Kafka是最初由Linkedin公司开发,是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统)。
Kafka主要被用于两大类应用:
在应用间构建实时的数据流通道
构建传输或处理数据流的实时流式应用
Kafka有4个核心API:
Producer API:用于应用程序将数据流发送到一个或多个Kafka topics
Consumer API:用于应用程序订阅一个或多个topics并处理被发送到这些topics中的数据
Streams API:允许应用程序作为流处理器,处理来自一个或多个topics的数据并将处理结果发送到一个或多个topics中,有效的将输入流转化为输出流
Connector API:用于构建和运行将Kafka topics和现有应用或数据系统连接的可重用的produers和consumers。例如,如链接到关系数据库的连接器可能会捕获某个表所有的变更
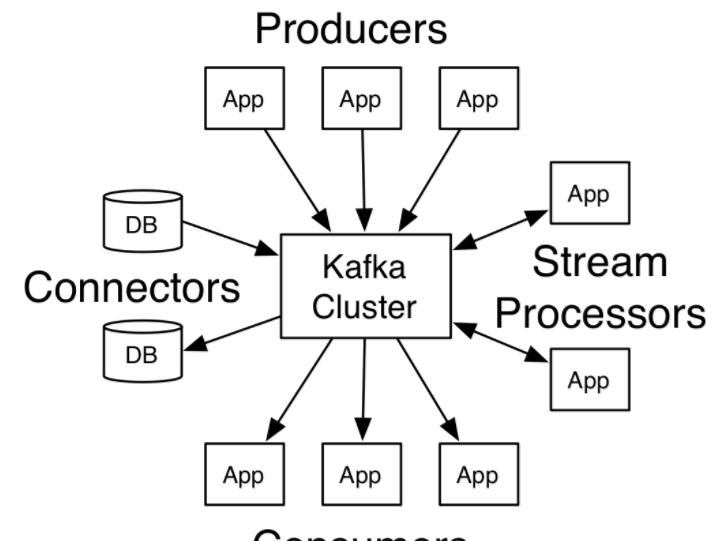
kafka几个重要概念:
Topic
Topic是发布记录的类别。Kafka中的Topics一般是多订阅者的,也就是一个Topic可以有0个或多个Consumer订阅它的数据。
Distribution
分区日志分布在集群中服务器中,每个服务器处理一部分分区的数据和请求。每个分区可以配置分布的服务器,以实现容错。
每个分区拥有一个Leader节点,和零或多个Follower。Leader处理该分区所有的读写请求,Follower复制Leader数据。如果Leader节点宕机,将会有一个Follower节点自动的转化为Leader。每个节点成为其部分分区的Leader,并成为剩余分区的Follower,这样整个集群的负载将比较均衡。
Producers
Producer发送数据到它选择的Topic。Producer负责决定将数据发送到Topic的那个分区上。这可以通过简单的循环方式来平衡负载,或则可以根据某些语义来决定分区(例如基于数据中一些关键字)。
Consumers
Consumer使用一个group name来标识自己的身份,每条被发送到一个Topic的消息都将被分发到属于同一个group的Consumer的一个实例中(group name相同的Consumer属于一个组,一个Topic的一条消息会被这个组中的一个Consumer实例消费)。Consumer实例可以在单独的进程中或者单独的机器上。
部署环境
常用部署机型:A5或 TS80
操作系统版本: Tencent tlinux release 2.2
ava 版本: 1.7.0_80
Zookeeper 版本: zookeeper-3.4.6
Kafka 版本:kafka_2.11-0.9.0.1
部署步骤
分别解压zookeeper-3.4.6.tar.gz和kafka_2.11-0.9.0.1.tgz
修改配置文件,设置相关参数后,分别启动zookeeper和kafka:
常用命令
创建topic:
列出所有topic:
查看topic信息(包括分区、副本情况等):
往某topic生产消息:
从某topic消费消息:
通过keeper监控kafka和zk
zookeeper集群的容错能力的算法为:2n+1=总数,n即为可容纳的故障节点
即:3台能容错1台,5台能容错2台,7台能容错3台
新搭的一个Kafka集群只有3台zookeeper节点,为了增加容错能力,决定扩容
先在新节点上安装zookeeper软件,修改myid和zoo.cfg
修改整个集群中与Zookeeper相关的系统配置:
重启Zookeeper服务
所有节点依次重启kafka服务
存储时间设置太长会导致磁盘空间不够,修改topic存储时间24小时
不需要重启,修改集群默认设置才要重启
原有kafka集群都是使用A5机型,该机型只有一块大磁盘,所以Kafka集群只需配置一个数据目录,把数据存储在该磁盘上,最近的上海端游kafka集群也是按此模板搭建的。但是新集群是TS80机型,提供了4块1.8T的磁盘,随着接入的数据增多,发现一个磁盘快撑满了,另外三块却空着,为了充分利用多个磁盘,需要在原来基础上增加数据目录
重启kafka集群:
重启后可以看到新加的磁盘(目录)下已经产生了初始化文件,说明新目录已添加成功,以后集群新建topic时会优先把partition存到空闲率高的目录下。但是已有的数据不会自动rebalance,需要人为的去reassign-partitions,步骤如下:
先看下现有topic的分布情况,可以看到dnf_log_dnf的分区现在都在/data1
1.现在开始reassign-partitions,先手动生成一个json文件topic.json
2.调用--generate生成迁移计划,使用kafka的kafka-reassign-partitions.sh工具来分配topic的分区位置
上面的json即为新的分区分布,把它复制到reassignment.json
3.执行—execute执行迁移
4.使用--verify查看进度
附扩容时同步状态:

经过两次reassign后,可以看到partion已经均匀分布到四块磁盘上了
再看下topic的分布情况,从命令输出结果可以看到topic dnf_log_dnf有6个partition,分布在0,1,2三个broker上,数据有俩个副本。
1. 启动新节点
将原节点上的 kafka 目录通过 scp 命令拷贝到新节点,只需要修改配置文件中的 broker_id 和 ip 地址,然后依次启动 kafka 服务。
2.Rebalance数据存储
同样集群扩容后数据是不会自动均衡到新机器上的,需要采用kafka-reassign-partitions.sh这个工具脚本。脚本可以工作在三种模式--generate,--execute,--verify,详细步骤可参考第七节:增加数据目录
1.不同的机型(A5,TS80)磁盘情况不一样,灵活配置数据存储目录 log.dirs,使磁盘利用最大化。
2.集群健康状态监控,检查集群replicas同步情况,有异常发出告警:
3.kafka自带性能测试工具:
4.开源管理及监控工具:kafka manager:
KafkaOffsetMonitor: