一、前言
很久之前就想写一篇围绕Logistic Regression(LR)模型展开的文章了,碍于时间、精力以及能力有限,时至今日才提笔构思。希望此文能够帮助初学者建立对于LR模型的立体思维,其中关于LR模型本身的理论细节本文不做过多讨论,尽可能的给读者分享与LR模型存在千丝万缕关系的一些模型以及关于LR的一些周边理论,希望笔者的联想能够对于大家有所收获、有所启迪。
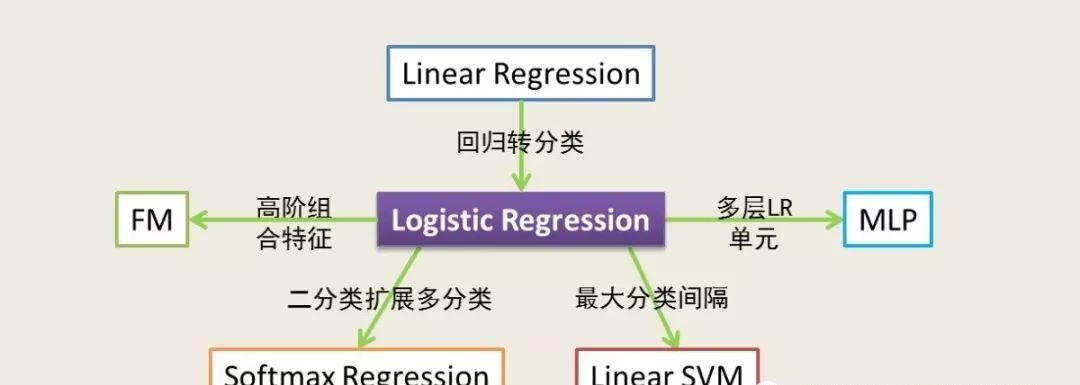
二、简介
LR模型应该是我们接触的第一个机器学习分类模型了吧,由于它存在易于实现、解释性好以及容易扩展等优点,被广泛应用于点击率预估(CTR)、计算广告(CA)以及推荐系统(RS)等任务中。虽然它是线性模型,形式简单、易于建模,但却蕴含着机器学习中一些非常重要的基本思想,同时许多功能强大的非线性模型可通过在线性模型的基础上引入高维映射机制或者层级结构来得到。
因此,我们非常有必要熟悉掌握它,接下来本文将以LR模型为中心展开说明,力争脉络清晰的给大家进行介绍,首先从简单的线性回归(Linear Regression)开始讲起;进而将回归问题经过映射转化为LR分类模型;随后介绍为了学到更好的超平面而采用最大化间隔策略的LinearSVM;紧接着介绍对于LR二分类问题存在的两种意义相同但形式不同的损失函数(Cost Function);然后经由LR二分类问题自然地扩展到Softmax多分类问题,然后介绍对于LR模型的高级版本Factorization Machine以此来捕捉LR模型不能捕捉到的特征与特征间高阶的联系;最后将LR模型看做一层的神经网络,进而延伸成多层感知机模型(MLP)。
机器学习中出现的每个知识点都不服从独立同分布假设,因为每个事物之间都存在微妙的联系,因此我们应该用全局的眼光来看待它们,Everything is related to everything else。
三、数学符号
给定数据集

,其中
,
or
。可以看出数据集共有
个样本,每个样本有
个属性。我们可以通过
的取值范围来判断我们的任务
是一个分类还是一个回归任务,若
是连续空间,则为回归;若
是离散空间,则为分类任务。对于线性模型,一般用向量形式表示为
,其中
。因此,确定了
和
也就确定了学习函数
。
四、正文
让我们先从线性回归这个经典而又简约的模型开始。犹记得高中数学课本某个角落有一章中简单介绍了一下线性回归,当时只记住了一些概念,不确定性关系、回归分析及相关关系等,但具体都是些啥含义,存在哪些实际的应用意义当时一无所知,更由于不是高考提纲重点考察的部分,因此也就大致过了一下,并没有留下太多记忆。很多时候高考中不是重点考察的,但在我们实际生活中却有着非常大的实用价值,直到接触了统计、机器学习、数据挖掘后才渐渐意识到回归问题的魅力,那让我们先从简单明了的线性回归开始吧。
3.1 Linear Regression
先放上Wikipedia上对于线性回归的解释:
线性回归(Linear regression)是利用称为线性回归方程的最小二乘函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析。
大家都知道,线性回归是通过学习一条直线
(为了画图方便,我们样本的特征只考虑一维即
),使得学习到的这条直线尽可能的拟合所有能看到的点(观测数据),并且尽可能的对于未看到的数据(测试数据)也能在这条直线上(泛化能力)。
那么,如何确定这条直线,使得它尽可能的拟合所有观测到的数据点呢?这就可以转换为一个优化问题了,因此我们可以通过让均方误差最小化,即
其中,均方误差有很好的几何意义,它对应于常用的欧氏距离(Euclidean distance)。基于均方误差最小化进行模型求解的过程称为“最小二乘法”(Least square method)。最小二乘法试图找到一条直线,使得所有观测数据点到这条直线的距离之和最小。
求解
和
使得误差最小的过程,称为线性回归模型的最小二乘法“参数估计”。
- 第一种方法:分别将
对于
和
求导,令两个式子为0,即可得到最优的闭式解。
- 第二种方法:分别求
和
对于
的偏导,然后应用梯度下降法来更新,最后可得到它们的局部最优迭代解。
刚才的两种解法是对于特征维度是1维的情况,接下来我们扩展到多维的任务(其中将
也归到了参数列向量
中,因此数据矩阵
的每一行数据样本新增首位元素设为1),我们可以用矩阵来表示
。
然后对
求偏导,并令它等于零即可得到所求的
:
所得到的
也叫做正规方程。注意,在对矩阵求偏导的过程中需要用到以下结论。
总结:至此,我们对于特征是1维的情况给出了两种解决方法--闭式解与迭代解,同时对于特征是多维的情况,我们给出了正规方程的解法,其实对于多维的情况,我们更愿意用迭代解的方法去进行求解,因为在数据量大的情况下,求解矩阵的逆是非常耗费时间的。这里值得注意的是,数据点的颜色都是用蓝色表示的,所以它不存在类别的区分,只存在数值的区分,反映在坐标轴上也就是高低的差距。可以说,线性回归是逻辑回归的基模型,两者都属于广义的线性模型。
3.2 Logistic Regression
刚才提到线性回归的数据点只用一种颜色表示就行,因为它不存在类别的区分,但对于有类别区分的数据,我们的任务就从回归转为分类任务了。如下图所示,跟线性回归最明显的差异是,现在同样是需要一条直线,但不是去拟合每个数据点,而是把两种不同颜色的数据点区分开。
那么如何将已有的
值进行二值化呢?最简单的思路是:对于
值添加一个阈值,如果大于这个阈值就是1,小于这个阈值就是0。这种方式其实就是在外边套上一个“单位阶跃函数” 或者符号函数
,但由于存在不连续的缺点,因此我们不常用这种方法。
我们想,如果能有一个连续的函数同样能够近似单位阶跃函数的功能那该多好,于是对数几率函数(logistic function)派上用场
。其中,sigmoid函数的图像如下图。
这样就可以将一个回归任务连续的
值映射到一个0-1之间的连续值,进而我们再根据阈值来判断它是0还是1。
如何求分类任务的最优解呢?第一个直接的想法是仍然沿用上述的均方误差来表示真实样本与预测值之间的差距,
可以看出这个损失函数不是凸函数,因此很难去进行优化。于是我们接着转换思路,既然是分类任务,那么我们可以对于每个类别分别取计算它们各自的损失呀。对于真实标记是1的样本,我们希望预测值越接近于1,损失越小;对于真实标记是0的样本,我们希望预测值越接近于0时损失越小,
函数正好满足以上情况,见下图:
于是转为交叉熵损失:
所以整个数据集的全部损失为:
那么,如何求得最优的w和b参数呢,答案当然是梯度下降算法,
最后发现交叉熵的更新迭代与最小二乘法是一样的形式。
对于以上结果,我们可以从概率的角度来进行解释,我们可以把
看做是类别分为1的概率,所以
则看做类别为0的概率,那么,似然函数为:
对于似然函数取对数得:
可以看出,这个方程跟上文提到的交叉熵损失函数一样,只是相差一个符号,因此对于每个类别,我们同样可以从概率的角度来进行解释。
总结:如果说线性回归是对于特征的线性组合来拟合真实标记的话(
),那么逻辑回归是对于特征的线性组合来拟合真实标记的对数几率(
)。
3.3 Linear SVM
对于LR模型来说,它希望求得的直线能够把两种类别的数据区分开,换句话说,只要给我分对了就行,因此这种机制的分类方法泛化能力会有些欠缺。因此人们接着思考,如何才能更好的找到这个超平面,使得它既能对观测数据能够很好区分,同时能够对未观测到的数据也能很好的预测呢。
于是人们想到一个方法,既然我需要找一个最优超平面(或者直线),那么我先看一下观测数据中距离最近的点所构成的直线(支持向量),然后我把它们两条直线的距离取中间位置,然后画一条线不就得了,这就是SVM的朴素思想。正因为如此,它才更具有泛化能力,如下图所示,如果是LR模型的话很可能将遇到的新数据(图中圆圈内的紫色数据点)分为青色,而对于SVM来说,由于找到了更好的超平面,所以能够正确的将它分为紫色。
SVM寻找支持向量以此来最大化间隔来进行建模的思想反映到用语言表述的损失函数上就是:
确定了损失函数,那么接下来,第一件事就是找支持向量到超平面的间隔(数据点距离超平面最近的点所构成的直线与超平面的距离),于是
所有数据点分类正确为:
,所以,损失函数的数学形式为:
由于对于
的放缩不影响解,为了简化优化问题,我们约束
使得
因此可以得到SVM的基本型:
由于现在这个目标函数是二次的,约束条件是线性的,所以可以通过调用现成的QP包来进行求解。但由于这个问题比较特殊,我们可以通过拉格朗日对偶性来变换成对偶变量的优化问题,即通过求解与原问题等价的对偶问题得到原始问题的最优解,这就是线性可分条件下SVM对偶算法,有点在于:一来对偶问题往往更容易求解,二来可以自然引入核函数,进而推广到线性不可分数据的情况,通过映射到高维来进行线性区分。至于对偶函数的求解需要用到KKT条件,以及核函数来进行高维映射的问题不在本文的讨论范围内,预知其详,请参见西瓜书。
总结:LR模型和SVM模型都是对于分类任务进行求解最优的超平面,只不过LR模型侧重降低所有观测数据点的损失,而SVM侧重于支持向量中的数据点的分类损失。两种建模思想的不同之间反映在了损失函数上,可以把SVM看做是LR模型的进阶版,由于采用了最大化间隔的思想,可以学到比LR泛化能力更强的超平面,同时由于SVM损失函数特有的结构,使得可以巧妙的应用核函数技巧来将线性不可分的数据映射到高维进而实现线性可分,同时核函数将特征映射与内积两步运算压缩为一步,大大降低了复杂度。因此,可以将SVM看做是采用简单内积方式核函数的LR模型。
3.4 LR的两种不同损失函数
平时在阅读文献的时候经常会看到对于二分类任务的两种不同形式的损失函数,分别是交叉熵损失和log损失(为了表示的简单,将参数b也归到了w中),一直很纳闷,这两种形式的损失函数表达的意义是否一样。
交叉熵损失为:
其中
最后,自己简单证明了一下才消除了心中的疑惑。
证明:
①当log损失函数中
时,
,对应于交叉熵损失中
的情况。
②当log损失函数中
时,
,对应于交叉熵损失中
的情况。
总结:无论是交叉熵损失还是log损失,都是对于二分类任务进行损失建模的函数,虽然形式不同,但意义却相同,只不过对应的类标签不同罢了,一个是0/1,一个是
,仅此而已。
3.5 Softmax Regression
刚才我们都是处理的二分类任务,但现实世界中存在许多的多分类任务,比如手写数字识别任务。因此,我们很自然的想法是将二分类扩展到多分类任务中。
其中,一种简单的想法是one vs all。主要思路为:将多分类任务转换为多个二分类任务,只不过我们需要训练若干个分类器(有多少类别对应多少分类器)。对于每个二分类模型,将其中一个类别当做正例,其余所有其他的类别样例当做负例(图片来自Andrew NG课件)。这种方法存在一个问题,就是对于一个任务我们需要训练若干次二分类模型,时间复杂度高;同时我们将一个多分类任务分成多个独立的子任务来进行建模可能会有失精度。
因此,我们还是想对于多分类任务进行直接建模,而不用将其进行拆解。于是Softmax多分类闪亮登场。Sotxmax Regression其实是对于Logistic Regression的延伸,具体证明请看接下来的陈述。
首先看一下Softmax它的形式:
其中
为
对应的类标,一共有
个标签。从中我们可以看出,其实就是对于多个结果进行归一化的操作。其实LR模型同样是对于两个类别结果的归一化,因为
,所以没有显示进行归一。那么问题来了,为啥要用指数形式的归一化,而不是简单的
,因为我们在归一化的过程中需要属于每个类别的比率要大于0(你不能说一个样例属于某个标签的概率是负的吧),正因为指数形式的归一化既能达到全部加起来为1的效果(归一化),又能保证每个分量大于0(满足概率解释),因此遂得此形式。
接下来我们将Softmax Regression的类别个数
设为2,看能否推导出跟Logistic Regression一样的表达形式。在进行证明之前先给出Softmax Regression的overparameterized特性的证明。
可以看出,从
中减去一个值
不会改变预测的结果,这就是Softmax回归参数的过参数化特性(overparameterized),在接下来的证明Logistic Regression其实是Softmax Regression
的特例的过程中会用到这个属性。
证明:
当
时,令
,因此Softmax回归分别对应于类别1和0的概率表示为:
为啥跟我们经典的LR模型的sigmoid函数不一样呢,别急,接下来,我们利用overparameterized特性来对
进行推导:
令
得:
同理,我们对
进行推导得:
令
得:
总结:至此,我们推导出了Softmax Regression当
时,与Logistic Regression形式完全一样的形式,因此Softmax Regression是Logistic Regression在多分类任务中的扩展。
3.6 Factorization Machine
对于LR模型来说,它只能捕捉到特征之间线性的组合信息,然后用权重加以区分它们的重要程度。然而在现实世界中,单独考虑两个独立的特征可能并没有什么联系,相反把两个特征结合起来会有明显的相关性,因此特征之间往往存在某种隐隐约约的联系,所以我们不能简简单单的把所有任务都直接建模成所有特征的线性组合。虽然我们可以手工进行特征工程来建模特征之间的联系,但如果特征维度过大,会浪费大量的人力,物力,基于以上考虑,于是Rendle在2010年提出了FM框架来自动建模特征与特征之间的复杂联系。
先声明一点,FM是一个整体框架,它其实可以用在分类、回归以及排序等任务中。然而本文重点关注在它有能力对于特征之间的联系进行自动建模,因此将以二分类任务来进行介绍。
对于LR模型来说,它是对于现有特征的线性组合:
为了捕捉特征与特征之间的高阶联系,最直观的想法是用嵌套循环来对所有的特征进行两两组合,新的组合特征用权重
来区分各自的重要性:
写成矩阵的形式为:
这样一来,就能够对于所有的二阶组合特征进行建模,并且模型可以自动学习组合特征的权重,解放了人工特征工程的繁琐。但它会存在一个问题,真实的推荐系统或者点击率预估任务中的特征维度
一般非常大,因此用二维矩阵
来建模的话,复杂度为
,会非常消耗空间。于是人们接着对
进行优化,既然
矩阵的维度比较大,那么可以用矩阵分解的方式(此处借鉴了推荐系统中的MF,更多MF细节可以看我的推荐系统从入门到接着入门)来进行降维操作啊,于是将它分解为
,其中
,因此,FM的表达形式为:
接下来接着思考,我们用两个小矩阵来代替大权重矩阵
,虽然存储空间降下来了,但计算复杂度仍然是
,巧合的是,这种形式的FM经过推导,时间复杂度可以降低到
,具体推导过程见下图:
可以看出,经过推导,上述两层嵌套循环可以转换为一层循环,大大降低了计算复杂度。
总结:FM模型是LR模型在特征组合方面的扩展,它不仅保存了特征的线性组合因素,而且还可以自动捕捉特征与特征之间高阶的联系因素,同时它巧妙的将存储空间与时间消耗从
降低到了线性的复杂度
,并且可以应对SVM应对不了的特征非常稀疏的情况,可以说该模型的思想值得我们每个人学习与借鉴。
3.7 Multiple Layer Perceptron
对于LR模型来说,我们可以把它看做拥有一个隐层的神经网络。注意此处的
为标量,代表的是样本的某一维度特征。我们可以把每个样本的维度当做输入层的节点(共有6个特征),要学习的权重我们用
表示,偏置用
来表示,输出层的激活函数用sigmoid函数(见下图)。
对于多层感知机(本文以三层为例,输入层-隐藏层-输出层)来说,可以看做是多层的LR模型的结合,并且每一层可以看做是多个LR模型的集合(见下图)。可以看出存在两层激活函数层,并且第二层是三个LR模型的结合(三种不同颜色进行区分)。
那么问题来了,对于一层非线性激活函数的LR模型来说,我们可以应用梯度下降来进行模型求解。但对于多层感知机来说,它存在两层非线性激活函数,最后一层可以应用梯度下降来进行优化,但隐藏层不存在直接的误差,那怎么优化呢?答案当然是可以,方案是对误差进行反向传播,将链式法则应用到梯度下降算法中,具体的可参考我的这篇文章《反向传播之我见》。在此不做过多介绍。
总结:我们可以把LR模型看做拥有一层非线性激活函数的神经网络,那么多层感知机可以看做是对于LR模型的集合。
五、总结
本文围绕Logistic Regression展开,介绍了它存在的两种形式不同但意义相同的损失函数,前向回顾了它与Linear Regression的关系,后向介绍了它与Softmax Regression以及Linear SVM的关系,同时延伸了它与Factorization Machine的联系以及它与Multiple Layer Perceptron的关联,旨在给自己建立一个相对系统的知识体系。现在将它整理成此文,对自己来说是个总结,同时也希望能够对大家有那么一点帮助,由于行文匆忙,难免会有些错误,希望大家不吝赐教。
参考文献
- 周志华. 机器学习 : = Machine learning[M]. 清华大学出版社, 2016.
- Rendle, Steffen. "Factorization machines." Data Mining (ICDM), 2010 IEEE 10th International Conference on. IEEE, 2010.