< h1 id"蜂巢架构和构造方法">Hive 架构和构造方法</h1>
[目录]
< h2 id ,"前言">前言</h2>
本文档基于配置单元 3.1.2
< h2 id "hive" >hive 的基础知识</h2>
< h3 id,"基本架构">基本架构</h3>
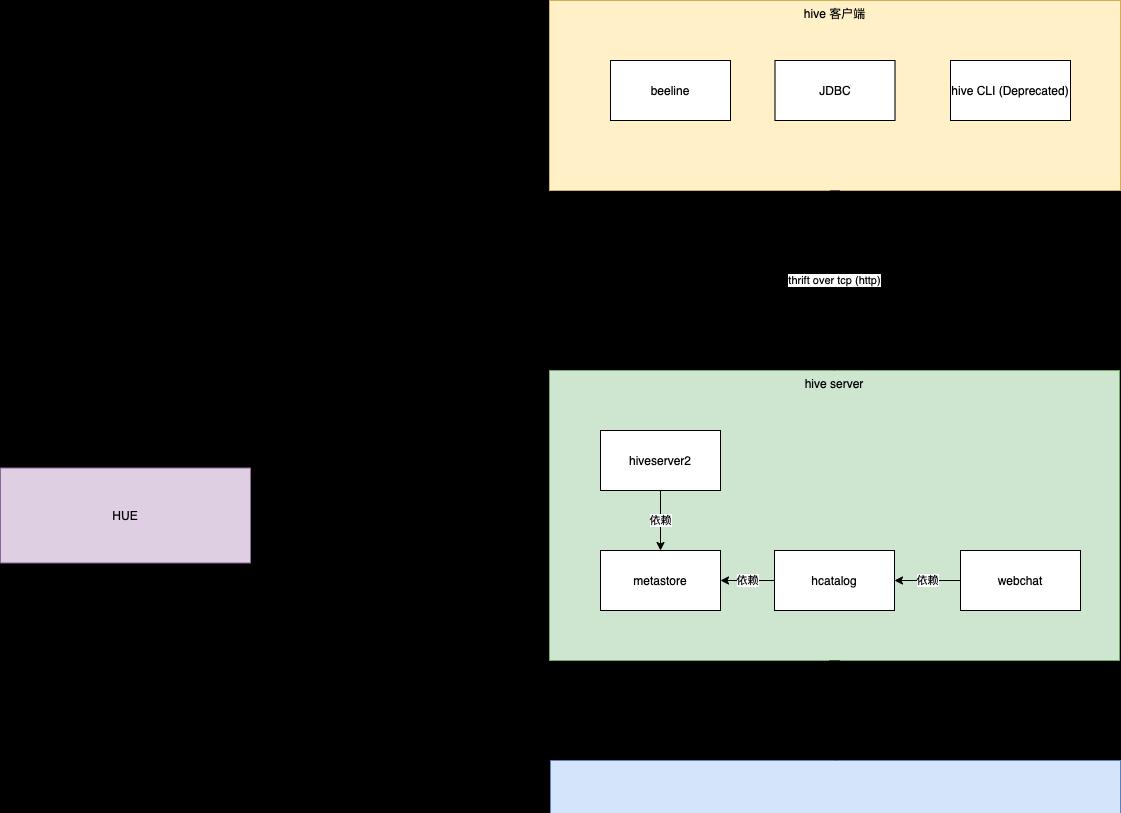
整个 hpe 由 hpeserver2 和 hpe 客户端组成
有三种类型的蜂巢客户端,直线,使用jdbc链接蜂巢服务器,或使用蜂巢CLI(这已经过时了,蜂巢官员不再推荐,推荐直行)
Hive 服务器本身由 hiv server2 和 metastore 组成
元存储是配置单元的元数据管理组件
hcatalog 在元存储上设置,公开一组 API,允许其他框架(如 Pig)使用实时元数据管理功能从表的角度管理数据
Webchat是基于hcatalog的公开的宁静界面
蜂巢的实际数据存储在hadoop的hodfs中
Hue为用户提供了一种基于sql的开发的图形化方式,当然还有其他附加功能<h3 id""metastore">元存储</h3>蜂巢数据基本上存储在hdffs中。如何从表的角度看数据,这是元存储的功劳,它存储了表的架构信息、序列化信息、存储位置信息等
元存储本身由两部分组成
元存储服务器
metatore db
这种经典的架构,就像任何单体java应用程序一样,服务器本身就是应用程序,db来存储数据。但整体上有三种特定的元存储部署模式
< h4 id,"内联服务和数据库">嵌入式服务和数据库</h4>

Metastore 服务器和 metatastore DB 与 hive 服务器一起内联部署,其中 metastore DB 使用嵌入式 Derby 数据库启动
< h4 id - 内联服务>内联服务</h4>
元存储服务器仍与配置单元一起部署。但是元存储数据库使用一个单独的Mysql来承担
< h4 id"服务和数据库单独部署">服务和数据库单独部署</h4>
除了数据库独立部署之外,元存储服务本身也是独立部署的
<h3 id="hcatalog">hcatalog</h3>
演示
上面的命令首先将文件复制到 hdfs,然后使用 hatalog 作为表 rawevents 的新分区
<客户端> h3 id"客户端"</h3>
< h4 id"客户端的本地模式">客户端的本地模式</h4>
上面描述的元存储的嵌入或远程部署是从 hiveserver 的角度出发的。Hiveserver 本身是一个独立的部署。但是,对于实时客户端,您可以通过远程模式连接到已部署的远程服务器。您还可以使用本地实时服务器及其相应的元存储启动客户端。找出答案很重要
<h4 id="beeline">beeline</h4>
作为hive推荐的下一代客户端。他使用Thrift远程通话。直线的本地模式
直线的本地模式
本地和远程之间的区别在于是否指定远程主机和端口。如果不是,则为本地模式
< h4 id"直线自动模式">直线自动模式</h4>
每次通过直线连接到远程 hpeserver 时,都需要指定一个较长的 jdbc url,这很麻烦,如果我们想点击直线命令,请直接连接到远端的 liveserver2,可以将其添加到实时配置文件目录中
<code>蜜蜂网站.xml</code>
配置文件,文件的内容大致如下
有两种方法可以配置直线连接和特定的 jdbc 连接字符串。一个使用 tcp,一个使用 http。默认情况下使用 Tcp
<h4 id="jdbc">jdbc</h4>
Jdbc 链接配置单元还有两种模式
对于远程服务器,URL 格式为
<code>jdbc:hive2://<host>:<port>/<db>; initFile=<file></code>
(HiveServer2 的默认端口为 10000)。
对于嵌入式服务器,URL 格式为
<code>jdbc:hive2:///; initFile=<file></code>
(无主机或端口)。
< h2 id"部署"的>部署</h2>
蜂巢的全面部署涉及五个组件,主要是前三个组件
元存储的部署
部署蜂巢服务器2
客户端的部署
部署 hcatalog 服务器(不是必需的)
部署 webhcat 服务器(不需要)
1,2个中的一个可以放在一起,即lifeverver2嵌入式元存储,只是METAstore DB,挂在Mysql上。
特别是在物理服务器上,上述三个组件可以部署到三台不同的计算机上,尽管 hp 客户端通常位于多台计算机上。
所有三个组件的配置都可以是实时站点.xml,但配置内容不一定相同。例如,需要配置 liveserver2、元数据库连接信息,但 clin 不需要此信息。
除了实时站点.xml之外,hive 还支持在其他几个位置进行配置
在命令启动时传递
<code>--蜂巢</code>
参数,指定自定义配置,例如
<code>bin/hive --hiveconf hive.exec.scratchdir=/tmp/mydir</code>
与元存储相关的配置在 hivemetastore-site .xml 文件中指定
hiveserver2 的独占配置在 liveserver2 站点.xml中指定。
当这些路径和配置文件具有相同的配置时,配置单元识别优先级如下所示,从左到右,将配置单元站点.xml -> hivemetastore-site .xml -> hiveserver2-site .xml ->'-hiveconf'
因此,最佳配置策略是:
在实时站点.xml中配置,hiveserver2 和 hive 客户端客户端共享一个配置,从而可以轻松地将配置直接分发到多台计算机
将与元存储相关的配置放在 hivemetastore-site .xml。与元数据库相关的配置(仅存在于元服务器部署的计算机上)不会在四个分区中颁发数据库密码
将 hiveserver2 的唯一配置放在 liveserver2 站点.xml
< h3 id " "Deployiveserver2" > deploy hivserver2</h3>
以下配置以嵌入式元存储服务器(远程元存储数据库)的形式进行配置,用于生命服务器部署
在需要部署配置单元的计算机上。创建一个真实账户,
<code>添加用户配置单元</code>
并将其添加到hadoop组中,所有后续配置和启动都由蜂巢用户执行
下载实时安装包。删除 conf 下的单个模板文件,并根据需要对其进行配置。配置单元默认值.xml.template 需要更改为实时站点.xml
配置单元默认.xml.template 包含所有配置单元组件的默认配置。
详细的部署文档:https://cwiki.apache.org/confluence/display/Hive/AdminManual+Configuration#AdminManualConfiguration-HiveMetastoreConfigurationVariables
<h4 id"在 hdfs 中创建实时数据存储路径"> hdfs 中创建配置单元数据存储路径</h4>
在 hdfs 中创建以下文件,并向配置单元所属的组授予写入权限
/user/hive/warehouse 是实际存储配置单元中表数据的位置。这是默认路径,您当然可以在实时站点.xml
<code>hive.metastore.warehouse.dir</code>
用于指定新路径的属性
< h4 id"配置配置配置环境变量></h4>
< h4 id ,配置日志输出路径>配置日志输出路径</h4>
配置单元的默认输出路径为
<code>/tmp/<user.name>/hive.log</code>
如果我们从蜂巢用户开始,则路径为
<code>/tmp/hive/hive.log</code>
/tmp 路径是 linux 用于存储每个应用程序的运行时的中间状态数据,通常在操作系统重新启动后自动清理。当然,您可以修改实时log4j文件以指定
<code>hive.log.dir=<other_location></code>
路径
您还可以动态地通过 liveconf 参数在启动 liveserver2 时指定路径
<code>bin/hiveserver2 --hiveconf hive.root.logger=INFO,DRFA</code>
< h4 id""hive" >hive 的临时文件配置</h4>
hive 运行时还会在本地和 hdfs 中存储临时文件(称为暂存文件)。存储的文件路径为 hdfs:
<code>/tmp/hive-<用户名></code>
当地:
<code>/tmp/<用户名></code>
值得注意的是,蜂巢站点.xml模板,有许多路径配置
<code>${java.io.tmpdir}/${user.name}/</code>
,
<code>${java.io.tmpdir}</code>
此配置的缺省值是使用临时目录(通常在 linux 下)获取 Java
<code>/吨/吨</code>
<code>${user.name}</code>
表示正在采用当前启动配置单元的用户。如果未具体指定,则可以删除相应的配置项目。并且不要直接在配置中编写
在 xml 中无法识别这些占位符。
<h4 id"配置元存储的数据库信息,并初始化>配置元存储的数据库信息并对其进行初始化</h4>
在与.xml对应的目录中,为指定人员创建一个.xml文件,以配置元存储相关信息
初始化元存储数据库
dbType 的值可以在哪里
<code>derby, oracle, mysql, mssql, postgres</code>
参考 https://cwiki.apache.org/confluence/display/Hive/AdminManual+Metastore+Administration
<h4 id""start liveserver2" > start hiveserver2</h4>
上述命令针对前台运行,最好是在无挂断加后台模式下运行
启动后 hpe 的 Web 界面的端口为:10002
< h3 id,"基本客户端部署">基本客户端部署</h3>
< h4 id"包分发">包分发</h4>
将上述带有配置的hpe发包复制到需要启动直线的机器上,即完成客户端的配置。配置文件只需要实时站点的.xml,根据特定的机器环境修改相应的路径配置信息,并且不需要 livemetastore-site .xml 和 hiveserver2-site 的.xml文件
< h4 id ,"环境变量配置">环境变量配置</h4>
< h4 id,"日志路径配置">日志路径配置</h4>
与 lifeerver 一样,根据具体情况进行一些路径配置修改
< h4 id"开始">开始</h4>
用
<code>$HIVE_HOME/bin/beeline -u jdbc:hive2://$HS 2_HOST:$HS 2_PORT</code>
你可以连接到liveerver2。
由于 hpe 在 hdfs 中使用的目录,因此默认值为
<code>/用户/配置单元/仓库</code>
,因此,为了避免与权限相关的错误,您需要通过直线添加链接
<code>-n</code>
参数,指定当前客户端正在使用的用户。用户必须
而它下面的文件的相关权限,如果不需要单独添加的话。权限模型,类似于 Linux。如果存在权限问题,则一般错误类似
具有用户名的链接采用以下形式:
这是蜂巢用户到蜂巢服务器的链接
Beeline 将文档作为一个整体使用:https://cwiki.apache.org/confluence/display/Hive/HiveServer2+Clients
<h3 id"蜂巢服务器高可用性部署">hiveserver 高可用性部署</h3>
< h4 id,"服务端配置">端配置</h4>
在需要启动 hiverserver 的所有计算机上,配置 liveserver2-site .xml。其中有以下配置
还要记住,需要部署的计算机都具有相同的元存储配置,确保它们连接到相同的mysql,并且livemetastore-site.xml配置可以复制到需要启动lifeerver的多台计算机上
参考资料: http://lxw1234.com/archives/2016/05/675.htm
< h4 id - "客户端连接">客户端连接</h4>
与直线的连接如下:
请注意,其中的 jdbc 网址必须用引号括起来
< h3 id - "认证">认证</h3>
此处选择 Kerberos 作为身份验证选项。需要配置的三个配置项如下:
<h4 id"在kerberos认证后使用直线链接方法">在kerberos认证后使用直线链接方法</h4>
在使用上述命令之前,可以保证当前机器的 kerberos 认证已通过 kinit 实现。"无直线"命令将报告错误,因为未获取 Kerberos 认证票证。
该命令会自动读取当前登录的 kerberos 用户信息,该信息在执行命令时随您一起获取
例如,当前的 kerberos tgt 是测试用户,则与所有者对应的 hivesql 就是测试。实际组件之间的通信身份验证由实时/[email protected] 用户使用。但是,将控制授权的粒度以进行测试。
此功能由 hpe 配置
<code>hive.server2.enable.doAs</code>
要控制的属性(当该属性为 true 时)表示运行以将用户提交为最终 sql 执行的用户
另外,我们最好在蜂巢服务器的配置文件中
<code>hive.server2.allow.user.substitution</code>
关闭为 false。由于此选项,允许用户使用
该参数指定用户。这会导致一个用户使用自己的 kerberos 凭据操作其他人的库表。但是,禁用时,Hue 无法将其登录用户设为提交作业的人员。
<h3 id"基于实时站点xml的客户端连接">基于实时站点.xml的客户端连接</h3>
上述记录以 jdbc 实现的方式连接到 hpeserver2。但是,某些依赖于 hpe 的程序只能通过.xml以这种方式连接到 hiveserver。典型色调
顺化会走
<code>${HIVE_CONF_DIR}</code>
环境变量或
<code>/etc/hive/conf</code>
往下看
<code>网站.xml</code>
和
<code>蜜蜂-hs2-连接.xml</code>
两个配置文件,读取其中的信息,实现与生命服务器的连接。
如果群集配置了 kerberos,则需要在实时站点.xml中对其进行配置,例如,与 liveserver2-site .xml相同的 kerberos 身份验证配置
与 hue 使用直线连接一样,您也可以配置 beeline-hs2 连接.xml,您可以在其中指定一些连接到 hiveserver2 的代理用户信息,但当前未发现该配置仍然可用。如下:
< h3 id ,"一些错误">一些错误</h3>
< h4 id"错误 1-番石榴">错误 1 番石榴</h4>
初始化元存储架构是一个错误
原因是hadoop路径
<code>share/hadoop/common/lib/</code>
下面的番石榴包与 live lib 下的番石榴包版本不一致。
解决方案是删除hpe的番石榴包,并将hadoop的相应番石榴包复制过来
<h4 id"错误2,mysql驱动器">错误2,mysql驱动器</h4>
问题的原因,蜂巢缺乏mysql驱动器
解决方案是下载一个mysql驱动程序并将其安装在实时库下
< h4 id"错误 3">错误 3</h4>
使用直线客户端时:
<code>beeline -u jdbc:hive2://master:10000</code>
链接,蜂巢服务器 2,报告了以下错误
我们是由蜂巢用户启动的 hpeserver2。因此,所有客户端,无论是否以书面形式链接到 hpeserver2,最终都会使用 hiveserver2 来访问 hadoop 集群,所有这些客户端都由 hive 的用户访问。
但是,如果你不在hadoop中,做相关的配置,那么hadoop默认不允许用户将集群作为其他用户的代理用户,所以你需要在hadoop的代码站点.xml做以下配置。
< h2 id , "资源" > 参考文献</h2>
https://cwiki.apache.org/confluence/display/Hive/GettingStartedhttps://cwiki.apache.org/confluence/display/Hive/HCatalog+InstallHCathttps://stackoverflow.com/questions/22533814/what-is-use-of-hcatalog-in-hadoophttps://cwiki.apache.org/confluence/display/Hive/HiveServer2+Clients
欢迎来到我的个人公众号"西北UP",记录代码生活,行业思考,科技评论