目錄
(一) java集合分類
(1) Iterable接口
1. 内部定義的方法
1.1 iterator方法
1.2 forEach方法
1.3 spliterator方法
2. Collection接口 extend Iterable
2.1 内部定義的方法
2.2 繼承Collection的主要接口
2.2.1 List extend Collection
2.2.2 Set extend Collection
2.2.3 Queue extend Collection
(2) Map接口
(二)總結
之前大概分為三種,<code>Set</code>,<code>List</code>,<code>Map</code>三種,JDK5之後,增加<code>Queue</code>.主要由<code>Collection</code>和<code>Map</code>兩個接口衍生出來,同時<code>Collection</code>接口繼承<code>Iterable</code>接口,是以我們也可以說java裡面的集合類主要是由<code>Iterable</code>和<code>Map</code>兩個接口以及他們的子接口或者其實作類組成。我們可以認為<code>Collection</code>接口定義了單列集合的規範,每次隻能存儲一個元素,而<code>Map</code>接口定義了雙列集合的規範,每次能存儲一對元素。
<code>Iterable</code>接口:主要是實作周遊功能
<code>Collection</code>接口: 允許重複
<code>Set</code>接口:無序,元素不可重複,通路元素隻能通過元素本身來通路。
<code>List</code>接口:有序且可重複,可以根據元素的索引來通路集合中的元素。
<code>Queue</code>接口:隊列,一般先進先出,可重複
<code>Map</code>接口:映射關系,簡單了解為鍵值對<Key,Value>,Key不可重複,與<code>Collection</code>接口關系不大,隻是個别函數使用到。
整個接口架構關系如下(來自百度百科):
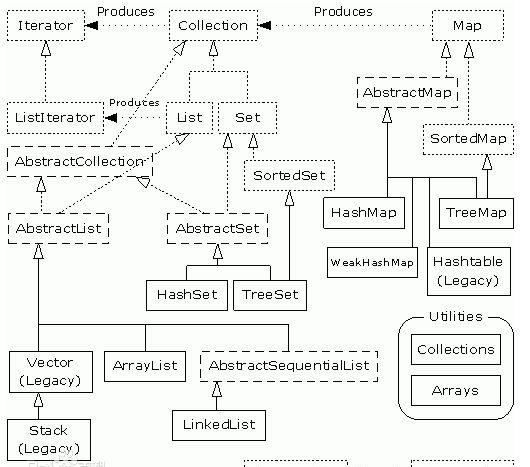
java集合 最源頭的接口,實作這個接口的作用主要是集合對象可以通過疊代器去周遊每一個元素。

源碼如下:
從上面可以看出,<code>foreach</code>疊代以及可分割疊代,都加了<code>default</code>關鍵字,這個是Java 8 新的關鍵字,以前接口的所有接口,具體子類都必須實作,而對于<code>deafult</code>關鍵字辨別的方法,其子類可以不用實作,這也是接口規範發生變化的一點。
下面我們分别展示三個接口的調用:
當然也可以使用<code>for-each loop</code>方式周遊
但是實際上,這種寫法在<code>class</code>檔案中也是會轉成疊代器形式,這隻是一個文法糖。<code>class</code>檔案如下:
需要注意的一點是,疊代周遊的時候,如果删除或者添加元素,都會抛出修改異常,這是由于快速失敗<code>【fast-fail】</code>機制,屬于一種自我保護的機制。
從下面的錯誤我們可以看出,第一個元素是有被列印出來的,也就是remove操作是成功的,隻是周遊到第二個元素的時候,疊代器檢查,發現被改變了,是以抛出了異常。
其實就是把對每一個元素的操作當成了一個對象傳遞進來,對每一個元素進行處理。
同時,我們隻要實作<code>Consumer</code>接口,就可以自定義動作,如果不自定義,預設疊代順序是按照元素的順序。
輸出的結果:
這是一個為了并行周遊資料元素而設計的疊代方法,傳回的是<code>Spliterator</code>,是專門并行周遊的疊代器。以發揮多核時代的處理器性能,java預設在集合架構中提供了一個預設的<code>Spliterator</code>實作,底層也就是<code>Stream.isParallel()</code>實作的,我們可以看一下源碼:
使用的方法如下:
<code>tryAdvance()</code> 一個一個元素進行周遊
<code>forEachRemaining()</code> 順序地分塊周遊
<code>trySplit()</code>進行分區形成另外的 <code>Spliterator</code>,使用在并行操作中,分出來的是前面一半,就是不斷把前面一部分分出來
結果如下:
還有一些其他的用法在這裡就不列舉了,主要是<code>trySplit()</code>之後,可以用于多線程周遊。理想的時候,可以平均分成兩半,有利于并行計算,但是不是一定平分的。
<code>Collection</code>接口可以算是集合類的一個根接口之一,一般不能夠直接使用,隻是定義了一個規範,定義了添加,删除等管理資料的方法。繼承<code>Collection</code>接口的有<code>List</code>,<code>Set</code>,<code>Queue</code>,不過<code>Queue</code>定義了自己的一些接口,相對來說和其他的差異比較大。
裡面擷取并行流的方法<code>parallelStream()</code>,其實就是通過預設的<code>ForkJoinPool</code>(主要用來使用分治法(Divide-and-Conquer Algorithm)來解決問題),提高多線程任務的速度。我們可以使用ArrayList來示範一下平行處理能力。例如下面的例子,輸出的順序就不一定是1,2,3...,可能是亂序的,這是因為任務會被分成多個小任務,任務執行是沒有特定的順序的。
graph LR;
Collection -->List-有順序,可重複
List-有順序,可重複 -->LinkedList-使用連結清單實作,線程不安全
List-有順序,可重複 -->ArrayList-數組實作,線程不安全
List-有順序,可重複 -->Vector-數組實作,線程安全
Vector-數組實作,線程安全 -->Stack-堆棧,先進後出
Collection-->Set-不可重複,内部排序
Set-不可重複,内部排序-->HashSet-hash表存儲
HashSet-hash表存儲-->LinkHashSet-連結清單維護插入順序
Set-不可重複,内部排序-->TreeSet-二叉樹實作,排序
Collection-->Queue-隊列,先進先出
繼承于<code>Collection</code>接口,有順序,取出的順序與存入的順序一緻,有索引,可以根據索引擷取資料,允許存儲重複的元素,可以放入為null的元素。
最常見的三個實作類就是<code>ArrayList</code>,<code>Vector</code>,<code>LinkedList</code>,<code>ArrayList</code>和<code>Vector</code>都是内部封裝了對數組的操作,唯一不同的是,<code>Vector</code>是線程安全的,而<code>ArrayList</code>不是,理論上<code>ArrayList</code>操作的效率會比<code>Vector</code>好一些。
裡面是接口定義的方法:
上面的方法都比較簡單,值得一提的是裡面出現了<code>ListIterator</code>,這是一個功能更加強大的疊代器,繼承于<code>Iterator</code>,隻能用于<code>List</code>類型的通路,拓展功能例如:通過調用<code>listIterator()</code>方法獲得一個指向List開頭的<code>ListIterator</code>,也可以調用<code>listIterator(n)</code>擷取一個指定索引為n的元素的<code>ListIterator</code>,這是一個可以雙向移動的疊代器。
操作數組索引的時候需要注意,由于List的實作類底層很多都是數組,是以索引越界會報錯<code>IndexOutOfBoundsException</code>。
說起List的實作子類:
<code>ArrayList</code>:底層存儲結構是數組結構,增加删除比較慢,查找比較快,是最常用的List集合。線程不安全。
<code>LinkedList</code>:底層是連結清單結構,增加删除比較快,但是查找比較慢。線程不安全。
<code>Vector</code>:和ArrayList差不多,但是是線程安全的,即同步。
<code>Set</code>接口,不允許放入重複的元素,也就是如果相同,則隻存儲其中一個。
下面是源碼方法:
主要的子類:
<code>HashSet</code>
允許空值
通過<code>HashCode</code>方法計算擷取<code>hash</code>值,确定存儲位置,無序。
<code>LinkedHashSet</code>
<code>HashSet</code>的子類
有順序
<code>TreeSet</code>
如果無參數建構<code>Set</code>,則需要實作<code>Comparable</code>方法。
亦可以建立時傳入比較方法,用于排序。
隊列接口,在<code>Collection</code>接口的接觸上添加了增删改查接口定義,一般預設是先進先出,即<code>FIFO</code>,除了優先隊列和棧,優先隊列是自己定義了排序的優先順序,隊列中不允許放入null元素。
下面是源碼:
主要的子接口以及實作類有:
Deque(接口):Queue的子接口,雙向隊列,可以從兩邊存取
ArrayDeque:Deque的實作類,底層用數組實作,資料存貯在數組中
AbstractQueue:Queue的子接口,僅實作了add、remove和element三個方法
PriorityQueue:按照預設或者自己定義的順序來排序元素,底層使用堆(完全二叉樹)實作,使用動态數組實作,
BlockingQueue: 在java.util.concurrent包中,阻塞隊列,滿足目前無法處理的操作。
定義雙列集合的規範<code>Map<K,V></code>,每次存儲一對元素,即<code>key</code>和<code>value</code>。
<code>key</code>的類型可以和<code>value</code>的類型相同,也可以不同,任意的引用類型都可以。
<code>key</code>是不允許重複的,但是<code>value</code>是可以重複的,所謂重複是指計算的<code>hash</code>值。
下面的源碼的方法:
值得注意的是,Map裡面定義了一個Entry類,其實就是定義了一個存儲資料的類型,一個entry就是一個<code><key,value></code>.
Map的常用的實作子類:
<code>HashMap</code>:由數組和連結清單組成,線程不安全,無序。
<code>LinkedHashMap</code>:如果我們需要是有序的,那麼就需要它,時間和空間效率沒有<code>HashMap</code>那麼高,底層是維護一條雙向連結清單,保證了插入的順序。
<code>ConcurrentHashMap</code>:線程安全,1.7JDK使用鎖分離,每一段Segment都有自己的獨立鎖,相對來說效率也比較高。JDK1.8抛棄了Segment,使用Node數組+連結清單和紅黑樹實作,線上程安全控制上使用<code>Synchronize</code>和<code>CAS</code>,可以認為是優化的線程安全的<code>HashMap</code>。
<code>HashTable</code>:對比與<code>HashMap</code>主要是使用關鍵字<code>synchronize</code>,加上同步鎖,線程安全。
這些集合原始接口到底是什麼?為什麼需要?
我想,這些接口其實都是一種規則/規範的定義,如果不這麼做也可以,所有的子類自己實作,但是從疊代以及維護的角度來說,這就是一種抽象或者分類,比如定義了<code>Iterator</code>接口,某一些類就可以去繼承或者實作,那就得遵守這個規範/契約。可以有所拓展,每個子類的拓展不一樣,是以每個類就各有所長,但是都有一個中心,就是原始的集合接口。比如實作<code>Map</code>接口的所有類的中心思想都不變,都是<code><key,value></code>隻是各有所長,各分千秋,形成了大千集合世界。
此文章僅代表自己(本菜鳥)學習積累記錄,或者學習筆記,如有侵權,請聯系作者删除。人無完人,文章也一樣,文筆稚嫩,在下不才,勿噴,如果有錯誤之處,還望指出,感激不盡~
技術之路不在一時,山高水長,縱使緩慢,馳而不息。
公衆号:秦懷雜貨店