背景
知识蒸馏(knowledge distillation)指的是将预训练好的教师模型的知识通过蒸馏的方式迁移至学生模型,一般来说,教师模型会比学生模型网络容量更大,模型结构更复杂。对于学生而言,主要增益信息来自于更强的模型产出的带有更多可信信息的soft_label。例如下右图中,两个“2”对应的hard_label都是一样的,即0-9分类中,仅“2”类别对应概率为1.0,而soft_label差异就大了,左侧的“2”更像“3”,soft_label在“3”这个负类别上的概率会比其他负类别概率更大,且“2”正类别本身的概率值下降;而右侧的“2”更像“7”,故soft_label在“7”这个负类别上的概率会比其他负类别的概率更大,且“2”正类别本身的概率值下降。
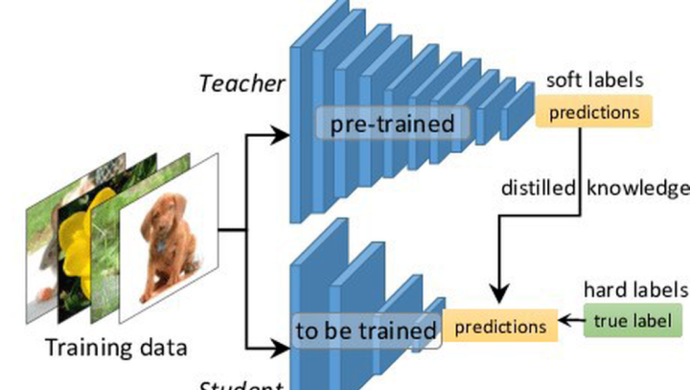

而自蒸馏是什么方法呢?顾名思义是自己蒸馏自己。下意识我们会思考,自己蒸自己为什么会更好呢?自己为什么能学习自己从而超过自己先前学习的成绩呢?本文主要将其归结为“增益信息”的功劳,同传统蒸馏类似,自蒸馏中也可以通过一定的方式提供增益信息,使得蒸馏时能够学习到原始信息不包含的信息,因此得到收益。
自蒸馏概述
自蒸馏(self knowledge distillation)是指不通过新增一个大模型的方式找到一个教师模型,同样可以提供有效增益信息给学生模型,这里的教师模型往往不会比学生模型复杂,但提供的增益信息对于学生模型是有效的增量信息,以提升学生模型效率。该方式可以避免使用更复杂的模型,也可以避免通过一些聚类或者是元计算的步骤生成伪标签。目前该方法在学术界较为新颖,从2020年开始逐渐有顶会浮现相关论文,主要探索任务也较为丰富,在CV、NLP、GNN上均有尝试、任务类型也包括self supervised、unsupervised、semi supervised。
由于没有现成综述论文,在对学术界近两年所有自蒸馏先关论文阅读后做下述粗糙概述,便于对该方向更深入地理解。
根据目前了解到的信息,自蒸馏的方法可以从“增益信息的来源”为维度进行分类,主要分为三大类:
-
伪孪生网络。孪生网络是指两个weighted share的网络,自监督任务中较为流行;伪孪生网络便是两个较为相似且权重独立的网络,在自蒸馏中,一般伪孪生网络使用的teacher和student模型是同一个模型
在这个大类中,可以在时间维度细分为两个子类:
- 同步蒸馏。例如类似自监督学习的方式,在同一个step中,使用两个一样的model作为伪孪生网络进行自蒸馏
- 多阶段蒸馏。例如可以使用前几个epoch的model作为teacher蒸馏后几个epoch的student model
- 类Deep Supervision。即将模型中较深层网络结构作为teacher去蒸馏原模型中较浅层的网络结构
- 第三类就是上述两类的混合使用。
伪孪生网络
这一大类中,主要根据时间维度分为两个子类,即同步蒸馏和多阶段蒸馏
同步蒸馏
其中最为典型的文章便是2021 CVPR workshop的
Distill on the Go: Online knowledge distillation in self-supervised learning。该文章
- 主要认为大模型比小模型在自监督任务上更加受益,为了解决在小模型上自监督预训练的问题,提出了Distill-on-the-Go用在线蒸馏的方法来改善小模型的表征学习效果
- 使用两个权重独立的相同的模型作为伪孪生网络,并且在两个模型中使用互学习的策略让两个模型相互学习,相互作为teacher&student,使得两个模型对于相同样本增强过之后的相似度保证其一致性
网络结构如图所示,同一张图片经过四种不同的随机变换后,输入到参与在线蒸馏的两个网络中,通过MLP映射出的embedding向量,计算两者之间的相似性,利用相似性做一个对称的KL loss分别用于单个模型的训练,每个网络再通过常规对比学习的方法也进行训练,让两者越来越近的同时让其离负样本越来越远。
每一个encoder对比学习的loss就是最普通的对比学习loss,公式如下:
在做互学习时使用KL loss,公式如下:
最终的在线蒸馏时,每一个模型都有两个loss用于训练
该篇文章主要是使用两个网络结构一样的模型作为伪孪生网络通过同步自蒸馏的方式进行相互学习,优点是想法和实现均较为简单,缺点是文章中对比的baseline不是目前的SOTA,有待复现考证。
两阶段蒸馏
其中最经典的文章便是
Self-Knowledge Distillation with Progressive Refinement of Targets(未中),该文章主要
- 使用同一个模型的前一个epoch作为teacher来蒸馏当前epoch的模型
- 提供了一个通过对难易学习的样本权重不一的角度来尝试证明使用了该种自蒸馏的方式work,详见 链接
网络结构主要如上,该文章使用到的Loss对于蒸馏与非蒸馏loss有一个类似于gate的权重设计,并且对这个超参进行了进阶式的调整,其中T为总epoch数,t为当前epoch,旨在随着epoch的迭代,Loss能够更依赖teacher模型输出的结果,而非原本的hard_label
整体Loss 如下
- 有意思的实验
- 文章对前300个epoch正确分类少于50次的样本选取了100个样本进行训练,发现通过自蒸馏的方式,对于100个难学的样本预测的target 类别概率会更大,且最大的概率会更小一些,说明自蒸馏的方式对难学的样本学的更好
Deep Supervision
其中最为经典的文章便是
Be Your Own Teacher: Improve the Performance of Convolutional NeuralNetworks via Self Distillation[ICCV 2019]
该篇文章便是对主网络结构进行改造,通过新增的深层子网络分类器作为teacher,对源网络的浅层部分进行蒸馏学习
网络结构如图所示,它按深度从残差网络中取出三个节点,每一节点额外连接一个由 bottleneck,fc layer, softmax 构成的分类器。它们在训练时,作为 Teacher,为残差网络本身的分类器(Student)进行多方位的指导。整体Loss如下:
主要包含三项,第一下为常用的交叉熵,用于各个分类器各自的学习;第二项用多个 Teacher 分类器对 Student 分类器进行知识蒸馏;第三项中的
表示第
个 Teacher的隐层输出,它表示 hint,用于指导学生网络进行学习。其中,最深分类器的λ和α为零,即最深分类器的监督仅来自标签
- 有意思的实验数据
- 文章对数据添加不同程度的高斯噪声以验证模型的抗噪能力以及收敛能力,发现自蒸馏方式相较于非自蒸馏的方式的抗噪能力更强,且能收敛效果更好
- 自蒸馏的方式能够一定程度上缓解梯度消失的问题。文章发现对于ResBlock中的每层CONV,自蒸馏的方式可以使得其网络的梯度相对更大一些,尤其是对于第一第二层ResBlock效果更佳
在业务场景中的应用
推荐领域中,存在着大量曝光数据,一般来说,对于用户曝光且点击的样本我们认为是正样本,而对于曝光未点击的样本我们认为是负样本。然而在现实生活中,对于曝光未点击的样本可能有很多种情况存在,例如,用户看到了两款手机,都感兴趣,但对其中一款更感兴趣,而导致没有点击另一款;亦或是用户当下也不确定是否想点,并继续浏览导致未点击。
而这部分大量的曝光未点击数据会影响模型学习,如果有一个方法能够告知哪儿些曝光未点击是真的不感兴趣,而哪儿些是可能感兴趣的样本,能够一定程度上帮助模型学习。目前现有的方法大多是手动构造正负样本以缓解该问题,例如youtube早期论文中表述,他们会对每个用户提取相同数量的训练样本以避免高活用户对loss的影响;例如美团会过滤用户最后一次点击行为位置后曝光的坑位数据;或者是随机进行负采样等等,这些方法都得到了一定程度的实际应用也拿到了效果。
本文从label本身考虑,采用两阶段自蒸馏的方式,在不引入额外大模型以及特征的前提下,使用模型本身进行优化。整体流程图如下:
流程非常简单,就是先拿曝光点击样本构建的宽表训练一个模型,再拿该模型对原宽表进行预测,输出一个sotf_label,在结合新的soft_label 修改原模型中的loss部分,使其一并学习该soft_label的distill loss。
这里需要注意,第二次蒸馏训练时,模型的权重需重新初始化后学习。这样的设置主要是因为在这之前我们做过离线实验,发现对所有数据过两个epoch模型一般都会不同程度的过拟合,而在自蒸馏训练时,soft_label涵盖的信息更多,且更为置信,故希望通过重新初始化重新学习的方式使得模型能够突破可能存在的鞍点到更低点。
蒸馏时loss如下:
其中
均为超参
离线尝试了多种soft_labe和hard_label的组合实验
| model_name | auc | gauc_imp | logloss |
| base(长序列target_attention) | 0.72525712 | 0.62604579 | 0.17890248 |
| 标签蒸馏-替换所有label | 0.72404067 | 0.61973608 | 0.192966 |
| 标签蒸馏-仅替换负样本label | 0.73000701 | 0.62675594 | 0.1791612 |
| 标签蒸馏-替换所有label+加入蒸馏loss_λ=α=1 | 0.7288103 | 0.62898916 | 0.17847693 |
| 标签蒸馏-替换所有label+加入蒸馏loss_λ=3_=α=1 | 0.7274471 | 0.62755902 | 0.17878897 |
| 标签蒸馏-仅替换负样本label+加入蒸馏loss_λ=α=1 | 0.72918249 | 0.62731667 | 0.17832688 |
| 标签蒸馏-仅替换负样本label+加入蒸馏loss_λ=3_=α=1 | 0.72947208 | 0.62923213 | 0.17845864 |
可以发现
- 仅替换负样本的效果会优于替换所有样本
- 基于仅替换负样本基础上加入蒸馏loss,gauc还能提升25bp
整体线上效果
天猫新品:
icon区大盘:uctr+4.14%,pctr+4.08%,浏览深度+3.05%,点击次数+7.20%,点击用户平均点击次数+2.84%,人均曝光类目数-4.40%
icon心智用户:uctr+6.01%,pctr+4.28%,浏览深度+5.00%,点击次数+9.29%,点击用户平均点击次数+3.09%,人均曝光类目数-5.24%
结论:
- 自蒸馏是一种非常简单且有效的涨点方法
- 自蒸馏会将用于的兴趣偏好类目预测的更为准确,使得线上曝光类目数降低,与此同时用户的效率更有效得提升,使得用户看到的更多的是用户感兴趣的,且随着浏览深度的提升,pctr等指标也同幅增长,更为健康
天猫u先:
大盘效果:uvctr+4.9%,人均点击量+9.11%,曝光到购买的转化率+2.5%
新客效果:曝光到购买的转化率+1.15%
实际线上case
带着上述结论的假设,尝试去日志中寻找是否有相关case可以印证,结果一下子就找到了有效的用户行为予以佐证。
下图中最左侧是4037347807这个用户在0802号的行为日志,我们重点关注第2、3行行为,当天在天猫新品频道页为其曝光了若干商品,其中第二行的商品650267018429为口罩,648591984573为笔记本电脑,两个商品均曝光未点击;中间是该用户对应行为的商品主图信息,可以发现,曝光的商品大多数均是笔记本电脑,且曝光的电脑中部分用户点击了,部分未点击。
那对于原始的hard_label而言,曝光未点击的众多笔记本电脑都是0,而soft_label可以给出一个非常可信的一个label,即对于650267018429的口罩预测概率为0.046,对于648591984573的电脑概率为0.611。可以看出,soft_label能够很好地对原曝光未点击的负样本进行合理的概率预测,对于第二行650267018429这个较为突兀的口罩预测概率就是最小的,而对于第三行648591984573这个笔记本电脑预测概率则相对较高,是包含曝光点击商品预测概率中的第二大概率。
当时以为这样数据证明就足够了,结果我们在该用户0812号的行为中,发现该用户也点击了第三行648591984573这个笔记本电脑的同款电脑,这更加能够证明自蒸馏训练这种方式预测用户兴趣更为准确。
致谢
自蒸馏能够持续迭代并在业务上取得正向提升离不开贤路师兄的支持与指导;同时也感谢智能场景小组以及躺平算法小组各位同学日常中的探讨与交流。
该方法目前在学术界和工业界均较为新颖,目前能够学习的资料较少,推荐相关也没有相关文章,欢迎大家随时交流沟通,如果有新的想法或者实际落地可以同步一下同时碰撞新的想法。