对于这个模块打算有几篇文章组成一个系列,详细的介绍这个功能,大概分read replicas综述(本文)、正常情况下的读写流程分析、异常情况下的读写流程分析;
本文主要介绍的有:概述、读流程链路、写流程链路、如何使用read replicas,example。我们知道HBase是一个强一致的系统,最初是因为一个regionserver下负责的多个region的读写都是经历这个regionserver去做处理,这样的话,该regionserver是单点的做读写,不会存在数据不一致的问题。但是相应的该regionserver如果挂掉了,会造成该regionserver负责的region都不能提供服务。这个降低了整个流程的服务可用性。那么为了解决该问题,HBase引入了 Read Replicas的功能,也就是对于一个region在多个节点上都有对应的副本,HBase可以通过balance保证各个region的各个副本在不同的机器,机架上。我们给主region 一个数字为0的replica_id,其余的副本都可以叫做secondary regions,他们的对应replica_id 是1、2、…,所有的写请求都是replica_id为0的节点(regionserver)做处理,然后异步的发送到1、2、…等节点。有了这个功能HBase的读流程的可用性就由原来的3个9变成了4个9。当然有利也有弊,我们做设计就是在做tradeoff,引入这个功能的话,对系统读取数据的一致性有一点影响。不过这个主要看业务方可否接受,为了提高服务可用性,牺牲一点点数据一致性是否可以考虑。
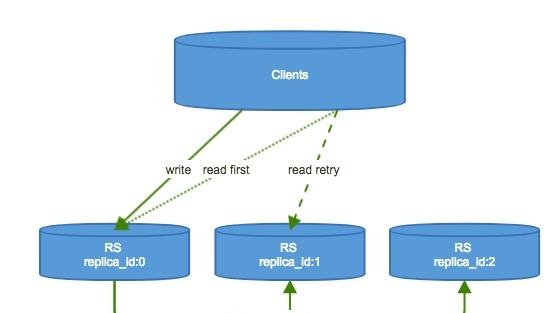
在HBase进行Get的时候,构造的Get对象里面有一个Consistency的子项,默认是Consistency.STRONG,除此之外还有一个Consistency.TIMELINE的选项。我们文章涉及到的replicas主要和这个东西有关系。如果你希望让你的读操作具有更高的可用性,你就需要在Get对象进行一个设置,设置它的Consistency属性为TIMELINE。那么通过这个设置的话,读请求就先会去replica_id为0的主replica上面去读数据,如果在一定时间内,HBase client没有等到主的响应,那么就会并发的发送请求到备份的replicas,这个时间默认是10ms,可以通过在client端的配置文件里面设置hbase.client.primaryCallTimeout.get来配置。那么你可能就会问了,这个数据可能不是主上面的数据,可能是replica_id为1、2、等上面的数据,那么这个数据不就存在老数据的可能么?对!HBase 提供了一个接口用于判别数据是不是最新的,叫做isStale()。
但是如果用户使用的是Consistency.STRONG这种的话,就不会存在读到老数据的可能性。世上很难有完美的方案,那么怎么去做选择,就是需要业务基于自己的需求做一定的选择了。这个方案的有点是:提高了读服务的可用性,同样的会引入一些弊端,造成一定的内存开销以及网络开销,因为数据需要在replicas上进行存储,也存在请求到replicas上的可能性,那么就会增加网络开销;
上面概述里面提到我们需要把HBase的写的数据先经replica_id为0 的节点,然后异步分发到replicas上面去,那么分发的过程是异步的,不然存在影响整个写流程的体验。既然设计的是异步的,在HBase 里面存在2阶段不同的实现方案,分别是在HBase1.0+和HBase1.1+这2个大版本上面实现的;在HBase的官方分别叫做: StoreFile Refresher 和 Asnyc WAL replication。
3.1.StoreFile Refresher
这种机制就是一个regionserver上一个特定的线程,阶段性的将主replica上的store file 刷新到secondary replicas上面。开启这个功能的配置是在HBase的里面把hbase.regionserver.storefile.refresh.period进行一个配置,单位是毫秒级别的。通过设置这个,定时刷新线程会看到主上的memstore 的flush,以及compaction,bulck load 操作。那么对于内存里面的数据,可能就会在备份上面读不到。
3.2.Asnyc WAL replication
在HBase1.1+的版本里面新的一种数据被复制到secondary replicas的方式是:类似HBase replication,但是是单集群内部replicas之间的数据复制,由于主和secondary replicas之间的数据共享一份持久化数据,那么数据备份到replicas的时候是需要保证内存之间的数据是相同的。主在做写,compaction,bulkload等操作的时候会写数据到wal log,然后通过这个机制secondary replicas会观察到变化,然后讲数据在本地内存回放。
这个功能默认情况下是被关闭的,通过设置“hbase.region.replica.replication.enabled” 为true即可开启这个功能。
如果要使用功能的话,分服务端和客户端,下面这份配置是服务端的:
客户端上面的配置更新:
新建一张具有region replica 的表:shell命令:
java的api操作:
读取数据:shell命令:
后面的话会继续从源码级别进行该模块的分析,敬请期待!
如果大家有兴趣可以扫码加入钉钉群探讨HBase 以及大数据存储计算技术:

<a href="https://hbase.apache.org/book.html">https://hbase.apache.org/book.html</a>
<a href="https://github.com/apache/hbase/blob/master/src/main/asciidoc/_chapters/architecture.adoc#10-timeline-consistent-high-available-reads">https://github.com/apache/hbase/blob/master/src/main/asciidoc/_chapters/architecture.adoc#10-timeline-consistent-high-available-reads</a>