作者 | CV君
编辑 | CV君
报道 | 我爱计算机视觉(微信id:aicvml)
#目标检测##CVPR 2022#
Unknown-Aware Object Detection: Learning What You Don't Know from Videos in the Wild
威斯康星大学&微软
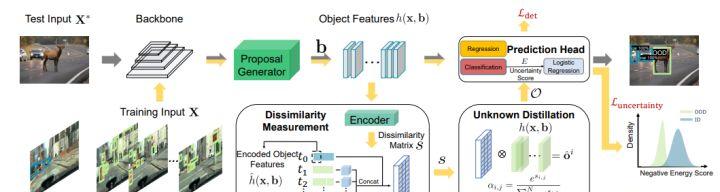
构建可靠的目标检测器,能够检测出分布外(OOD)的目标,这一点至关重要,但却没有得到充分的探索。其中一个关键的挑战是,模型缺乏来自未知数据的监督信号,对 OOD 目标产生过于自信的预测。
在本次工作中,作者通 Spatial-Temporal Unknown Distillation(STUD)提出一个新的未知物检测框架,该框架从自然视频中蒸馏出未知物,并有意义地规范了模型的决策边界。STUD 首先识别空间维度上的unknown candidate object proposals,然后将多个视频帧中的候选目标聚集起来,形成决策边界附近的不同未知物体集。
同时,采用基于能量的不确定性正则化损失,该损失对比性地塑造了内分布和蒸馏出的未知物体之间的不确定性空间。STUD 在 OOD 检测任务中建立了最先进的目标检测性能,与之前的最佳方法相比,FPR95 得分降低了 10%以上。
已开源:https://github.com/deeplearning-wisc/stud
论文:https://arxiv.org/abs/2203.03800
#CVPR 2022##语义匹配##弱监督学习#
Probabilistic Warp Consistency for Weakly-Supervised Semantic Correspondences
苏黎世联邦理工学院
Probabilistic Warp Consistency,一个用于语义匹配的弱监督学习目标。该方法直接监督由网络预测的密集匹配分数,并将其编码为条件概率分布。作者首先构建一个 image triplet(图像三联体),将一个已知的经纬仪应用于描述同一物体类别的不同实例的一对图像中的一个。然后,概率学习目标是利用所产生的图像三联体的约束条件而得出的。通过用一个可学习的不匹配状态来扩展概率输出空间,从而进一步考虑到真实图像对中存在的遮挡和背景杂波。为了监督它,在描述不同物体类别的图像对之间设计一个目标。通过将其应用于四个最新的语义匹配架构来验证该方法。在四个具有挑战性的语义匹配基准上创造了新的SOTA。最后,还证明,当与关键点标注相结合时,该目标也会在强监督制度下带来实质性的改进。
已开源:https://github.com/PruneTruong/DenseMatching
论文:https://arxiv.org/abs/2203.04279

#对比学习##CVPR 2022#
Selective-Supervised Contrastive Learning with Noisy Labels
中科院&国科大&悉尼大学
深度网络有很强的能力将数据嵌入到隐藏表征中并完成后续任务。然而,这些能力主要来自于高质量的标注标签,但收集成本很高。噪声标签更实惠,但会导致表征被破坏,从而导致泛化性能差。
为了学习具有鲁棒性的表征并处理嘈杂的标签,作者在本文中提出选择性监督的对比学习(Sel-CL)。具体来说,Sel-CL 扩展了监督对比学习(Sup-CL),在表征学习中很强大,但在有噪声标签的情况下会有所下降。Sel-CL 解决了 Sup-CL 的问题的直接原因。也就是说,由于 Sup-CL 是以 pair-wise 的方式进行工作,由噪声标签建立的噪声对会误导表示学习。为了缓解这个问题,在不知道噪声率的情况下,从有噪声的对中选择有信心的对来进行 Sup-CL。在选择过程中,通过测量学习到的表征和给定标签之间的一致性,首先识别出自信的例子,利用这些例子来建立自信的对。然后,利用建立的自信对中的表征相似性分布,从噪声对中找出更多的自信对。所有获得的自信对最终被用于Sup-CL,以增强表示。
在多个噪声数据集上的实验证明了所提出方法所学到的表征的鲁棒性,遵循了最先进的性能。
将开源:https://github.com/ShikunLi/Sel-CL
论文:https://arxiv.org/abs/2203.04181
#Image Stitching##图像拼接##CVPR 2022#
Deep Rectangling for Image Stitching: A Learning Baseline
北京交通大学&Beijing Key Laboratory of Advanced Information Science and Network&电子科技大学
拼接得图像提供一个宽阔的视场(FoV),但却受到不合意的不规则边界的影响。为了处理这个问题,现有的 image rectangling(图像矫正)方法致力于搜索一个初始网格和优化一个目标网格,以形成两个阶段的网格变形。然后,通过 warping stitched images 可以生成矩形图像。然而,这些解决方案只适用于具有丰富线性结构的图像,对于具有非线性物体的肖像和风景,会导致明显的失真。
文中通过提出第一个针对图像矩形的深度学习解决方案来解决这些问题。具体来说,预先定义一个刚性的目标网格,只估计一个初始网格来形成网格变形,有助于形成一个紧凑的单阶段解决方案。初始网格是用一个完全卷积网络和一个残差渐进式回归策略来预测的。为了获得具有高内容保真度的结果,提出一个综合目标函数,以同时鼓励边界矩形、网格形状保护和内容感知自然。此外,建立第一个在不规则边界和场景中具有较大多样性的图像拼接矩形数据集。
实验证明该方法在数量和质量上都优于传统方法。
将开源:https://github.com/nie-lang/DeepRectangling
论文:https://arxiv.org/abs/2203.03831
#CVPR 2022###实例分割#
E2EC: An End-to-End Contour-based Method for High-Quality High-Speed Instance Segmentation
武汉大学
基于 Contour 的实例分割方法近期发展迅速,但其特点是 rough、手工制作的前端轮廓初始化,限制了模型的性能,而经验性的、固定的后端预测-标签顶点配对,引起学习的困难。文中介绍一种新型的基于轮廓的方法,E2EC,用于高质量的实例分割。首先,E2EC 应用一种新的可学习的轮廓初始化结构,而不是手工制作的轮廓初始化。这包括一个用于构建更明确的学习目标的 contour initialization module(轮廓初始化模块)和一个用于更好地利用所有顶点特征的 global contour deformation module(全局轮廓形变模块)。第二,提出一个新的标签采样方案,multi-direction alignment,以降低学习难度。第三,为了提高边界细节的质量,动态地匹配最合适的 predicted-ground truth 顶点对,并提出了相应的损失函数,即动态匹配损失。
实验表明,E2EC在KITTI INStance(KINS)数据集、SBD(Semantic Boundaries Dataset)、Cityscapes和COCO数据集上能达到最先进的性能。E2EC在实时应用中的效率也很高,在英伟达A6000 GPU上,512*512图像的推理速度为36 fps。
将开源:https://github.com/zhang-tao-whu/e2ec
论文:https://arxiv.org/abs/2203.04074
#点云##CVPR 2022#
Shape-invariant 3D Adversarial Point Clouds
中国科学技术大学&微软&西蒙菲莎大学
文中提出 point-cloud sensitivity map,用于评估每个点遇到形状不变量扰动时的识别置信度的方差。点遇到形状不变的扰动时,评估识别置信度的方差。在灵敏度图的指导下,提出强形状不变的白盒攻击和第一个基于查询的黑盒攻击的点云识别。实验表明,攻击在各种识别模型上的效率很高,在黑箱设置下具有很高的不可知性和低查询成本。
将开源:https://github.com/shikiw/SI-Adv
论文:https://arxiv.org/abs/2203.04041
#CVPR 2022##点云分类#
ART-Point: Improving Rotation Robustness of Point Cloud Classifiers via Adversarial Rotation
北大&京东
具有旋转鲁棒性的点云分类器已经在三维深度学习社区中得到了广泛讨论。大多数提出的方法要么使用旋转不变的描述符作为输入,要么试图设计旋转不变的网络。然而,由于对原始分类器或输入空间的修改,这些方法产生的鲁棒性模型在 clean aligned 数据集下性能有限。
本次任务中,作者首次表明,点云分类器的旋转鲁棒性也可以通过对抗性训练获得,在旋转的和干净的数据集上都有更好的表现。具体来说,提出 ART-Point 框架,将点云的旋转视为一种攻击,并通过在具有对抗性旋转的输入上训练分类器来提高旋转鲁棒性。提出一种 axis-wise rotation attack(轴向旋转攻击),使用预先训练好的模型的反向传播梯度来有效地找到对抗性旋转。为了避免模型对对抗性输入的过度拟合,构建了旋转池,利用对抗性旋转在样本间的可迁移性来增加训练数据的多样性。此外,提出一个快速的 one-step 优化,以有效地达到最终的鲁棒模型。
实验表明,所提出的旋转攻击取得了很高的成功率,ART-Point 可以用于大多数现有的分类器,以提高旋转的鲁棒性,同时在干净的数据集上表现出比最先进的方法更好的性能。
将开源:https://github.com/robinwang1/ART-Point
论文:https://arxiv.org/abs/2203.03888
#语义分割##CVPR 2022#
Weakly Supervised Semantic Segmentation using Out-of-Distribution Data
首尔大学
弱监督语义分割(WSSS)方法通常建立在从分类器获得的像素级定位图上。然而,由于只对类标签进行训练,分类器受到 foreground 和 background (前景和背景)线索(如火车和铁路)之间的虚假关联的影响,从根本上限制了WSSS的性能。以前曾有过通过额外监督来解决这个问题的努力。
本次研究,提出一个新的信息来源来区分前景和背景,分布外(OoD)的数据,或没有前景物体类别的图像。特别是,利用分类器有可能做出假阳性预测的 hard OoD。这些样本通常在背景上带有关键的视觉特征(如铁路),而分类器经常将其混淆为前景(如火车),所以这些线索让分类器正确地抑制了虚假的背景线索。获得这样的hard OoD不需要大量的标注工作;它只需要在收集类别标签的原始努力之上产生一些额外的图像级别的标签成本。因此,提出 W-OoD,用于利用 hard OoD,并在Pascal VOC 2012上实现了最先进的性能。
将开源:https://github.com/naver-ai/w-ood
论文:https://arxiv.org/abs/2203.03860