前言
上一篇内容,已经学会了使用简单的语句对网页进行抓取。接下来,详细看下urlopen的两个重要参数url和data,学习如何发送数据data。我们想做一个百度翻译就需要向百度翻译的服务器发送我们想要翻译的内容。
上一篇我们说过 urllib有几个默认的参数,出了几个默认的参数外 出了url 这次我需要用到一个data
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
urlopen的url参数
url不仅可以是一个字符串,例如:http://www.baidu.com。url也可以是一个Request对象.
urlopen()返回的对象,除了
read()
方法外,还有
geturl()
方法、
info()
方法、
getcode()
方法。、
:返回的是一个url的字符串;geturl()
:返回的是一些meta标记的元信息,包括一些服务器的信息;info()
:返回的是HTTP的状态码,如果返回200表示请求成功。getcode()
urlopen的data参数
我们可以使用data向服务器发送数据,我们这篇要制作的百度翻译就通过data向百度翻译的服务器发送数据,然后或去百度翻译服务器返回的结果。最终将显示出来。
data参数有自己的格式,它是一个基于application/x-www.form-urlencoded的格式,具体格式我们不用了解, 因为我们可以使用urllib.parse.urlencode()函数将字符串自动转换成上面所说的格式。
制作百度翻译
首先使用 Chrome 浏览器打开 百度翻译,这里,我们选择 Chrome 浏览器自带的开发者工具对网站进行抓包分析
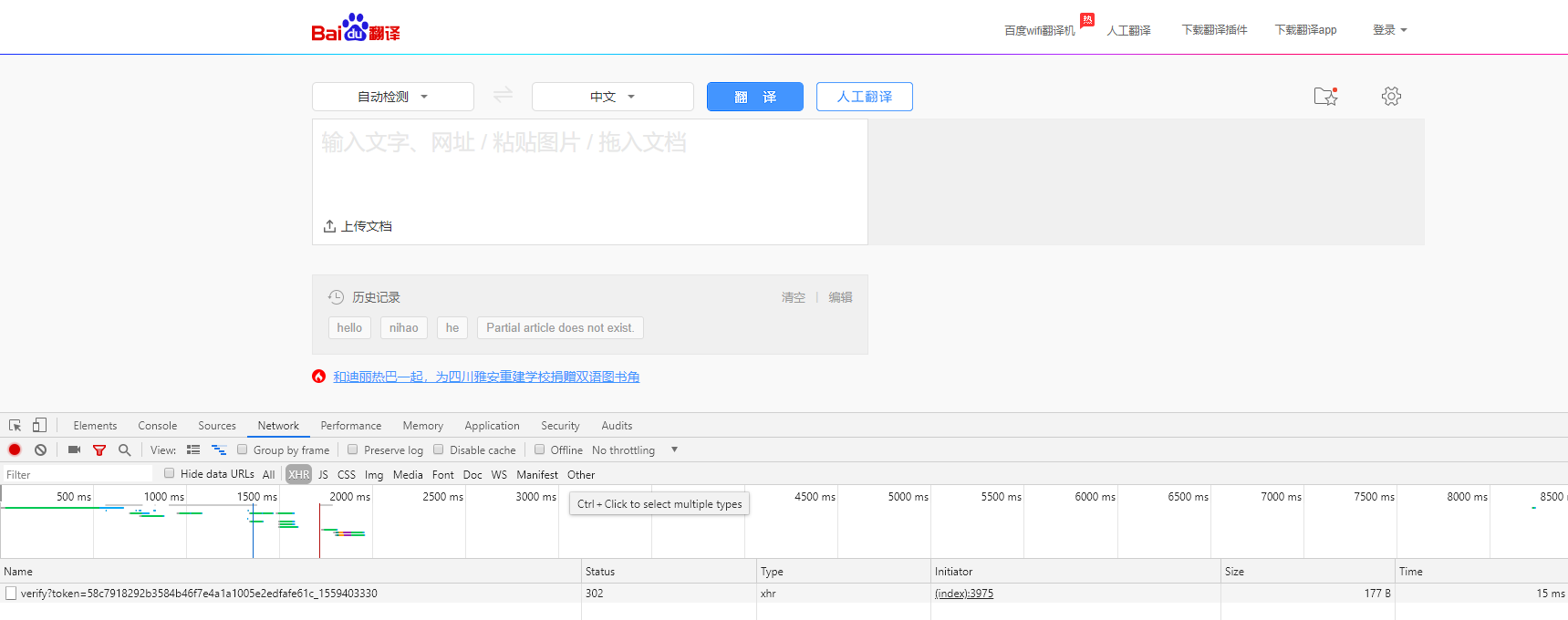
1. 抓包分析
打开 Network 选项卡进行监控,并选择 XHR 作为 Filter 进行过滤
然后,我们在输入框中输入待翻译的文字进行测试,可以看到如下图红色框中的内容
我们主要分析 sug 但是下面有好多sug我们要查看哪一个呢,之所以有这么多sug是因为百度翻译默认开启的是实施翻译,也就是你输入一个字你在打拼音的是时候每按下一个字母他就会翻译一次,直到这个后我们就可以知道,最后一个sug就是我们完整的文字。

我们可以验证一下 点击最下面的那个sug,我们可以看到下图红色框框的内容就是我们请求的URL。
滚到最下面我们可以看到我们输入的翻译内容 “你好”,这个For Data就是发送到百度翻译服务器的内容,然后服务器会返回对应的翻译给带浏览器,最后显示在浏览器上给我们看。
我们还可看到一个 request Headers 中有一个:
user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36
这个user-agent的意思是告诉服务器我使用谷歌浏览器访问的,有些网站会有反爬虫,如果发现你是爬虫访问的就会阻止你,我们只要加上这个user-agent就可以让服务器以为我们是用户通过浏览器访问的
记住上面三个数据,下面我们就要用到。
直接上完整代码
import urllib.request
import urllib.parse
import json
# 请求的网址
Request_URL = "https://fanyi.baidu.com/sug"
while True:
text = input("翻译内容")
#表单数据(需要翻译的内容)
Form_Data = {
"kw": text
}
#创建一个User-Agent
head = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36"}
#使用urlencode方法转换标准格式
data = urllib.parse.urlencode(Form_Data).encode('utf-8')
# 构造请求对象
req = urllib.request.Request(Request_URL,data,head)
# 发送请求,获得响应
req = urllib.request.urlopen(req)
# 获取服务器响应数据
req_data = req.read().decode("utf-8")
#使用json解析数据
html = json.loads(req_data)
#找到想要的结果
results = html['data'][0]['v']
#打印结果
print(results)
最终效果
如果还想要具体一点的结果可以使用 正则或者
split()
方法 这里就不详细说明了。
结语
如果还想增加一点难度,可以试一试有道翻译 方法类似,有兴趣的话可以自己尝试一下。