线上运行的生产系统会定时采集一项丢包数据,这项数据与某个进程相关联,从进程启动开始就一直递增,每隔1分钟采集一次数据,当进程重启之后,这项数据会清零。现在要求使用PIG来统计某个时间段(1 hour)内,多个进程此项数据的变化量汇总。可以看到数据形如以下形式。进程会通过GrpID分组,每个组内有多个进程,需要计算的是各组VALUE值的总的变化量。总数据量约为12w。
粗看起来这个问题似乎很简单,因为数据量并不是很大,可以首先LOAD整个数据集,然后按照PID分组,在分组内对TIMESTAMP时间排序,计算最后一个与第一个VALUE的差值,然后再对GrpID分组将刚才计算出来的差值求和即可。仔细想想这是不行的,因为在每个PID分组内,本次时间片内的数据有可能因为进程重启而清零(如下图),所以不能简单的按照时间排序后尾首相减来计算。
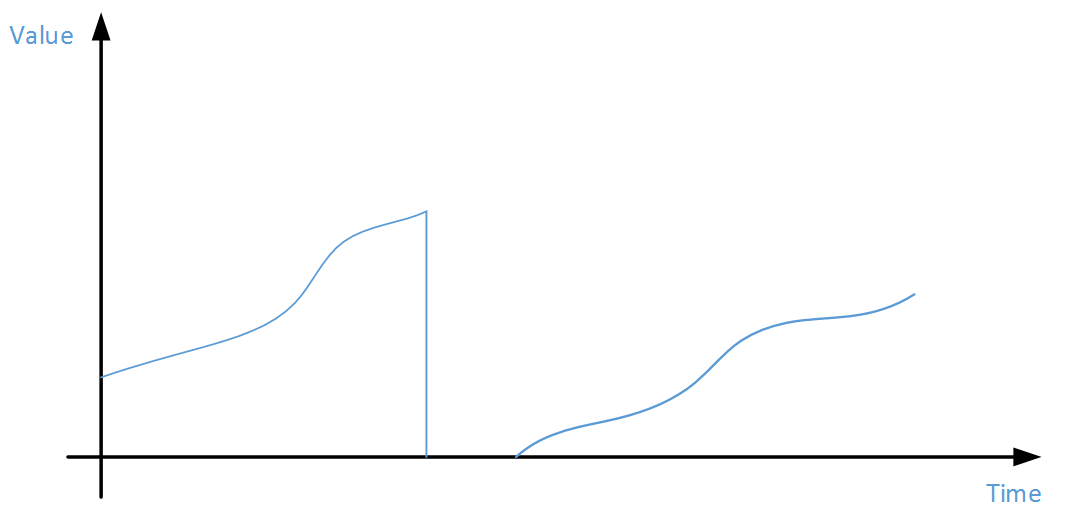
这种累积型数据的计算方式应该如下图,计算多个分段分别的diff值,最后汇总。

具体的算法也非常简单:
对数据集按照PID聚合
对于每个聚合子集,按照TIMESTAMP进行ASC排序
对于排序过后的VALUE序列 V1, V_2, V_3 …… ,V(n-1), V_n 计算:
从最后一个VALUE开始,计算Vt – V(t-1) 的值并求和,当遇到差值为负的情况,也就是出现了进程重启清零的情况,就加零。
对GrpID聚合,求出一个分组下所有进程SUM_Diff的求和值。
上述算法很简单,用脚本可以很快搞定。但如果需要用PIG任务来写,第3个步骤就没有这么容易实现了。不过好在PIG脚本可以调用其他语言编写的UDF(User Define Function)来完成某些复杂的计算逻辑,我们就采用此种方案。如何使用Jython实现PIG UDF请参考官方文档
https://pig.apache.org/docs/r0.9.1/udf.html
先来看PIG脚本代码:
我们选用Jython来实现UDF,主要是实现第3步的逻辑,Python代码如下: