前言
上一篇内容,已經學會了使用簡單的語句對網頁進行抓取。接下來,詳細看下urlopen的兩個重要參數url和data,學習如何發送資料data。我們想做一個百度翻譯就需要向百度翻譯的伺服器發送我們想要翻譯的内容。
上一篇我們說過 urllib有幾個預設的參數,出了幾個預設的參數外 出了url 這次我需要用到一個data
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
urlopen的url參數
url不僅可以是一個字元串,例如:http://www.baidu.com。url也可以是一個Request對象.
urlopen()傳回的對象,除了
read()
方法外,還有
geturl()
方法、
info()
方法、
getcode()
方法。、
:傳回的是一個url的字元串;geturl()
:傳回的是一些meta标記的元資訊,包括一些伺服器的資訊;info()
:傳回的是HTTP的狀态碼,如果傳回200表示請求成功。getcode()
urlopen的data參數
我們可以使用data向伺服器發送資料,我們這篇要制作的百度翻譯就通過data向百度翻譯的伺服器發送資料,然後或去百度翻譯伺服器傳回的結果。最終将顯示出來。
data參數有自己的格式,它是一個基于application/x-www.form-urlencoded的格式,具體格式我們不用了解, 因為我們可以使用urllib.parse.urlencode()函數将字元串自動轉換成上面所說的格式。
制作百度翻譯
首先使用 Chrome 浏覽器打開 百度翻譯,這裡,我們選擇 Chrome 浏覽器自帶的開發者工具對網站進行抓包分析
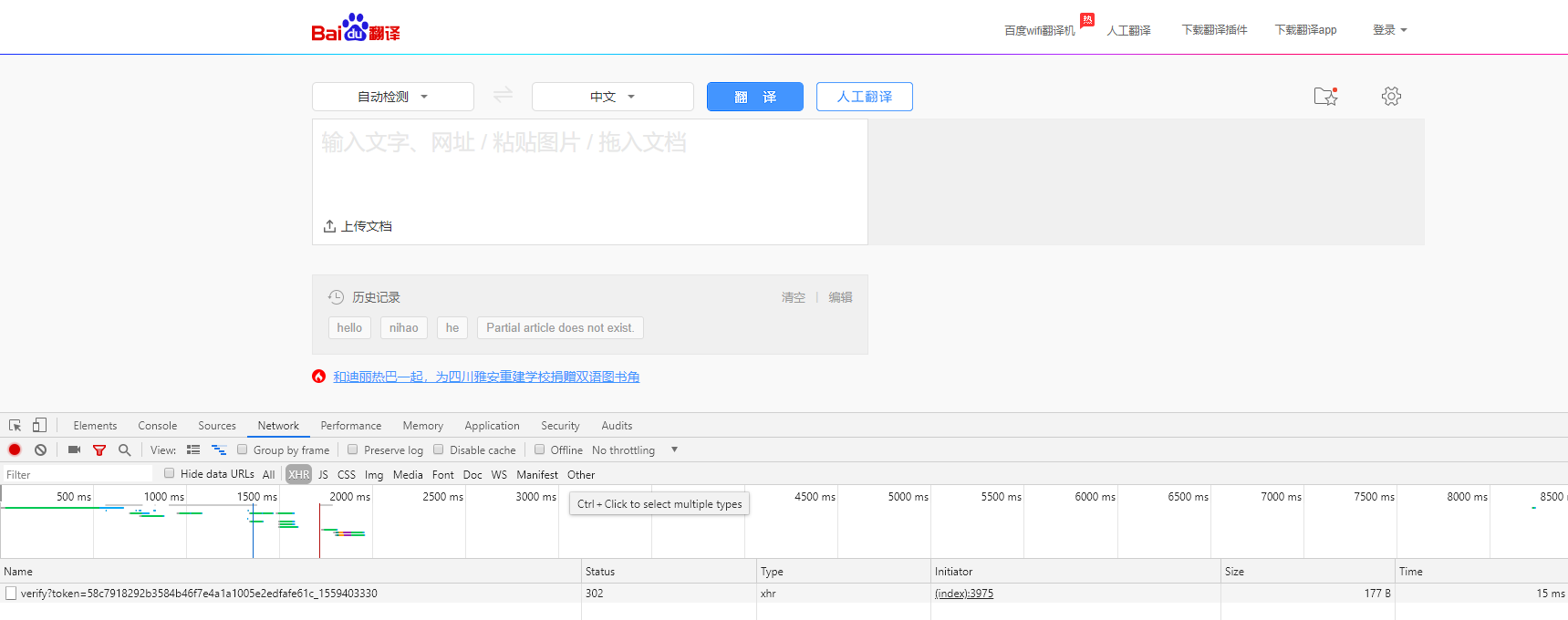
1. 抓包分析
打開 Network 頁籤進行監控,并選擇 XHR 作為 Filter 進行過濾
然後,我們在輸入框中輸入待翻譯的文字進行測試,可以看到如下圖紅色框中的内容
我們主要分析 sug 但是下面有好多sug我們要檢視哪一個呢,之是以有這麼多sug是因為百度翻譯預設開啟的是實施翻譯,也就是你輸入一個字你在打拼音的是時候每按下一個字母他就會翻譯一次,直到這個後我們就可以知道,最後一個sug就是我們完整的文字。

我們可以驗證一下 點選最下面的那個sug,我們可以看到下圖紅色框框的内容就是我們請求的URL。
滾到最下面我們可以看到我們輸入的翻譯内容 “你好”,這個For Data就是發送到百度翻譯伺服器的内容,然後伺服器會傳回對應的翻譯給帶浏覽器,最後顯示在浏覽器上給我們看。
我們還可看到一個 request Headers 中有一個:
user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36
這個user-agent的意思是告訴伺服器我使用谷歌浏覽器通路的,有些網站會有反爬蟲,如果發現你是爬蟲通路的就會阻止你,我們隻要加上這個user-agent就可以讓伺服器以為我們是使用者通過浏覽器通路的
記住上面三個資料,下面我們就要用到。
直接上完整代碼
import urllib.request
import urllib.parse
import json
# 請求的網址
Request_URL = "https://fanyi.baidu.com/sug"
while True:
text = input("翻譯内容")
#表單資料(需要翻譯的内容)
Form_Data = {
"kw": text
}
#建立一個User-Agent
head = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36"}
#使用urlencode方法轉換标準格式
data = urllib.parse.urlencode(Form_Data).encode('utf-8')
# 構造請求對象
req = urllib.request.Request(Request_URL,data,head)
# 發送請求,獲得響應
req = urllib.request.urlopen(req)
# 擷取伺服器響應資料
req_data = req.read().decode("utf-8")
#使用json解析資料
html = json.loads(req_data)
#找到想要的結果
results = html['data'][0]['v']
#列印結果
print(results)
最終效果
如果還想要具體一點的結果可以使用 正則或者
split()
方法 這裡就不詳細說明了。
結語
如果還想增加一點難度,可以試一試有道翻譯 方法類似,有興趣的話可以自己嘗試一下。