目录
(一) java集合分类
(1) Iterable接口
1. 内部定义的方法
1.1 iterator方法
1.2 forEach方法
1.3 spliterator方法
2. Collection接口 extend Iterable
2.1 内部定义的方法
2.2 继承Collection的主要接口
2.2.1 List extend Collection
2.2.2 Set extend Collection
2.2.3 Queue extend Collection
(2) Map接口
(二)总结
之前大概分为三种,<code>Set</code>,<code>List</code>,<code>Map</code>三种,JDK5之后,增加<code>Queue</code>.主要由<code>Collection</code>和<code>Map</code>两个接口衍生出来,同时<code>Collection</code>接口继承<code>Iterable</code>接口,所以我们也可以说java里面的集合类主要是由<code>Iterable</code>和<code>Map</code>两个接口以及他们的子接口或者其实现类组成。我们可以认为<code>Collection</code>接口定义了单列集合的规范,每次只能存储一个元素,而<code>Map</code>接口定义了双列集合的规范,每次能存储一对元素。
<code>Iterable</code>接口:主要是实现遍历功能
<code>Collection</code>接口: 允许重复
<code>Set</code>接口:无序,元素不可重复,访问元素只能通过元素本身来访问。
<code>List</code>接口:有序且可重复,可以根据元素的索引来访问集合中的元素。
<code>Queue</code>接口:队列,一般先进先出,可重复
<code>Map</code>接口:映射关系,简单理解为键值对<Key,Value>,Key不可重复,与<code>Collection</code>接口关系不大,只是个别函数使用到。
整个接口框架关系如下(来自百度百科):
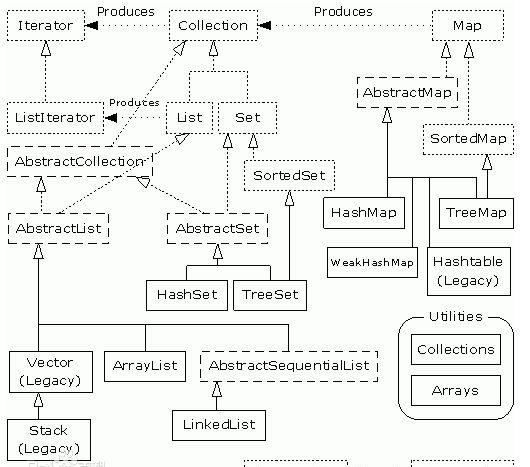
java集合 最源头的接口,实现这个接口的作用主要是集合对象可以通过迭代器去遍历每一个元素。

源码如下:
从上面可以看出,<code>foreach</code>迭代以及可分割迭代,都加了<code>default</code>关键字,这个是Java 8 新的关键字,以前接口的所有接口,具体子类都必须实现,而对于<code>deafult</code>关键字标识的方法,其子类可以不用实现,这也是接口规范发生变化的一点。
下面我们分别展示三个接口的调用:
当然也可以使用<code>for-each loop</code>方式遍历
但是实际上,这种写法在<code>class</code>文件中也是会转成迭代器形式,这只是一个语法糖。<code>class</code>文件如下:
需要注意的一点是,迭代遍历的时候,如果删除或者添加元素,都会抛出修改异常,这是由于快速失败<code>【fast-fail】</code>机制,属于一种自我保护的机制。
从下面的错误我们可以看出,第一个元素是有被打印出来的,也就是remove操作是成功的,只是遍历到第二个元素的时候,迭代器检查,发现被改变了,所以抛出了异常。
其实就是把对每一个元素的操作当成了一个对象传递进来,对每一个元素进行处理。
同时,我们只要实现<code>Consumer</code>接口,就可以自定义动作,如果不自定义,默认迭代顺序是按照元素的顺序。
输出的结果:
这是一个为了并行遍历数据元素而设计的迭代方法,返回的是<code>Spliterator</code>,是专门并行遍历的迭代器。以发挥多核时代的处理器性能,java默认在集合框架中提供了一个默认的<code>Spliterator</code>实现,底层也就是<code>Stream.isParallel()</code>实现的,我们可以看一下源码:
使用的方法如下:
<code>tryAdvance()</code> 一个一个元素进行遍历
<code>forEachRemaining()</code> 顺序地分块遍历
<code>trySplit()</code>进行分区形成另外的 <code>Spliterator</code>,使用在并行操作中,分出来的是前面一半,就是不断把前面一部分分出来
结果如下:
还有一些其他的用法在这里就不列举了,主要是<code>trySplit()</code>之后,可以用于多线程遍历。理想的时候,可以平均分成两半,有利于并行计算,但是不是一定平分的。
<code>Collection</code>接口可以算是集合类的一个根接口之一,一般不能够直接使用,只是定义了一个规范,定义了添加,删除等管理数据的方法。继承<code>Collection</code>接口的有<code>List</code>,<code>Set</code>,<code>Queue</code>,不过<code>Queue</code>定义了自己的一些接口,相对来说和其他的差异比较大。
里面获取并行流的方法<code>parallelStream()</code>,其实就是通过默认的<code>ForkJoinPool</code>(主要用来使用分治法(Divide-and-Conquer Algorithm)来解决问题),提高多线程任务的速度。我们可以使用ArrayList来演示一下平行处理能力。例如下面的例子,输出的顺序就不一定是1,2,3...,可能是乱序的,这是因为任务会被分成多个小任务,任务执行是没有特定的顺序的。
graph LR;
Collection -->List-有顺序,可重复
List-有顺序,可重复 -->LinkedList-使用链表实现,线程不安全
List-有顺序,可重复 -->ArrayList-数组实现,线程不安全
List-有顺序,可重复 -->Vector-数组实现,线程安全
Vector-数组实现,线程安全 -->Stack-堆栈,先进后出
Collection-->Set-不可重复,内部排序
Set-不可重复,内部排序-->HashSet-hash表存储
HashSet-hash表存储-->LinkHashSet-链表维护插入顺序
Set-不可重复,内部排序-->TreeSet-二叉树实现,排序
Collection-->Queue-队列,先进先出
继承于<code>Collection</code>接口,有顺序,取出的顺序与存入的顺序一致,有索引,可以根据索引获取数据,允许存储重复的元素,可以放入为null的元素。
最常见的三个实现类就是<code>ArrayList</code>,<code>Vector</code>,<code>LinkedList</code>,<code>ArrayList</code>和<code>Vector</code>都是内部封装了对数组的操作,唯一不同的是,<code>Vector</code>是线程安全的,而<code>ArrayList</code>不是,理论上<code>ArrayList</code>操作的效率会比<code>Vector</code>好一些。
里面是接口定义的方法:
上面的方法都比较简单,值得一提的是里面出现了<code>ListIterator</code>,这是一个功能更加强大的迭代器,继承于<code>Iterator</code>,只能用于<code>List</code>类型的访问,拓展功能例如:通过调用<code>listIterator()</code>方法获得一个指向List开头的<code>ListIterator</code>,也可以调用<code>listIterator(n)</code>获取一个指定索引为n的元素的<code>ListIterator</code>,这是一个可以双向移动的迭代器。
操作数组索引的时候需要注意,由于List的实现类底层很多都是数组,所以索引越界会报错<code>IndexOutOfBoundsException</code>。
说起List的实现子类:
<code>ArrayList</code>:底层存储结构是数组结构,增加删除比较慢,查找比较快,是最常用的List集合。线程不安全。
<code>LinkedList</code>:底层是链表结构,增加删除比较快,但是查找比较慢。线程不安全。
<code>Vector</code>:和ArrayList差不多,但是是线程安全的,即同步。
<code>Set</code>接口,不允许放入重复的元素,也就是如果相同,则只存储其中一个。
下面是源码方法:
主要的子类:
<code>HashSet</code>
允许空值
通过<code>HashCode</code>方法计算获取<code>hash</code>值,确定存储位置,无序。
<code>LinkedHashSet</code>
<code>HashSet</code>的子类
有顺序
<code>TreeSet</code>
如果无参数构建<code>Set</code>,则需要实现<code>Comparable</code>方法。
亦可以创建时传入比较方法,用于排序。
队列接口,在<code>Collection</code>接口的接触上添加了增删改查接口定义,一般默认是先进先出,即<code>FIFO</code>,除了优先队列和栈,优先队列是自己定义了排序的优先顺序,队列中不允许放入null元素。
下面是源码:
主要的子接口以及实现类有:
Deque(接口):Queue的子接口,双向队列,可以从两边存取
ArrayDeque:Deque的实现类,底层用数组实现,数据存贮在数组中
AbstractQueue:Queue的子接口,仅实现了add、remove和element三个方法
PriorityQueue:按照默认或者自己定义的顺序来排序元素,底层使用堆(完全二叉树)实现,使用动态数组实现,
BlockingQueue: 在java.util.concurrent包中,阻塞队列,满足当前无法处理的操作。
定义双列集合的规范<code>Map<K,V></code>,每次存储一对元素,即<code>key</code>和<code>value</code>。
<code>key</code>的类型可以和<code>value</code>的类型相同,也可以不同,任意的引用类型都可以。
<code>key</code>是不允许重复的,但是<code>value</code>是可以重复的,所谓重复是指计算的<code>hash</code>值。
下面的源码的方法:
值得注意的是,Map里面定义了一个Entry类,其实就是定义了一个存储数据的类型,一个entry就是一个<code><key,value></code>.
Map的常用的实现子类:
<code>HashMap</code>:由数组和链表组成,线程不安全,无序。
<code>LinkedHashMap</code>:如果我们需要是有序的,那么就需要它,时间和空间效率没有<code>HashMap</code>那么高,底层是维护一条双向链表,保证了插入的顺序。
<code>ConcurrentHashMap</code>:线程安全,1.7JDK使用锁分离,每一段Segment都有自己的独立锁,相对来说效率也比较高。JDK1.8抛弃了Segment,使用Node数组+链表和红黑树实现,在线程安全控制上使用<code>Synchronize</code>和<code>CAS</code>,可以认为是优化的线程安全的<code>HashMap</code>。
<code>HashTable</code>:对比与<code>HashMap</code>主要是使用关键字<code>synchronize</code>,加上同步锁,线程安全。
这些集合原始接口到底是什么?为什么需要?
我想,这些接口其实都是一种规则/规范的定义,如果不这么做也可以,所有的子类自己实现,但是从迭代以及维护的角度来说,这就是一种抽象或者分类,比如定义了<code>Iterator</code>接口,某一些类就可以去继承或者实现,那就得遵守这个规范/契约。可以有所拓展,每个子类的拓展不一样,所以每个类就各有所长,但是都有一个中心,就是原始的集合接口。比如实现<code>Map</code>接口的所有类的中心思想都不变,都是<code><key,value></code>只是各有所长,各分千秋,形成了大千集合世界。
此文章仅代表自己(本菜鸟)学习积累记录,或者学习笔记,如有侵权,请联系作者删除。人无完人,文章也一样,文笔稚嫩,在下不才,勿喷,如果有错误之处,还望指出,感激不尽~
技术之路不在一时,山高水长,纵使缓慢,驰而不息。
公众号:秦怀杂货店