<h1 id="hive architecture and construction method" > Hive architecture and construction method</h1>
[TOC]
<h2 id="Preface" > preface</h2>
This document is based on hive 3.1.2
<h2 id="Basics of hive" > the basics of hive</h2>
<h3 id="Base Schema" > base schema</h3>
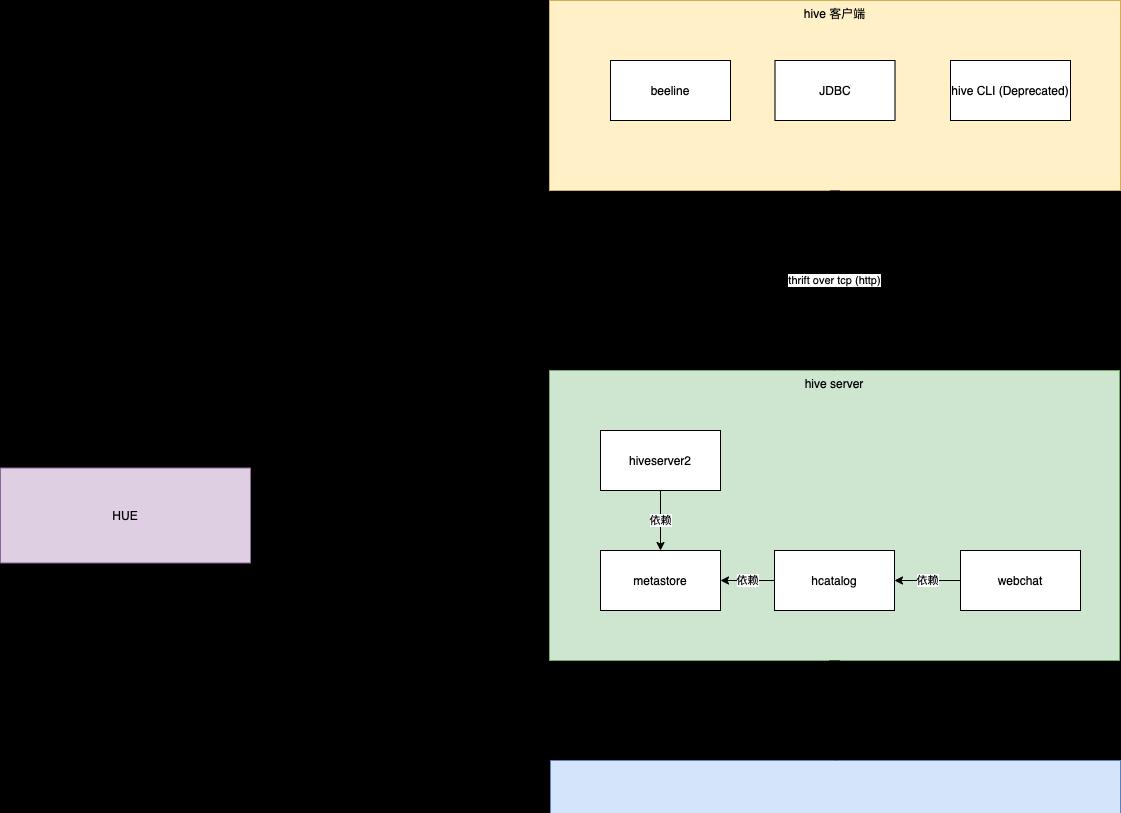
The entire hive consists of hiveserver2 and hive clients
There are three kinds of hive clients, beeline, use jdbc link hiveserver, or use hive CLI (this is outdated, hive official is no longer recommended, recommended beeline)
The hive server itself consists of hive server2 and metastore
Metastore is the metadata management component of hive
hcatalog is mounted on metastore, exposing a set of APIs that enable other frameworks such as Pig and FLink to use hive's metadata management capabilities to manage data from a table perspective
Webchat is a restful interface that exposes on top of hcatalog
The actual data of hive is stored in hadoop hdfs
Hue provides a graphical way for users to do SQL-based development, and of course there are other additional features< h3 id="metastore" > metastorehive</h3> data is essentially stored in HDFS. How to see the data from the perspective of a table, this is the credit of the metastore, which stores the schema information of the table, serialized information, stored location information, etc
The metastore itself consists of two parts
metastore server
metatore db
This classic architecture, like any monolithic Java application, is the application itself, db to store data. But there are three specific metastore deployment models as a whole
<h4 id=Embedded Services and Databases > inline services and databases</h4>

Metastore server and metastore DB are deployed together with hive server, and the metastore DB is deployed in an embedded manner, where metastore DB is launched with an embedded Derby database
<h4 id="Embedded Services" > inline services</h4>
Metastore server is still deployed with hive. But Metastore DB uses a standalone Mysql to take over
<h4 id="Service and database separately deployed" > services and databases are deployed separately</h4>
In addition to the database deployment, the metastore service itself is also deployed independently
<h3 id="hcatalog">hcatalog</h3>
demo
The above command first copies the file to hdfs, and then uses the data as a new partition of the table rawevents through hcatalog
< h3 id="Client" > client</h3>
<h4 id="Client's local mode" > client's local mode</h4>
The above-mentioned metastore embedding or demote deployment is from the perspective of hiveserver. Hiveserver itself is a standalone deployment. However, for the hive client, it can connect to the deployed remote server through the remote mode. You can also start the client with a local hive server and its corresponding metastore. This must be made clear
<h4 id="beeline">beeline</h4>
As a new generation client recommended by Hive. He uses Swift to call remotely. Local mode of beeline
Local mode of beeline
The difference between local and remote is whether or not to specify a remote Host and port. If not, it's local mode
<h4 id="automatic mode of beeline" > automatic mode of beeline</h4>
Every time you connect to the remote hiveserver through the beeline, you need to specify a long period of jdbc url, which is very troublesome, if we want to tap the beeline command, directly connect the remote hiveserver2, you can add it in the hive configuration file directory
<code>beeline-site.xml</code>
The configuration file, the contents of the file are roughly as follows
Two ways of configuring beeline connections, and specific jdbc connection strings. One uses tcp and one uses http. The default is tcp
<h4 id="jdbc">jdbc</h4>
Jdbc link hive also has two modes
For a remote server, the URL format is
<code>jdbc:hive2://<host>:<port>/<db>;initFile=<file></code>
(default port for HiveServer2 is 10000).
For an embedded server, the URL format is
<code>jdbc:hive2:///;initFile=<file></code>
(no host or port).
< h2 id=Deployment > deployment</h2>
A full deployment of a hive involves five components, with the first three mainly needed to be deployed
Deployment of metastore
Deployment of hiveserver2
Deployment of clients
Deployment of hcatalog server (optional)
Deployment of webhcat servers (optional)
Where 1 and 2 can be together, that is, hiveserver2 embedded metastore, just the metastore DB, plug-in to Mysql.
Specific to the physical server, the above three components can be deployed to three different machines, of course, the hive client will generally be on multiple machines.
The configuration corresponding to the three components can be hive-site.xml, but the configuration content is not necessarily the same. For example, hiveserver2 needs to configure the connection information of meta DB, but the client does not need this information.
In addition to hive-site .xml, hive also supports configuration in several other places
Pass when starting the command
<code>--hiveconf</code>
parameters, such as a custom configuration, specifying a custom configuration
<code>bin/hive --hiveconf hive.exec.scratchdir=/tmp/mydir</code>
The metastore-related configuration specified in the hivemetastore-site .xml file
Hiveserver2-exclusive configuration specified in hiveser2-site .xml.
When you have the same configuration in these paths and configuration files, hive recognition priority is as follows, from left to right, raise hive-site.xml -> hivemetastore-site.xml -> hiveserver2-site.xml -> '-hiveconf'
Therefore, the best configuration strategy is:
Configured in the hive-site .xml, hiveserver2 and hive clients share a configuration that facilitates the distribution of the configuration directly to multiple machines
Place metastore-related configurations in hivemetastore-site .xml. Meta database-related configurations exist only on metaserver-deployed machines and do not distribute database passwords everywhere
Place hiveserver2-unique configurations in the hiveserver2-site .xml
<h3 id="Deploy hiveserver2" > deploy hiveserver2</h3>
The following configuration adopts the embedded metastore server and remote metastore DB for hive server deployment
On machines where hive needs to be deployed. Create a hive account,
<code>adduser hive</code>
And add it to the hadoop group, and all subsequent configuration and launch is carried out by the hive user
Download the hive installation package. Remove each template file under conf and configure it as needed. hive-default.xml.template needs to be changed to hive-site .xml
hive-default.xml.template contains all the default configurations associated with each hive component.
Detailed deployment documentation: https://cwiki.apache.org/confluence/display/Hive/AdminManual+Configuration#AdminManualConfiguration-HiveMetastoreConfigurationVariables
<h4 id="Create hive data hold path in hdfs" > create a live data hold path in hdfs</h4>
Create the following file in hdfs and assign write permissions to the group to which hive belongs
/user/hive/warehouse is where table data in hive is actually stored. It's the default path, which you can certainly set through in the hive-site .xml
<code>hive.metastore.warehouse.dir</code>
property to specify the new path
<h4 id="Configure hive environment variables" > configure hive environment variables</h4>
<h4 id=Configure Log Output Path > configure the log output path</h4>
The default output path for hive is
<code>/tmp/<user.name>/hive.log</code>
, if we start as a hive user, then the path is
<code>/tmp/hive/hive.log</code>
The /tmp path is used by Linux to store the intermediate state data of each application running, which is generally automatically cleaned up after the operating system restarts. Of course, you can modify the hive log4j file to specify
<code>hive.log.dir=<other_location></code>
path
You can also dynamically specify the path through the hivconf parameter when you start hiveserver2
<code>bin/hiveserver2 --hiveconf hive.root.logger=INFO,DRFA</code>
<h4 id="Temporary file configuration for hive" > temporary file configuration for hive</h4>
The hive runtime also stores temporary files in host locals and hdfs, called scratch files. The file path is hdfs:
<code>/tmp/hive-<username></code>
local:
<code>/tmp/<username></code>
It is worth noting that hive-site .xml template, there are a large number of path configurations
<code>${java.io.tmpdir}/${user.name}/</code>
,
<code>${java.io.tmpdir}</code>
Indicates that the default value of this configuration is to take Java to use a temporary directory, generally under Linux
<code>/tmp</code>
<code>${user.name}</code>
Indicates the user who currently starts hive. If you do not specify it specifically, you can delete the corresponding configuration item. Do not directly configure also written in
, these placeholders are not recognized in xml.
<h4 id="Configure db information for metastore- and initialize" > configure DB information for metastore and initialize</h4>
In the corresponding directory of the hive-site .xml, create a hivemetastore-site .xml file to configure metastore-related information
Initialize metastore db
where the value of dbType can be
<code>derby, oracle, mysql, mssql, postgres</code>
References https://cwiki.apache.org/confluence/display/Hive/AdminManual+Metastore+Administration
<h4 id="Start hiveserver2" > start hiveserver2</h4>
The above command is run for the foreground, preferably in the no hang up plus background mode
The corresponding port of hive's web interface after startup is: 10002
<h3 id="Basic client deployment" > basic client deployment</h3>
<h4 id="Package Distribution" > package distribution</h4>
Copy the above hive hairstyle package, with the configuration, to the machine that needs to start beeline, that is, complete the configuration of the client. The configuration file only needs the hive-site .xml, and the corresponding path configuration information can be modified according to the specific machine environment, and the hivemetastore-site.xml and hiveserver2-site .xml files are not required
< h4 id=Environment Variable Configuration > environment variable configuration</h4>
< h4 id=Log Path Configuration > log path configuration</h4>
As with hiveserver, some path configuration modifications are made depending on the situation
< h4 id=Startup > started</h4>
use
<code>$HIVE_HOME/bin/beeline -u jdbc:hive2://$HS2_HOST:$HS2_PORT</code>
you can connect to hiveserver2.
Since hive uses the directory in hdfs, the default is
<code>/user/hive/warehouse</code>
So in order to avoid permission-related errors, the need to be added via the beeline link is added
<code>-n</code>
A parameter that specifies the user that the current client uses. And the user has to have it
And the relevant permissions of the files under it, if not, need to be added separately. The permissions model, similar to Linux. If there is a permissions issue, the general error is similar
The link with the username is in the form:
Here the hive user links to the hiveserver
Beeline Overall Usage Documentation: https://cwiki.apache.org/confluence/display/Hive/HiveServer2+Clients
<h3 id="hiveserver highly available deployment" > hiveserver highly available deployment</h3>
<h4 id="Server-side Configuration" > Server-side Configuration</h4>
On all machines that need to start hiverserver, configure hiveserver2-site .xml. Configure it as follows
Also remember that the machines that need to deploy hiverserver must have the same metastore configuration, ensuring that they can connect to the same mysql, and can copy the hivemetastore-site .xml configuration to multiple machines that need to start hiveserver
References: http://lxw1234.com/archives/2016/05/675.htm
< h4 id=Client Connection > client connection</h4>
The connection with beeline is as follows:
Note that the jdbc url must be enclosed in quotation marks
< h3 id="authentication" ></h3>
Here select Kerberos as the authentication option. The three configuration items that need to be configured are as follows:
<h4 id="Use of the beeline link method after kerberos certification" > use the beeline link method after kerberos certification</h4>
Before using the above command, it must be guaranteed that the kerberos authentication of the current machine has been implemented through kinit. Otherwise, the beeline command will report an error because the kerberos authentication ticket was not received.
The command automatically reads the currently logged-in kerberos user information, which is taken with it when executing the command
For example, the current kerberos tgt is a test user, then the hivesql corresponding to the owner is the test. Communication authentication between actual components is used by hive/[email protected] users. But the granularity of the authorization is controlled by the test.
This feature is hive configured
<code>hive.server2.enable.doAs</code>
The property to control, when true, represents the user who runs to commit the user as the final sql execution
Also, it's best that we're in the hiveserver's configuration file, which will
<code>hive.server2.allow.user.substitution</code>
Close as false. Because of this option, users are allowed to
The parameter specifies a user. This causes a user to manipulate someone else's library table with their own kerberos credentials. However, when disabled, hue cannot use its logged-in user as the person who submitted the job.
<h3 id="hive-sitexml-based client connection" > a hive-site .xml client connection</h3>
The way in which the above record is connected to hiveserver2 is achieved through jdbc. However, some programs that rely on hive can only connect to hiveserver through hive-site .xml. Typical is hue
Hue will go
<code>${HIVE_CONF_DIR}</code>
Environment variables or
<code>/etc/hive/conf</code>
Look under the path
<code>hive-site.xml</code>
and
<code>beeline-hs2-connection.xml</code>
Two configuration files, reading the information in them, implement the connection to the hiveserver.
If the cluster is configured with kerberos, it needs to be configured in the hive-site .xml, which is the same as the kerberos authentication configuration .xml the hiveserver2-site, for example
Like hue is to use beeline connection, you can also configure the beeline-hs2-connection .xml, in which you specify some proxy user information for connecting to hiveserver2, but it is currently found that it can still be used without configuration. as follows:
<h3 id="Some errors" > some errors</h3>
<h4 id="Error 1-guava" > Error 1 guava</h4>
Initializing the metastore schema is an error
The reason is the hadoop path
<code>share/hadoop/common/lib/</code>
The guava package under the hive is inconsistent with the version of the guava package under the hive lib.
Solution, delete the hive guava package and copy the hadoop corresponding guava package
<h4 id="Error 2, mysql driven" > Error 2, mysql driver</h4>
The problem is due to hive's lack of mysql drivers
The solution is to download a mysql driver and install it under hive lib
<h4 id="Error 3" > Error 3</h4>
When using the beeline client:
<code>beeline -u jdbc:hive2://master:10000</code>
When linking hiveserver2, the following error is reported
We are hiveserver2 launched as a hive user. Therefore, all clients, whether linked to hiveserver2 as a written user, and eventually when hiveserver2 goes to access the hadoop cluster, it is accessed by hive users.
However, if you do not make relevant configurations in Hadoop, then Hadoop does not allow this user to use the cluster as a proxy user for other users by default, so you need to make the following configuration in hadoop's core-site .xml
< h2 id=References > references</h2>
https://cwiki.apache.org/confluence/display/Hive/GettingStartedhttps://cwiki.apache.org/confluence/display/Hive/HCatalog+InstallHCathttps://stackoverflow.com/questions/22533814/what-is-use-of-hcatalog-in-hadoophttps://cwiki.apache.org/confluence/display/Hive/HiveServer2+Clients
Welcome to follow my personal public account "North by Northwest UP", record code life, industry thinking, technology reviews