對于這個子產品打算有幾篇文章組成一個系列,詳細的介紹這個功能,大概分read replicas綜述(本文)、正常情況下的讀寫流程分析、異常情況下的讀寫流程分析;
本文主要介紹的有:概述、讀流程鍊路、寫流程鍊路、如何使用read replicas,example。我們知道HBase是一個強一緻的系統,最初是因為一個regionserver下負責的多個region的讀寫都是經曆這個regionserver去做處理,這樣的話,該regionserver是單點的做讀寫,不會存在資料不一緻的問題。但是相應的該regionserver如果挂掉了,會造成該regionserver負責的region都不能提供服務。這個降低了整個流程的服務可用性。那麼為了解決該問題,HBase引入了 Read Replicas的功能,也就是對于一個region在多個節點上都有對應的副本,HBase可以通過balance保證各個region的各個副本在不同的機器,機架上。我們給主region 一個數字為0的replica_id,其餘的副本都可以叫做secondary regions,他們的對應replica_id 是1、2、…,所有的寫請求都是replica_id為0的節點(regionserver)做處理,然後異步的發送到1、2、…等節點。有了這個功能HBase的讀流程的可用性就由原來的3個9變成了4個9。當然有利也有弊,我們做設計就是在做tradeoff,引入這個功能的話,對系統讀取資料的一緻性有一點影響。不過這個主要看業務方可否接受,為了提高服務可用性,犧牲一點點資料一緻性是否可以考慮。
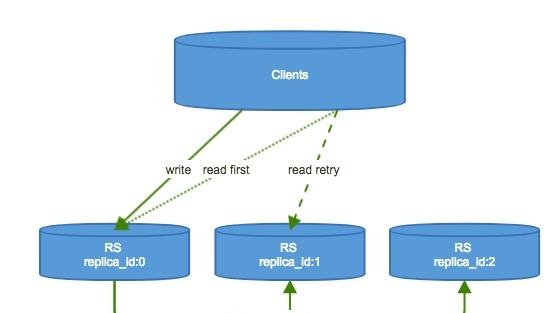
在HBase進行Get的時候,構造的Get對象裡面有一個Consistency的子項,預設是Consistency.STRONG,除此之外還有一個Consistency.TIMELINE的選項。我們文章涉及到的replicas主要和這個東西有關系。如果你希望讓你的讀操作具有更高的可用性,你就需要在Get對象進行一個設定,設定它的Consistency屬性為TIMELINE。那麼通過這個設定的話,讀請求就先會去replica_id為0的主replica上面去讀資料,如果在一定時間内,HBase client沒有等到主的響應,那麼就會并發的發送請求到備份的replicas,這個時間預設是10ms,可以通過在client端的配置檔案裡面設定hbase.client.primaryCallTimeout.get來配置。那麼你可能就會問了,這個資料可能不是主上面的資料,可能是replica_id為1、2、等上面的資料,那麼這個資料不就存在老資料的可能麼?對!HBase 提供了一個接口用于判别資料是不是最新的,叫做isStale()。
但是如果使用者使用的是Consistency.STRONG這種的話,就不會存在讀到老資料的可能性。世上很難有完美的方案,那麼怎麼去做選擇,就是需要業務基于自己的需求做一定的選擇了。這個方案的有點是:提高了讀服務的可用性,同樣的會引入一些弊端,造成一定的記憶體開銷以及網絡開銷,因為資料需要在replicas上進行存儲,也存在請求到replicas上的可能性,那麼就會增加網絡開銷;
上面概述裡面提到我們需要把HBase的寫的資料先經replica_id為0 的節點,然後異步分發到replicas上面去,那麼分發的過程是異步的,不然存在影響整個寫流程的體驗。既然設計的是異步的,在HBase 裡面存在2階段不同的實作方案,分别是在HBase1.0+和HBase1.1+這2個大版本上面實作的;在HBase的官方分别叫做: StoreFile Refresher 和 Asnyc WAL replication。
3.1.StoreFile Refresher
這種機制就是一個regionserver上一個特定的線程,階段性的将主replica上的store file 重新整理到secondary replicas上面。開啟這個功能的配置是在HBase的裡面把hbase.regionserver.storefile.refresh.period進行一個配置,機關是毫秒級别的。通過設定這個,定時重新整理線程會看到主上的memstore 的flush,以及compaction,bulck load 操作。那麼對于記憶體裡面的資料,可能就會在備份上面讀不到。
3.2.Asnyc WAL replication
在HBase1.1+的版本裡面新的一種資料被複制到secondary replicas的方式是:類似HBase replication,但是是單叢集内部replicas之間的資料複制,由于主和secondary replicas之間的資料共享一份持久化資料,那麼資料備份到replicas的時候是需要保證記憶體之間的資料是相同的。主在做寫,compaction,bulkload等操作的時候會寫資料到wal log,然後通過這個機制secondary replicas會觀察到變化,然後講資料在本地記憶體回放。
這個功能預設情況下是被關閉的,通過設定“hbase.region.replica.replication.enabled” 為true即可開啟這個功能。
如果要使用功能的話,分服務端和用戶端,下面這份配置是服務端的:
用戶端上面的配置更新:
建立一張具有region replica 的表:shell指令:
java的api操作:
讀取資料:shell指令:
後面的話會繼續從源碼級别進行該子產品的分析,敬請期待!
如果大家有興趣可以掃碼加入釘釘群探讨HBase 以及大資料存儲計算技術:

<a href="https://hbase.apache.org/book.html">https://hbase.apache.org/book.html</a>
<a href="https://github.com/apache/hbase/blob/master/src/main/asciidoc/_chapters/architecture.adoc#10-timeline-consistent-high-available-reads">https://github.com/apache/hbase/blob/master/src/main/asciidoc/_chapters/architecture.adoc#10-timeline-consistent-high-available-reads</a>