Kafka是最初由Linkedin公司開發,是一個分布式、分區的、多副本的、多訂閱者,基于zookeeper協調的分布式日志系統(也可以當做MQ系統)。
Kafka主要被用于兩大類應用:
在應用間建構實時的資料流通道
建構傳輸或處理資料流的實時流式應用
Kafka有4個核心API:
Producer API:用于應用程式将資料流發送到一個或多個Kafka topics
Consumer API:用于應用程式訂閱一個或多個topics并處理被發送到這些topics中的資料
Streams API:允許應用程式作為流處理器,處理來自一個或多個topics的資料并将處理結果發送到一個或多個topics中,有效的将輸入流轉化為輸出流
Connector API:用于建構和運作将Kafka topics和現有應用或資料系統連接配接的可重用的produers和consumers。例如,如連結到關系資料庫的連接配接器可能會捕獲某個表所有的變更
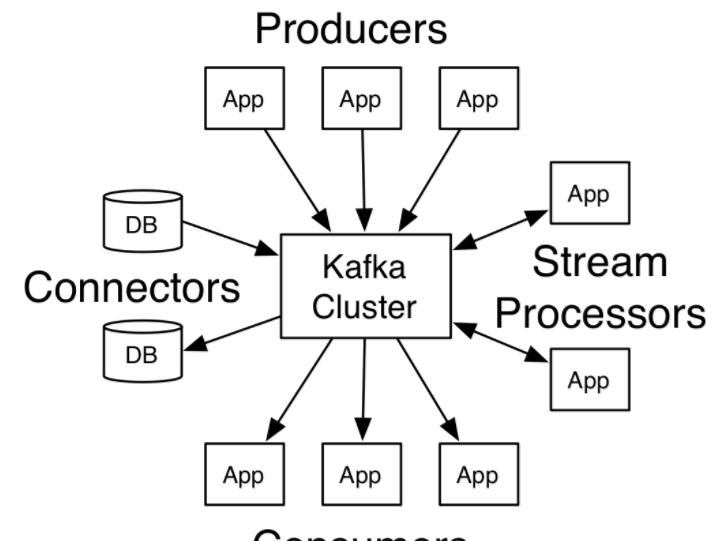
kafka幾個重要概念:
Topic
Topic是釋出記錄的類别。Kafka中的Topics一般是多訂閱者的,也就是一個Topic可以有0個或多個Consumer訂閱它的資料。
Distribution
分區日志分布在叢集中伺服器中,每個伺服器處理一部分分區的資料和請求。每個分區可以配置分布的伺服器,以實作容錯。
每個分區擁有一個Leader節點,和零或多個Follower。Leader處理該分區所有的讀寫請求,Follower複制Leader資料。如果Leader節點當機,将會有一個Follower節點自動的轉化為Leader。每個節點成為其部分分區的Leader,并成為剩餘分區的Follower,這樣整個叢集的負載将比較均衡。
Producers
Producer發送資料到它選擇的Topic。Producer負責決定将資料發送到Topic的那個分區上。這可以通過簡單的循環方式來平衡負載,或則可以根據某些語義來決定分區(例如基于資料中一些關鍵字)。
Consumers
Consumer使用一個group name來辨別自己的身份,每條被發送到一個Topic的消息都将被分發到屬于同一個group的Consumer的一個執行個體中(group name相同的Consumer屬于一個組,一個Topic的一條消息會被這個組中的一個Consumer執行個體消費)。Consumer執行個體可以在單獨的程序中或者單獨的機器上。
部署環境
常用部署機型:A5或 TS80
作業系統版本: Tencent tlinux release 2.2
ava 版本: 1.7.0_80
Zookeeper 版本: zookeeper-3.4.6
Kafka 版本:kafka_2.11-0.9.0.1
部署步驟
分别解壓zookeeper-3.4.6.tar.gz和kafka_2.11-0.9.0.1.tgz
修改配置檔案,設定相關參數後,分别啟動zookeeper和kafka:
常用指令
建立topic:
列出所有topic:
檢視topic資訊(包括分區、副本情況等):
往某topic生産消息:
從某topic消費消息:
通過keeper監控kafka和zk
zookeeper叢集的容錯能力的算法為:2n+1=總數,n即為可容納的故障節點
即:3台能容錯1台,5台能容錯2台,7台能容錯3台
新搭的一個Kafka叢集隻有3台zookeeper節點,為了增加容錯能力,決定擴容
先在新節點上安裝zookeeper軟體,修改myid和zoo.cfg
修改整個叢集中與Zookeeper相關的系統配置:
重新開機Zookeeper服務
所有節點依次重新開機kafka服務
存儲時間設定太長會導緻磁盤空間不夠,修改topic存儲時間24小時
不需要重新開機,修改叢集預設設定才要重新開機
原有kafka叢集都是使用A5機型,該機型隻有一塊大磁盤,是以Kafka叢集隻需配置一個資料目錄,把資料存儲在該磁盤上,最近的上海端遊kafka叢集也是按此模闆搭建的。但是新叢集是TS80機型,提供了4塊1.8T的磁盤,随着接入的資料增多,發現一個磁盤快撐滿了,另外三塊卻空着,為了充分利用多個磁盤,需要在原來基礎上增加資料目錄
重新開機kafka叢集:
重新開機後可以看到新加的磁盤(目錄)下已經産生了初始化檔案,說明新目錄已添加成功,以後叢集建立topic時會優先把partition存到空閑率高的目錄下。但是已有的資料不會自動rebalance,需要人為的去reassign-partitions,步驟如下:
先看下現有topic的分布情況,可以看到dnf_log_dnf的分區現在都在/data1
1.現在開始reassign-partitions,先手動生成一個json檔案topic.json
2.調用--generate生成遷移計劃,使用kafka的kafka-reassign-partitions.sh工具來配置設定topic的分區位置
上面的json即為新的分區分布,把它複制到reassignment.json
3.執行—execute執行遷移
4.使用--verify檢視進度
附擴容時同步狀态:

經過兩次reassign後,可以看到partion已經均勻分布到四塊磁盤上了
再看下topic的分布情況,從指令輸出結果可以看到topic dnf_log_dnf有6個partition,分布在0,1,2三個broker上,資料有倆個副本。
1. 啟動新節點
将原節點上的 kafka 目錄通過 scp 指令拷貝到新節點,隻需要修改配置檔案中的 broker_id 和 ip 位址,然後依次啟動 kafka 服務。
2.Rebalance資料存儲
同樣叢集擴容後資料是不會自動均衡到新機器上的,需要采用kafka-reassign-partitions.sh這個工具腳本。腳本可以工作在三種模式--generate,--execute,--verify,詳細步驟可參考第七節:增加資料目錄
1.不同的機型(A5,TS80)磁盤情況不一樣,靈活配置資料存儲目錄 log.dirs,使磁盤利用最大化。
2.叢集健康狀态監控,檢查叢集replicas同步情況,有異常發出告警:
3.kafka自帶性能測試工具:
4.開源管理及監控工具:kafka manager:
KafkaOffsetMonitor: