背景
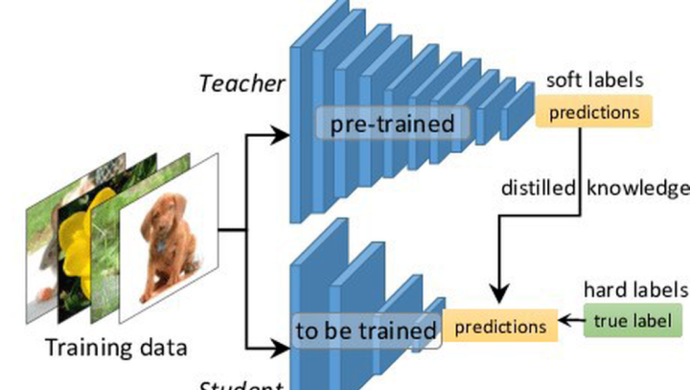
知識蒸餾(knowledge distillation)指的是将預訓練好的教師模型的知識通過蒸餾的方式遷移至學生模型,一般來說,教師模型會比學生模型網絡容量更大,模型結構更複雜。對于學生而言,主要增益資訊來自于更強的模型産出的帶有更多可信資訊的soft_label。例如下右圖中,兩個“2”對應的hard_label都是一樣的,即0-9分類中,僅“2”類别對應機率為1.0,而soft_label差異就大了,左側的“2”更像“3”,soft_label在“3”這個負類别上的機率會比其他負類别機率更大,且“2”正類别本身的機率值下降;而右側的“2”更像“7”,故soft_label在“7”這個負類别上的機率會比其他負類别的機率更大,且“2”正類别本身的機率值下降。

而自蒸餾是什麼方法呢?顧名思義是自己蒸餾自己。下意識我們會思考,自己蒸自己為什麼會更好呢?自己為什麼能學習自己進而超過自己先前學習的成績呢?本文主要将其歸結為“增益資訊”的功勞,同傳統蒸餾類似,自蒸餾中也可以通過一定的方式提供增益資訊,使得蒸餾時能夠學習到原始資訊不包含的資訊,是以得到收益。
自蒸餾概述
自蒸餾(self knowledge distillation)是指不通過新增一個大模型的方式找到一個教師模型,同樣可以提供有效增益資訊給學生模型,這裡的教師模型往往不會比學生模型複雜,但提供的增益資訊對于學生模型是有效的增量資訊,以提升學生模型效率。該方式可以避免使用更複雜的模型,也可以避免通過一些聚類或者是元計算的步驟生成僞标簽。目前該方法在學術界較為新穎,從2020年開始逐漸有頂會浮現相關論文,主要探索任務也較為豐富,在CV、NLP、GNN上均有嘗試、任務類型也包括self supervised、unsupervised、semi supervised。
由于沒有現成綜述論文,在對學術界近兩年所有自蒸餾先關論文閱讀後做下述粗糙概述,便于對該方向更深入地了解。
根據目前了解到的資訊,自蒸餾的方法可以從“增益資訊的來源”為次元進行分類,主要分為三大類:
-
僞孿生網絡。孿生網絡是指兩個weighted share的網絡,自監督任務中較為流行;僞孿生網絡便是兩個較為相似且權重獨立的網絡,在自蒸餾中,一般僞孿生網絡使用的teacher和student模型是同一個模型
在這個大類中,可以在時間次元細分為兩個子類:
- 同步蒸餾。例如類似自監督學習的方式,在同一個step中,使用兩個一樣的model作為僞孿生網絡進行自蒸餾
- 多階段蒸餾。例如可以使用前幾個epoch的model作為teacher蒸餾後幾個epoch的student model
- 類Deep Supervision。即将模型中較深層網絡結構作為teacher去蒸餾原模型中較淺層的網絡結構
- 第三類就是上述兩類的混合使用。
僞孿生網絡
這一大類中,主要根據時間次元分為兩個子類,即同步蒸餾和多階段蒸餾
同步蒸餾
其中最為典型的文章便是2021 CVPR workshop的
Distill on the Go: Online knowledge distillation in self-supervised learning。該文章
- 主要認為大模型比小模型在自監督任務上更加受益,為了解決在小模型上自監督預訓練的問題,提出了Distill-on-the-Go用線上蒸餾的方法來改善小模型的表征學習效果
- 使用兩個權重獨立的相同的模型作為僞孿生網絡,并且在兩個模型中使用互學習的政策讓兩個模型互相學習,互相作為teacher&student,使得兩個模型對于相同樣本增強過之後的相似度保證其一緻性
網絡結構如圖所示,同一張圖檔經過四種不同的随機變換後,輸入到參與線上蒸餾的兩個網絡中,通過MLP映射出的embedding向量,計算兩者之間的相似性,利用相似性做一個對稱的KL loss分别用于單個模型的訓練,每個網絡再通過正常對比學習的方法也進行訓練,讓兩者越來越近的同時讓其離負樣本越來越遠。
每一個encoder對比學習的loss就是最普通的對比學習loss,公式如下:
在做互學習時使用KL loss,公式如下:
最終的線上蒸餾時,每一個模型都有兩個loss用于訓練
該篇文章主要是使用兩個網絡結構一樣的模型作為僞孿生網絡通過同步自蒸餾的方式進行互相學習,優點是想法和實作均較為簡單,缺點是文章中對比的baseline不是目前的SOTA,有待複現考證。
兩階段蒸餾
其中最經典的文章便是
Self-Knowledge Distillation with Progressive Refinement of Targets(未中),該文章主要
- 使用同一個模型的前一個epoch作為teacher來蒸餾目前epoch的模型
- 提供了一個通過對難易學習的樣本權重不一的角度來嘗試證明使用了該種自蒸餾的方式work,詳見 連結
網絡結構主要如上,該文章使用到的Loss對于蒸餾與非蒸餾loss有一個類似于gate的權重設計,并且對這個超參進行了進階式的調整,其中T為總epoch數,t為目前epoch,旨在随着epoch的疊代,Loss能夠更依賴teacher模型輸出的結果,而非原本的hard_label
整體Loss 如下
- 有意思的實驗
- 文章對前300個epoch正确分類少于50次的樣本選取了100個樣本進行訓練,發現通過自蒸餾的方式,對于100個難學的樣本預測的target 類别機率會更大,且最大的機率會更小一些,說明自蒸餾的方式對難學的樣本學的更好
Deep Supervision
其中最為經典的文章便是
Be Your Own Teacher: Improve the Performance of Convolutional NeuralNetworks via Self Distillation[ICCV 2019]
該篇文章便是對主網絡結構進行改造,通過新增的深層子網絡分類器作為teacher,對源網絡的淺層部分進行蒸餾學習
網絡結構如圖所示,它按深度從殘差網絡中取出三個節點,每一節點額外連接配接一個由 bottleneck,fc layer, softmax 構成的分類器。它們在訓練時,作為 Teacher,為殘差網絡本身的分類器(Student)進行多方位的指導。整體Loss如下:
主要包含三項,第一下為常用的交叉熵,用于各個分類器各自的學習;第二項用多個 Teacher 分類器對 Student 分類器進行知識蒸餾;第三項中的
表示第
個 Teacher的隐層輸出,它表示 hint,用于指導學生網絡進行學習。其中,最深分類器的λ和α為零,即最深分類器的監督僅來自标簽
- 有意思的實驗資料
- 文章對資料添加不同程度的高斯噪聲以驗證模型的抗噪能力以及收斂能力,發現自蒸餾方式相較于非自蒸餾的方式的抗噪能力更強,且能收斂效果更好
- 自蒸餾的方式能夠一定程度上緩解梯度消失的問題。文章發現對于ResBlock中的每層CONV,自蒸餾的方式可以使得其網絡的梯度相對更大一些,尤其是對于第一第二層ResBlock效果更佳
在業務場景中的應用
推薦領域中,存在着大量曝光資料,一般來說,對于使用者曝光且點選的樣本我們認為是正樣本,而對于曝光未點選的樣本我們認為是負樣本。然而在現實生活中,對于曝光未點選的樣本可能有很多種情況存在,例如,使用者看到了兩款手機,都感興趣,但對其中一款更感興趣,而導緻沒有點選另一款;亦或是使用者當下也不确定是否想點,并繼續浏覽導緻未點選。
而這部分大量的曝光未點選資料會影響模型學習,如果有一個方法能夠告知哪兒些曝光未點選是真的不感興趣,而哪兒些是可能感興趣的樣本,能夠一定程度上幫助模型學習。目前現有的方法大多是手動構造正負樣本以緩解該問題,例如youtube早期論文中表述,他們會對每個使用者提取相同數量的訓練樣本以避免高活使用者對loss的影響;例如美團會過濾使用者最後一次點選行為位置後曝光的坑位資料;或者是随機進行負采樣等等,這些方法都得到了一定程度的實際應用也拿到了效果。
本文從label本身考慮,采用兩階段自蒸餾的方式,在不引入額外大模型以及特征的前提下,使用模型本身進行優化。整體流程圖如下:
流程非常簡單,就是先拿曝光點選樣本建構的寬表訓練一個模型,再拿該模型對原寬表進行預測,輸出一個sotf_label,在結合新的soft_label 修改原模型中的loss部分,使其一并學習該soft_label的distill loss。
這裡需要注意,第二次蒸餾訓練時,模型的權重需重新初始化後學習。這樣的設定主要是因為在這之前我們做過離線實驗,發現對所有資料過兩個epoch模型一般都會不同程度的過拟合,而在自蒸餾訓練時,soft_label涵蓋的資訊更多,且更為置信,故希望通過重新初始化重新學習的方式使得模型能夠突破可能存在的鞍點到更低點。
蒸餾時loss如下:
其中
均為超參
離線嘗試了多種soft_labe和hard_label的組合實驗
| model_name | auc | gauc_imp | logloss |
| base(長序列target_attention) | 0.72525712 | 0.62604579 | 0.17890248 |
| 标簽蒸餾-替換所有label | 0.72404067 | 0.61973608 | 0.192966 |
| 标簽蒸餾-僅替換負樣本label | 0.73000701 | 0.62675594 | 0.1791612 |
| 标簽蒸餾-替換所有label+加入蒸餾loss_λ=α=1 | 0.7288103 | 0.62898916 | 0.17847693 |
| 标簽蒸餾-替換所有label+加入蒸餾loss_λ=3_=α=1 | 0.7274471 | 0.62755902 | 0.17878897 |
| 标簽蒸餾-僅替換負樣本label+加入蒸餾loss_λ=α=1 | 0.72918249 | 0.62731667 | 0.17832688 |
| 标簽蒸餾-僅替換負樣本label+加入蒸餾loss_λ=3_=α=1 | 0.72947208 | 0.62923213 | 0.17845864 |
可以發現
- 僅替換負樣本的效果會優于替換所有樣本
- 基于僅替換負樣本基礎上加入蒸餾loss,gauc還能提升25bp
整體線上效果
天貓新品:
icon區大盤:uctr+4.14%,pctr+4.08%,浏覽深度+3.05%,點選次數+7.20%,點選使用者平均點選次數+2.84%,人均曝光類目數-4.40%
icon心智使用者:uctr+6.01%,pctr+4.28%,浏覽深度+5.00%,點選次數+9.29%,點選使用者平均點選次數+3.09%,人均曝光類目數-5.24%
結論:
- 自蒸餾是一種非常簡單且有效的漲點方法
- 自蒸餾會将用于的興趣偏好類目預測的更為準确,使得線上曝光類目數降低,與此同時使用者的效率更有效得提升,使得使用者看到的更多的是使用者感興趣的,且随着浏覽深度的提升,pctr等名額也同幅增長,更為健康
天貓u先:
大盤效果:uvctr+4.9%,人均點選量+9.11%,曝光到購買的轉化率+2.5%
新客效果:曝光到購買的轉化率+1.15%
實際線上case
帶着上述結論的假設,嘗試去日志中尋找是否有相關case可以印證,結果一下子就找到了有效的使用者行為予以佐證。
下圖中最左側是4037347807這個使用者在0802号的行為日志,我們重點關注第2、3行行為,當天在天貓新品頻道頁為其曝光了若幹商品,其中第二行的商品650267018429為口罩,648591984573為筆記本電腦,兩個商品均曝光未點選;中間是該使用者對應行為的商品主圖資訊,可以發現,曝光的商品大多數均是筆記本電腦,且曝光的電腦中部分使用者點選了,部分未點選。
那對于原始的hard_label而言,曝光未點選的衆多筆記本電腦都是0,而soft_label可以給出一個非常可信的一個label,即對于650267018429的口罩預測機率為0.046,對于648591984573的電腦機率為0.611。可以看出,soft_label能夠很好地對原曝光未點選的負樣本進行合理的機率預測,對于第二行650267018429這個較為突兀的口罩預測機率就是最小的,而對于第三行648591984573這個筆記本電腦預測機率則相對較高,是包含曝光點選商品預測機率中的第二大機率。
當時以為這樣資料證明就足夠了,結果我們在該使用者0812号的行為中,發現該使用者也點選了第三行648591984573這個筆記本電腦的同款電腦,這更加能夠證明自蒸餾訓練這種方式預測使用者興趣更為準确。
緻謝
自蒸餾能夠持續疊代并在業務上取得正向提升離不開賢路師兄的支援與指導;同時也感謝智能場景小組以及躺平算法小組各位同學日常中的探讨與交流。
該方法目前在學術界和工業界均較為新穎,目前能夠學習的資料較少,推薦相關也沒有相關文章,歡迎大家随時交流溝通,如果有新的想法或者實際落地可以同步一下同時碰撞新的想法。