作者 | CV君
編輯 | CV君
報道 | 我愛計算機視覺(微信id:aicvml)
#目标檢測##CVPR 2022#
Unknown-Aware Object Detection: Learning What You Don't Know from Videos in the Wild
威斯康星大學&微軟
建構可靠的目标檢測器,能夠檢測出分布外(OOD)的目标,這一點至關重要,但卻沒有得到充分的探索。其中一個關鍵的挑戰是,模型缺乏來自未知資料的監督信号,對 OOD 目标産生過于自信的預測。
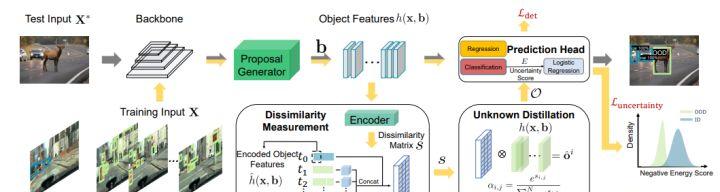
在本次工作中,作者通 Spatial-Temporal Unknown Distillation(STUD)提出一個新的未知物檢測架構,該架構從自然視訊中蒸餾出未知物,并有意義地規範了模型的決策邊界。STUD 首先識别空間次元上的unknown candidate object proposals,然後将多個視訊幀中的候選目标聚集起來,形成決策邊界附近的不同未知物體集。
同時,采用基于能量的不确定性正則化損失,該損失對比性地塑造了内分布和蒸餾出的未知物體之間的不确定性空間。STUD 在 OOD 檢測任務中建立了最先進的目标檢測性能,與之前的最佳方法相比,FPR95 得分降低了 10%以上。
已開源:https://github.com/deeplearning-wisc/stud
論文:https://arxiv.org/abs/2203.03800
#CVPR 2022##語義比對##弱監督學習#
Probabilistic Warp Consistency for Weakly-Supervised Semantic Correspondences
蘇黎世聯邦理工學院
Probabilistic Warp Consistency,一個用于語義比對的弱監督學習目标。該方法直接監督由網絡預測的密集比對分數,并将其編碼為條件機率分布。作者首先建構一個 image triplet(圖像三聯體),将一個已知的經緯儀應用于描述同一物體類别的不同執行個體的一對圖像中的一個。然後,機率學習目标是利用所産生的圖像三聯體的限制條件而得出的。通過用一個可學習的不比對狀态來擴充機率輸出空間,進而進一步考慮到真實圖像對中存在的遮擋和背景雜波。為了監督它,在描述不同物體類别的圖像對之間設計一個目标。通過将其應用于四個最新的語義比對架構來驗證該方法。在四個具有挑戰性的語義比對基準上創造了新的SOTA。最後,還證明,當與關鍵點标注相結合時,該目标也會在強監督制度下帶來實質性的改進。
已開源:https://github.com/PruneTruong/DenseMatching
論文:https://arxiv.org/abs/2203.04279

#對比學習##CVPR 2022#
Selective-Supervised Contrastive Learning with Noisy Labels
中科院&國科大&悉尼大學
深度網絡有很強的能力将資料嵌入到隐藏表征中并完成後續任務。然而,這些能力主要來自于高品質的标注标簽,但收內建本很高。噪聲标簽更實惠,但會導緻表征被破壞,進而導緻泛化性能差。
為了學習具有魯棒性的表征并處理嘈雜的标簽,作者在本文中提出選擇性監督的對比學習(Sel-CL)。具體來說,Sel-CL 擴充了監督對比學習(Sup-CL),在表征學習中很強大,但在有噪聲标簽的情況下會有所下降。Sel-CL 解決了 Sup-CL 的問題的直接原因。也就是說,由于 Sup-CL 是以 pair-wise 的方式進行工作,由噪聲标簽建立的噪聲對會誤導表示學習。為了緩解這個問題,在不知道噪聲率的情況下,從有噪聲的對中選擇有信心的對來進行 Sup-CL。在選擇過程中,通過測量學習到的表征和給定标簽之間的一緻性,首先識别出自信的例子,利用這些例子來建立自信的對。然後,利用建立的自信對中的表征相似性分布,從噪聲對中找出更多的自信對。所有獲得的自信對最終被用于Sup-CL,以增強表示。
在多個噪聲資料集上的實驗證明了所提出方法所學到的表征的魯棒性,遵循了最先進的性能。
将開源:https://github.com/ShikunLi/Sel-CL
論文:https://arxiv.org/abs/2203.04181
#Image Stitching##圖像拼接##CVPR 2022#
Deep Rectangling for Image Stitching: A Learning Baseline
北京交通大學&Beijing Key Laboratory of Advanced Information Science and Network&電子科技大學
拼接得圖像提供一個寬闊的視場(FoV),但卻受到不合意的不規則邊界的影響。為了處理這個問題,現有的 image rectangling(圖像矯正)方法緻力于搜尋一個初始網格和優化一個目标網格,以形成兩個階段的網格變形。然後,通過 warping stitched images 可以生成矩形圖像。然而,這些解決方案隻适用于具有豐富線性結構的圖像,對于具有非線性物體的肖像和風景,會導緻明顯的失真。
文中通過提出第一個針對圖像矩形的深度學習解決方案來解決這些問題。具體來說,預先定義一個剛性的目标網格,隻估計一個初始網格來形成網格變形,有助于形成一個緊湊的單階段解決方案。初始網格是用一個完全卷積網絡和一個殘差漸進式回歸政策來預測的。為了獲得具有高内容保真度的結果,提出一個綜合目标函數,以同時鼓勵邊界矩形、網格形狀保護和内容感覺自然。此外,建立第一個在不規則邊界和場景中具有較大多樣性的圖像拼接矩形資料集。
實驗證明該方法在數量和品質上都優于傳統方法。
将開源:https://github.com/nie-lang/DeepRectangling
論文:https://arxiv.org/abs/2203.03831
#CVPR 2022###執行個體分割#
E2EC: An End-to-End Contour-based Method for High-Quality High-Speed Instance Segmentation
武漢大學
基于 Contour 的執行個體分割方法近期發展迅速,但其特點是 rough、手工制作的前端輪廓初始化,限制了模型的性能,而經驗性的、固定的後端預測-标簽頂點配對,引起學習的困難。文中介紹一種新型的基于輪廓的方法,E2EC,用于高品質的執行個體分割。首先,E2EC 應用一種新的可學習的輪廓初始化結構,而不是手工制作的輪廓初始化。這包括一個用于建構更明确的學習目标的 contour initialization module(輪廓初始化子產品)和一個用于更好地利用所有頂點特征的 global contour deformation module(全局輪廓形變子產品)。第二,提出一個新的标簽采樣方案,multi-direction alignment,以降低學習難度。第三,為了提高邊界細節的品質,動态地比對最合适的 predicted-ground truth 頂點對,并提出了相應的損失函數,即動态比對損失。
實驗表明,E2EC在KITTI INStance(KINS)資料集、SBD(Semantic Boundaries Dataset)、Cityscapes和COCO資料集上能達到最先進的性能。E2EC在實時應用中的效率也很高,在英偉達A6000 GPU上,512*512圖像的推理速度為36 fps。
将開源:https://github.com/zhang-tao-whu/e2ec
論文:https://arxiv.org/abs/2203.04074
#點雲##CVPR 2022#
Shape-invariant 3D Adversarial Point Clouds
中國科學技術大學&微軟&西蒙菲莎大學
文中提出 point-cloud sensitivity map,用于評估每個點遇到形狀不變量擾動時的識别置信度的方差。點遇到形狀不變的擾動時,評估識别置信度的方差。在靈敏度圖的指導下,提出強形狀不變的白盒攻擊和第一個基于查詢的黑盒攻擊的點雲識别。實驗表明,攻擊在各種識别模型上的效率很高,在黑箱設定下具有很高的不可知性和低查詢成本。
将開源:https://github.com/shikiw/SI-Adv
論文:https://arxiv.org/abs/2203.04041
#CVPR 2022##點雲分類#
ART-Point: Improving Rotation Robustness of Point Cloud Classifiers via Adversarial Rotation
北大&京東
具有旋轉魯棒性的點雲分類器已經在三維深度學習社群中得到了廣泛讨論。大多數提出的方法要麼使用旋轉不變的描述符作為輸入,要麼試圖設計旋轉不變的網絡。然而,由于對原始分類器或輸入空間的修改,這些方法産生的魯棒性模型在 clean aligned 資料集下性能有限。
本次任務中,作者首次表明,點雲分類器的旋轉魯棒性也可以通過對抗性訓練獲得,在旋轉的和幹淨的資料集上都有更好的表現。具體來說,提出 ART-Point 架構,将點雲的旋轉視為一種攻擊,并通過在具有對抗性旋轉的輸入上訓練分類器來提高旋轉魯棒性。提出一種 axis-wise rotation attack(軸向旋轉攻擊),使用預先訓練好的模型的反向傳播梯度來有效地找到對抗性旋轉。為了避免模型對對抗性輸入的過度拟合,建構了旋轉池,利用對抗性旋轉在樣本間的可遷移性來增加訓練資料的多樣性。此外,提出一個快速的 one-step 優化,以有效地達到最終的魯棒模型。
實驗表明,所提出的旋轉攻擊取得了很高的成功率,ART-Point 可以用于大多數現有的分類器,以提高旋轉的魯棒性,同時在幹淨的資料集上表現出比最先進的方法更好的性能。
将開源:https://github.com/robinwang1/ART-Point
論文:https://arxiv.org/abs/2203.03888
#語義分割##CVPR 2022#
Weakly Supervised Semantic Segmentation using Out-of-Distribution Data
首爾大學
弱監督語義分割(WSSS)方法通常建立在從分類器獲得的像素級定位圖上。然而,由于隻對類标簽進行訓練,分類器受到 foreground 和 background (前景和背景)線索(如火車和鐵路)之間的虛假關聯的影響,從根本上限制了WSSS的性能。以前曾有過通過額外監督來解決這個問題的努力。
本次研究,提出一個新的資訊來源來區分前景和背景,分布外(OoD)的資料,或沒有前景物體類别的圖像。特别是,利用分類器有可能做出假陽性預測的 hard OoD。這些樣本通常在背景上帶有關鍵的視覺特征(如鐵路),而分類器經常将其混淆為前景(如火車),是以這些線索讓分類器正确地抑制了虛假的背景線索。獲得這樣的hard OoD不需要大量的标注工作;它隻需要在收集類别标簽的原始努力之上産生一些額外的圖像級别的标簽成本。是以,提出 W-OoD,用于利用 hard OoD,并在Pascal VOC 2012上實作了最先進的性能。
将開源:https://github.com/naver-ai/w-ood
論文:https://arxiv.org/abs/2203.03860