前言
阿里云函数计算(简称 FC )提供了一种事件驱动的计算模型。函数的执行是由事件驱动的,函数计算触发器描述了一组规则,当某个事件满足这些规则,事件源就会触发相应的函数。函数计算已经将
对象存储作为一个事件源用于触发函数, 用于对存入oss的文件进行自动化处理:
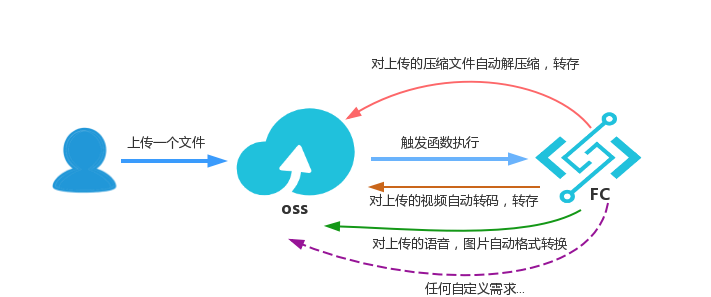
如上图所示,阿里云对象存储和函数计算无缝集成。您可以为各种类型的事件设置处理函数,当OSS系统捕获到指定类型的事件后,会自动调用函数处理。例如,您可以设置函数来处理PutObject事件,当您调用OSS PutObject API上传图片到OSS后,相关联的函数会自动触发来处理该图片。
在本文中,以用户上传超大压缩文件( zip 类型)到 oss, oss 系统捕获 PutObjec/PostObject 的事件, 自动触发函数执行, 函数将压缩文件解压,并将对应的解压文件放在oss 指定的 bucket 的某个目录下。 比如在bucket myzipfilebucket 的
source
目录是上传压缩文件的目录,
processed
目录是解压后压缩文件存放的目录
方法
在本文中,以python3 runtime 为例,一步一步慢慢展示fc的能力
简单法
因为 FC 的临时目录的空间大小为512M,如果使用落盘,明显是下下策, 不仅增加 io 时间, 而且 512M 的限制基本让人敬而远之了。所以我们把一切在内存中完成, 于是有下面的解决方案, FC 从内网中拉取 OSS 中的压缩文件,然后一切在内存中完成,将解压后的文件的 bytes 上传到指定 bucket 中目录, 于是有了下面的代码:
# -*- coding: utf-8 -*-
import oss2, json
import zipfile
import os, io
import logging
import chardet
LOGGER = logging.getLogger()
def handler(event, context):
"""
The object from OSS will be decompressed automatically .
param: event: The OSS event json string. Including oss object uri and other information.
For detail info, please refer https://help.aliyun.com/document_detail/70140.html?spm=a2c4g.11186623.6.578.5eb8cc74AJCA9p#OSS
param: context: The function context, including credential and runtime info.
For detail info, please refer to https://help.aliyun.com/document_detail/56316.html#using-context
"""
evt_lst = json.loads(event)
creds = context.credentials
auth=oss2.StsAuth(
creds.access_key_id,
creds.access_key_secret,
creds.security_token)
evt = evt_lst['events'][0]
bucket_name = evt['oss']['bucket']['name']
endpoint = 'oss-' + evt['region'] + '-internal.aliyuncs.com'
bucket = oss2.Bucket(auth, endpoint, bucket_name)
object_name = evt['oss']['object']['key']
"""
When a source/ prefix object is placed in an OSS, it is hoped that the object will be decompressed and then stored in the OSS as processed/ prefixed.
For example, source/a.zip will be processed as processed/a/...
"source /", "processed/" can be changed according to the user's requirements."""
file_type = os.path.splitext(object_name)[1]
if file_type != ".zip":
raise RuntimeError('{} filetype is not zip'.format(object_name))
newKey = object_name.replace("source/", "processed/")
remote_stream = bucket.get_object(object_name)
if not remote_stream:
raise RuntimeError('failed to get oss object. bucket: %s. object: %s' % (bucket_name, object_name))
zip_buffer = io.BytesIO(remote_stream.read())
LOGGER.info('download object from oss success: {}'.format(object_name))
newKey = newKey.replace(".zip", "/")
with zipfile.ZipFile(zip_buffer) as zip_file:
for name in zip_file.namelist():
with zip_file.open(name) as file_obj:
# fix chinese directory name garbled problem
try:
name = name.encode(encoding='cp437')
except:
name = name.encode(encoding='utf-8')
detect = chardet.detect( (name*100)[0:100] )
confidence = detect["confidence"]
if confidence >= 0.8:
try:
name = name.decode(encoding=detect["encoding"])
except:
name = name.decode(encoding="gb2312")
else:
name = name.decode(encoding="gb2312")
bucket.put_object(newKey + name, file_obj.read()) - 优点
- 方法简单,一切在内存中完成,适合较小的压缩文件解压
- 不足
- 有内存的限制,假设压缩文件稍微大点,就很容易超出函数计算执行环境最大内存 3G 的限制
- 假设压缩文件大小差异很大,以最大压缩文件消耗的内存设置函数内存规格, 增加函数执行费用
流式法
完整的代码示例请在附件下载
注:附件的流式法的代码中的入口函数 py 文件可能没有及时更新, 下载代码下来后, 直接copy 文章中的代码更新入口函数即可
很快,我们自然想到不能完全把压缩文件的内容全部通过 FC 作为 中转站来处理,如果我们先获取压缩文件的 meta 信息,比如我们先拉取压缩文件中的 meta 信息的字节流(很小), 分析出这个大的压缩文件里面有哪些文件,这些文件对应到压缩文件字节流中的起止位置信息;通过这些信息, 压缩文件里面的每个文件都能构造出一个
file-like object, 那么在 FC 这边, 只需要将 get 的 file-like object 进行解压,同时将解压后的内容 as a file-like object put 到指定的 bucket 目录。 完全没必要把所有内容一下子拖到这里统一加工。
-
改造 zipfile
在 python 中,我们继续使用
zipfile 这个lib,看起来是这个库支持参数是 file-like object, 但是这个库要求 file-like object 具有 seek 和 tell 接口, oss get_object 获得GetObjectResult
seek
tell
- 同时,构造出能被 zipfile 支持的file-like object
# -*- coding: utf-8 -*- import oss2 from oss2 import utils, models import ossZipfile as zipfile zipfile_support_oss = zipfile # support upload to oss as a file-like object def make_crc_adapter(data, init_crc=0): data = utils.to_bytes(data) # file-like object if hasattr(data,'read'): return utils._FileLikeAdapter(data, crc_callback=utils.Crc64(init_crc)) utils.make_crc_adapter = make_crc_adapter class OssStreamFileLikeObject(object): def __init__(self, bucket, key): super(OssStreamFileLikeObject, self).__init__() self._bucket = bucket self._key = key self._meta_data = self._bucket.get_object_meta(self._key) @property def bucket(self): return self._bucket @property def key(self): return self._key @property def filesize(self): return self._meta_data.content_length def get_reader(self, begin, end): begin = begin if begin >= 0 else 0 end = end if end > 0 else self.filesize - 1 end = end if end < self.filesize else self.filesize - 1 begin = begin if begin < end else end return self._bucket.get_object(self._key, byte_range=(begin, end)) def get_content_bytes(self, begin, end): reader = self.get_reader(begin, end) return reader.read() def get_last_content_bytes(self, offset): return self.get_content_bytes(self.filesize-offset, self.filesize-1) - 入口函数
# -*- coding: utf-8 -*-
'''
声明:
这个函数针对文件和文件夹命名编码是如下格式:
1. mac/linux 系统, 默认是utf-8
2. windows 系统, 默认是gb2312, 也可以是utf-8
对于其他编码,我们这里尝试使用chardet这个库进行编码判断, 但是这个并不能保证100% 正确,
建议用户先调试函数,如果有必要改写这个函数,并保证调试通过
函数最新进展可以关注该blog: https://yq.aliyun.com/articles/680958
Statement:
This function names and encodes files and folders as follows:
1. MAC/Linux system, default is utf-8
2. For Windows, the default is gb2312 or utf-8
For other encodings, we try to use the chardet library for coding judgment here,
but this is not guaranteed to be 100% correct.
If necessary to rewrite this function, and ensure that the debugging pass
'''
import helper
import oss2, json
import os
import logging
import chardet
"""
When a source/ prefix object is placed in an OSS, it is hoped that the object will be decompressed and then stored in the OSS as processed/ prefixed.
For example, source/a.zip will be processed as processed/a/...
"Source /", "processed/" can be changed according to the user's requirements.
detail: https://yq.aliyun.com/articles/680958
"""
# Close the info log printed by the oss SDK
logging.getLogger("oss2.api").setLevel(logging.ERROR)
logging.getLogger("oss2.auth").setLevel(logging.ERROR)
LOGGER = logging.getLogger()
def handler(event, context):
"""
The object from OSS will be decompressed automatically .
param: event: The OSS event json string. Including oss object uri and other information.
For detail info, please refer https://help.aliyun.com/document_detail/70140.html?spm=a2c4g.11186623.6.578.5eb8cc74AJCA9p#OSS
param: context: The function context, including credential and runtime info.
For detail info, please refer to https://help.aliyun.com/document_detail/56316.html#using-context
"""
evt_lst = json.loads(event)
creds = context.credentials
auth=oss2.StsAuth(
creds.access_key_id,
creds.access_key_secret,
creds.security_token)
evt = evt_lst['events'][0]
bucket_name = evt['oss']['bucket']['name']
endpoint = 'oss-' + evt['region'] + '-internal.aliyuncs.com'
bucket = oss2.Bucket(auth, endpoint, bucket_name)
object_name = evt['oss']['object']['key']
if "ObjectCreated:PutSymlink" == evt['eventName']:
object_name = bucket.get_symlink(object_name).target_key
if object_name == "":
raise RuntimeError('{} is invalid symlink file'.format(evt['oss']['object']['key']))
file_type = os.path.splitext(object_name)[1]
if file_type != ".zip":
raise RuntimeError('{} filetype is not zip'.format(object_name))
LOGGER.info("start to decompress zip file = {}".format(object_name))
lst = object_name.split("/")
zip_name = lst[-1]
PROCESSED_DIR = os.environ.get("PROCESSED_DIR", "")
if PROCESSED_DIR and PROCESSED_DIR[-1] != "/":
PROCESSED_DIR += "/"
newKey = PROCESSED_DIR + zip_name
zip_fp = helper.OssStreamFileLikeObject(bucket, object_name)
newKey = newKey.replace(".zip", "/")
with helper.zipfile_support_oss.ZipFile(zip_fp) as zip_file:
for name in zip_file.namelist():
with zip_file.open(name) as file_obj:
try:
name = name.encode(encoding='cp437')
except:
name = name.encode(encoding='utf-8')
# the string to be detect is long enough, the detection result accuracy is higher
detect = chardet.detect( (name*100)[0:100] )
confidence = detect["confidence"]
if confidence > 0.8:
try:
name = name.decode(encoding=detect["encoding"])
except:
name = name.decode(encoding='gb2312')
else:
name = name.decode(encoding="gb2312")
bucket.put_object(newKey + name, file_obj) -
- 可以突破内存限制,小内存的函数也可以干大压缩文件文件的自动解压存放工作

函数计算实现 oss 上传超大 zip 压缩文件的自动解压处理
- 可以突破内存限制,小内存的函数也可以干大压缩文件文件的自动解压存放工作
-
- 对于较小的压缩文件,不如简单的方法来的简洁和直接
总结
本文针对 oss 上传 zip 压缩文件进行自动解压进行了一些方案的探讨与尝试, 分析了两种方案各自的优点和不足。 但是这两种方法都有一个共同的限制,就是函数执行时间最大为15分钟,如果压缩文件足够大和足够复杂(里面有很多的小文件), 需要合理评估时间, 执行时间 = 解压时间(纯cpu计算,这个跟设置函数内存规格大小成线性关系,需要合理设置) + 网络io 时间(走内网); 一般来说本地(两核3G的配置)解压时间在10分钟以内的, FC 应该都有能力处理。