Logistic回归的目的是寻找一个非线性函数Sigmoid的最佳拟合参数,求解过程可由最优化算法来完成,一般采用梯度上升算法,此算法又可简化为随机梯度上升算法。简化前后的算法效果相当,但占用更少的计算资源。并且随机梯度上升算法是一个在线算法,可在新数据到来时就完成参数的更新,而无需重新读取整个数据集来进行批处理。机器学习的一个重要问题是处理缺失数据,处理方法取决于实际需求。
假设有一些数据点,可用一条直线对这些点进行拟合(该线称为最佳拟合直线),这个拟合的过程就成为回归。Logistic回归进行分类的主要思想是:根据现有数据对分类边界线建立回归公式,以此进行分类。
训练分类器用于寻找最佳拟合参数,也称为最佳的分类回归系数。Logistic需要距离计算,因此要求数据类型为数值型,结构化数据格式最佳。
海维赛德阶跃函数(Heaviside step function)也称为单位阶跃函数,此函数的问题在于在跳跃点上从0瞬间跳跃到1,这很难处理。而Sigmoid函数,也具有类似的性质,计算公式如下:
σ(z)=11+e−z
为了实现Logistic回归分类器,可以在每个特征上都乘以一个回归系数,然后把所有的结果相加,将这个总和代入Sigmoid函数中,进而得到一个范围在0~1的数值。大于0.5分入1类,否则归入0类。
Sigmoid函数的输入记为 z ,有下面公式得出:
z=w0x0+w1x1+w2x2+...+wnxn
采用向量写法,上述公式可写成 z=wTx ,其中向量 x 是分类器的输入数据,向量w是要寻找的最佳回归系数。
梯度上升法基于的思想:要找到某个函数的最大值,最好的方法是沿着该函数的梯度方向探寻。如果梯度记为 ∇ ,则函数 f(x,y) 的梯度由下式表示:
∇f(x,y)=⎛⎝⎜⎜⎜∂f(x,y)∂x∂f(x,y)∂y⎞⎠⎟⎟⎟
这个梯度意味着沿 x 方向移动∂f(x,y)∂x,沿 y 方向移动∂f(x,y)∂y。且函数 f(x,y) 在待计算的点上有定义且可微。
梯度算子总是指向函数值增长最快的方向。这里说的是移动方向,而未提到移动量的大小。该量值称为步长,记做 α 。用向量表示,梯度上升法的迭代公式如下:
w:=w+α∇wf(w)
该公式会一直迭代下去,直至达到某个停止条件为止,比如迭代次数达到某个指定值或算法达到某个可以允许的误差范围。
梯度上升法每次更新回归系数时都需要遍历整个数据集,计算复杂度太高。一个改进的方法是一次仅用一个样本点来更新回归系数,该方法称为随机梯度上升算法。由于可以在新样本到来时对分类器进行增量式更新,因此,随机上升算法是一个在线学习算法,并且没有矩阵转换过程,所有变量的数据类型都是NumPy数组。与“在线学习”相对应,一次处理所有数据被称为“批处理”。
随机梯度上升法,回归系数经过大量迭代才能达到稳定值,且在大的波动停止后,仍有小的周期性波动,产生这种现象的原因是存在一些不能正确分类的样本点(数据集并非线性可分)
改进的随机梯度上升算法,改进有两处:1、alpha在每次迭代的时候都会调整,这可缓解数据波动或者高频振动,虽然alpha随着迭代次数不断减小,但永远不会减小到0,这是因为
alpha=4/(1.0+j+i)+0.01
中存在一个常数项。这样多次迭代之后新数据仍然具有一定的影响力。避免参数严格下降也常见有模拟退火算法。2、通过随机选取样本来更新回归系数,可减少周期性波动。
处理数据中的缺失值:1、使用可用特征的均值来填补缺失值;2、使用特殊值来填补缺失值,如-1、0,选择使用0替换所有缺失值,恰好能适用于Logistic回归,0在更新时不会影响系数的值;3、忽略有缺失值的样本;4、使用相似样本的均值填补缺失值;5、使用另外的机器学习算法预测缺失值。
如果在测试数据集中发现一条数据的类别标签已经缺失,可简单将其丢弃。这是因为类别标签与特征不同,很难确定采用某个合适的值来替换。采用Logistic回归进行分类这种做法是合理的,如果采用类似kNN的方法就可能不太可行。
使用的函数
| 函数 | 功能 |
|---|---|
| mat1.transpose() | 求矩阵mat1的转置 |
| mat(dataMat) | 将输入的数据dataMat转换成矩阵 |
plt.xlabel( | 设置x轴的文本 |
plt.ylabel( | 设置y轴的文本 |
| mat1.getA() | 将mat1转化成ndarray数组 |
| random.uniform(x,y) | 随机生成一个实数,它在[x,y]范围内。 |
程序代码
# coding=utf-8
import numpy as np
# 加载数据
def loadDataSet() :
dataMat = []; labelMat = []
fr = open('c:\python27\ml\\testSet.txt')
for line in fr.readlines() :
lineArr = line.strip().split()
dataMat.append([, float(lineArr[]), float(lineArr[])])
labelMat.append(int(lineArr[]))
return dataMat, labelMat
# 阶跃函数--sigmoid()函数
def sigmoid(inX) :
return /(+np.exp(-inX))
# logistic回归梯度上升优化算法
def gradAscent(dataMatIn, classLabels) :
dataMatrix = np.matrix(dataMatIn)
labelMat = np.matrix(classLabels).transpose()
m,n = np.shape(dataMatrix)
# alpha项目表移动的步长
alpha =
# maxCycles迭代次数
maxCycles =
weights = np.ones((n,))
for k in range(maxCycles) :
h = sigmoid(dataMatrix*weights)
error = labelMat - h
# 梯度上升
weights = weights + alpha * dataMatrix.transpose() * error
return weights
# 画出数据集和Logistic回归最佳拟合直线的函数
def plotBestFit(weights) :
import matplotlib.pyplot as plt
dataMat, labelMat=loadDataSet()
dataArr = np.array(dataMat)
n = np.shape(dataArr)[]
xcord1=[]; ycord1=[]
xcord2=[]; ycord2=[]
for i in range(n) :
# 将标签为1的数据元素和为0的分别放在(xcode1,ycode1)、(xcord2,ycord2)
if int(labelMat[i]) == :
xcord1.append(dataArr[i,])
ycord1.append(dataArr[i,])
else :
xcord2.append(dataArr[i,])
ycord2.append(dataArr[i,])
fig = plt.figure()
ax = fig.add_subplot()
ax.scatter(xcord1, ycord1, s=, c='red', marker='s')
ax.scatter(xcord2, ycord2, s=, c='green')
# 绘制出w0 + w1*x + w2*y = 0的直线
x = np.arange(-, , )
y = (-weights[]-weights[]*x)/weights[]
ax.plot(x, y)
# x,y轴显示的文字
plt.xlabel('X1'); plt.ylabel('X2')
plt.show()
# 随机梯度上升算法
# 参数dataMatrix是numpy数组类型数据,传入矩阵,需要np.array(matrix)转换一下
def stocGradAscent0(dataMatrix, classLabels) :
m,n = np.shape(dataMatrix)
alpha =
weights = np.ones(n)
# h,error 都是数值,而非向量,一次仅用一个样本来更新回归系数
for i in range(m) :
h = sigmoid(sum(dataMatrix[i]*weights))
error = classLabels[i] - h
weights = weights + alpha * error * dataMatrix[i]
return weights
# 改进的随机梯度上升算法
def stocGradAscent1(dataMatrix, classLabels, numIter=) :
m,n = np.shape(dataMatrix)
weights = np.ones(n)
for j in range(numIter) :
dataIndex = range(m)
for i in range(m) :
# alpha每次迭代时需要调整,缓解数据波动或者高频振动
alpha = /(+j+i) +
# 随机选取更新
randIndex = int(np.random.uniform(, len(dataIndex)))
h = sigmoid(sum(dataMatrix[randIndex]*weights))
error = classLabels[randIndex] - h
weights = weights + alpha * error * dataMatrix[randIndex]
del(dataIndex[randIndex])
return weights
# inX, 输入的特征向量
# weights, 回归系数
def classifyVector(inX, weights) :
prob = sigmoid(sum(inX*weights))
if prob > : return
else : return
# 打开测试集和训练集(患疝病的马的存货问题),使用测试集进行500迭代的Logistic回归,
# 计算出回归参数,并根据测试集,得出训练模型的错误率
def colicTest() :
# 打开测试集和训练集
frTrain = open('c:\python27\ml\\horseColicTraining.txt')
frTest = open('c:\python27\ml\\horseColicTest.txt')
trainingSet = []; trainingLabels = []
for line in frTrain.readlines() :
currLine = line.strip().split('\t')
lineArr = []
for i in range() :
lineArr.append(float(currLine[i]))
trainingSet.append(lineArr)
trainingLabels.append(float(currLine[]))
trainWeights = stocGradAscent1(np.array(trainingSet), trainingLabels, )
errorCount = ; numTestVec =
for line in frTest.readlines() :
numTestVec +=
currLine = line.strip().split('\t')
lineArr = []
for i in range() :
lineArr.append(float(currLine[i]))
if int(classifyVector(np.array(lineArr), trainWeights)) != int(currLine[]) :
errorCount +=
errorRate = (float(errorCount)/numTestVec)
print "the error rate of this test is: %f" % errorRate
return errorRate
# 执行10次colicTest()并返回平均值
def multiTest() :
numTests = ; errorSum =
for k in range(numTests) :
errorSum += colicTest()
print "after %d iterations the average error rate is: %f" \
% (numTests, errorSum/float(numTests))
在命令行中执行:
>>> import ml.logRegres as logRegres
>>> dataArr,labelMat=logRegres.loadDataSet()
>>> logRegres.gradAscent(dataArr,labelMat)
matrix([[ ],
[ ],
[- ]])
# 画出数据集和决策边界(Logistic回归最佳拟合直线),生成的图,如末尾图1
>>> import ml.logRegres as logRegres
>>> dataArr, labelMat=logRegres.loadDataSet()
>>> weights=logRegres.gradAscent(dataArr, labelMat)
>>> logRegres.plotBestFit(weights.getA())
# 随机梯度上升算法,绘制的拟合直线,如末尾图2
>>> from numpy import *
>>> import ml.logRegres as logRegres
>>> dataArr, labelMat=logRegres.loadDataSet()
>>> weights=logRegres.stocGradAscent0(array(dataArr), labelMat)
>>> logRegres.plotBestFit(weights)
# 改进的随机梯度上升算法,绘制的拟合直线,如末尾图3,图4
>>> reload(logRegres)
<module 'ml.logRegres' from 'C:\Python27\ml\logRegres.py'>
>>> weights=logRegres.stocGradAscent1(array(dataArr), labelMat)
>>> logRegres.plotBestFit(weights)
>>> weights=logRegres.stocGradAscent1(array(dataArr), labelMat, )
>>> logRegres.plotBestFit(weights)
# 患有疝病的马的存活问题
>>> reload(logRegres)
<module 'ml.logRegres' from 'C:\Python27\ml\logRegres.py'>
>>> logRegres.multiTest()
the error rate of this test is:
the error rate of this test is:
the error rate of this test is:
the error rate of this test is:
the error rate of this test is:
the error rate of this test is:
the error rate of this test is:
the error rate of this test is:
the error rate of this test is:
the error rate of this test is:
after iterations the average error rate is:
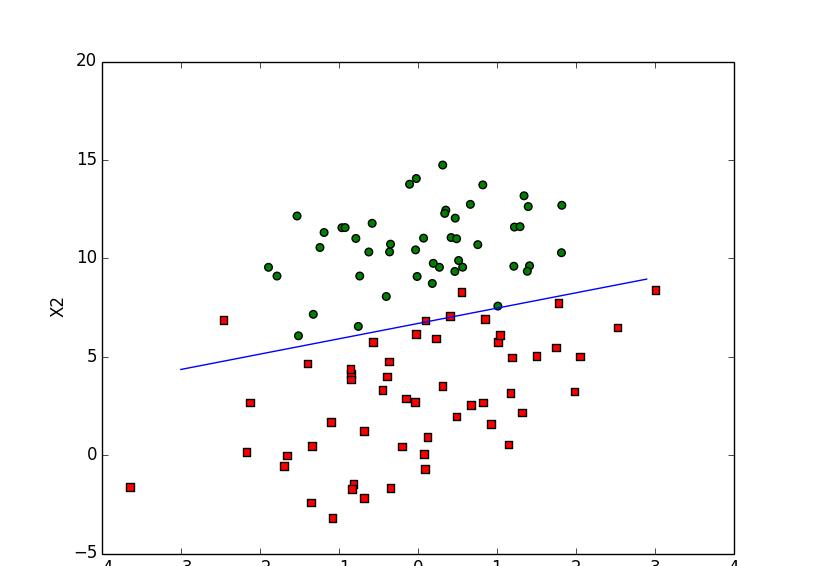
图1 绘制数据集和决策边界

图2 随机梯度上升算法拟合直线
图3 改进的随机梯度上升算法拟合直线(默认迭代150次)
图4 改进的随机梯度上升算法拟合直线(迭代500次)