
- ConnectedStreams → DataStream
7.split / select / SideOutput
- split
- DataStream → SplitStream
- 按照指定标準将指定的DataStream拆分成多個流用SplitStream來表示
- select
- SplitStream → DataStream
- 跟split搭配使用,從SplitStream中選擇一個或多個流
8.實體分區
- rebalance
- 含義:再平衡,用來減輕資料傾斜
- 轉換關系: DataStream → DataStream
- 使用場景:處理資料傾斜,比如某個kafka的partition的資料比較多
- rescale
- 原理:通過輪詢排程将元素從上遊的task一個子集發送到下遊task的一個子集
- 轉換關系:DataStream → DataStream
- 使用場景:資料傳輸都在一個TaskManager内,不需要通過網絡。
- partitioner
- 轉換關系:DataStream → DataStream
- 使用場景:自定義資料處理負載
- 實作方法:
- 實作org.apache.flink.api.common.functions.Partitioner接口
- 覆寫partition方法
- 設計算法傳回partitionId
Flink程式
Flink程式由幾個基本子產品組成:
- 擷取執行環境
- 加載/建立初始資料
- 指定資料轉換
- 資料接收
- 觸發程式執行
1.執行環境
StreamExecutionEnvironment是所有Flink程式的基礎。可以使用StreamExecutionEnvironment上的這些靜态方法獲得:
- getExecutionEnvironment()
- createLocalEnvironment()
- createRemoteEnvironment(String host, int port, String… jarFiles)
通常,隻需要使用 getExecutionEnvironment() , 因為這将根據上下文做正确的事,如果你執行程式在IDE或普通Java程式将建立一個本地環境,将執行程式在本地機器上。如果您從您的程式建立了一個JAR檔案,并通過指令行調用它,那麼Flink叢集管理器将執行您的主方法,getExecutionEnvironment()将傳回一個在叢集上執行您的程式的執行環境。
2.加載/建立初始資料
flink的資料源的來源很豐富,檔案,hadoop,kafka等都可以作為資料的來源。flink提供的操作如下:
- readTextFile(path)- TextInputFormat逐行讀取文本檔案,即符合規範的檔案,并将它們作為字元串傳回。
- readFile(fileInputFormat, path) - 按指定的檔案輸入格式指定讀取(一次)檔案。
readFile(fileInputFormat, path, watchType, interval, pathFilter, typeInfo) -
這是前兩個内部調用的方法。它path根據給定的内容讀取檔案fileInputFormat。根據提供的内容watchType,此源可以定期監視(每intervalms)新資料(FileProcessingMode.PROCESS_CONTINUOUSLY)的路徑,或者處理目前在路徑中的資料并退出(FileProcessingMode.PROCESS_ONCE)。使用該pathFilter,使用者可以進一步排除正在處理的檔案。
- socketTextStream - 從套接字讀取。元素可以用分隔符分隔
- fromCollection(Collection) - 從Java Java.util.Collection建立資料流。集合中的所有元素必須屬于同一類型
- fromCollection(Iterator, Class) - 從疊代器建立資料流。該類指定疊代器傳回的元素的資料類型。
- fromElements(T …) - 從給定的對象序列建立資料流。所有對象必須屬于同一類型
- fromParallelCollection(SplittableIterator, Class) - 并行地從疊代器建立資料流。該類指定疊代器傳回的元素的資料類型。
- generateSequence(from, to) - 并行生成給定間隔中的數字序列
- addSource 自定義資料來源,例如kafka的資料來源就需要調用次方法,addSource(new FlinkKafkaConsumer08<>(…));
3.指定資料轉換
參考 Datastream轉換
4.資料接收
資料接收器可以從資料源中,也可以到資料源中,即源的操作也可以當做資料的接收器,用于存儲,從流入flink的資料也可以流入到kafka中,
- print(); 使用者資料的列印
- writeAsText(String path) 資料輸入到執行檔案中
- addSource 自定義資料接收器
5.觸發程式執行
觸發執行程式調用 execute()上StreamExecutionEnvironment。根據執行的類型,ExecutionEnvironment将在本地計算機上觸發執行或送出程式以在群集上執行。
該execute()方法傳回一個JobExecutionResult,包含執行時間和累加器結果。
程式的執行并不是從main方法開始,而是任務從調用execute開發,而前面的資料源,資料轉化,都在不同的線程中執行,而後調用execute執行。
本地運作
LocalStreamEnvironment在建立Flink系統的同一個JVM程序中啟動Flink系統。如果從IDE啟動LocalEnvironment,則可以在代碼中設定斷點,并輕松地調試程式。
建立和使用LocalEnvironment如下:
val env = StreamExecutionEnvironment.createLocalEnvironment
val LocalSources = env.addSource(/* some source */);
//開始執行
env.execute();
參考連結
https://ci.apache.org/projects/flink/flink-docs-release-1.13/docs/learn-flink/overview/
https://www.cnblogs.com/xiexiandong/category/1748467.html
https://blog.csdn.net/springk/article/details/109383292
https://blog.csdn.net/weixin_30613433/article/details/99507272