線上運作的生産系統會定時采集一項丢包資料,這項資料與某個程序相關聯,從程序啟動開始就一直遞增,每隔1分鐘采集一次資料,當程序重新開機之後,這項資料會清零。現在要求使用PIG來統計某個時間段(1 hour)内,多個程序此項資料的變化量彙總。可以看到資料形如以下形式。程序會通過GrpID分組,每個組内有多個程序,需要計算的是各組VALUE值的總的變化量。總資料量約為12w。
粗看起來這個問題似乎很簡單,因為資料量并不是很大,可以首先LOAD整個資料集,然後按照PID分組,在分組内對TIMESTAMP時間排序,計算最後一個與第一個VALUE的內插補點,然後再對GrpID分組将剛才計算出來的內插補點求和即可。仔細想想這是不行的,因為在每個PID分組内,本次時間片内的資料有可能因為程序重新開機而清零(如下圖),是以不能簡單的按照時間排序後尾首相減來計算。
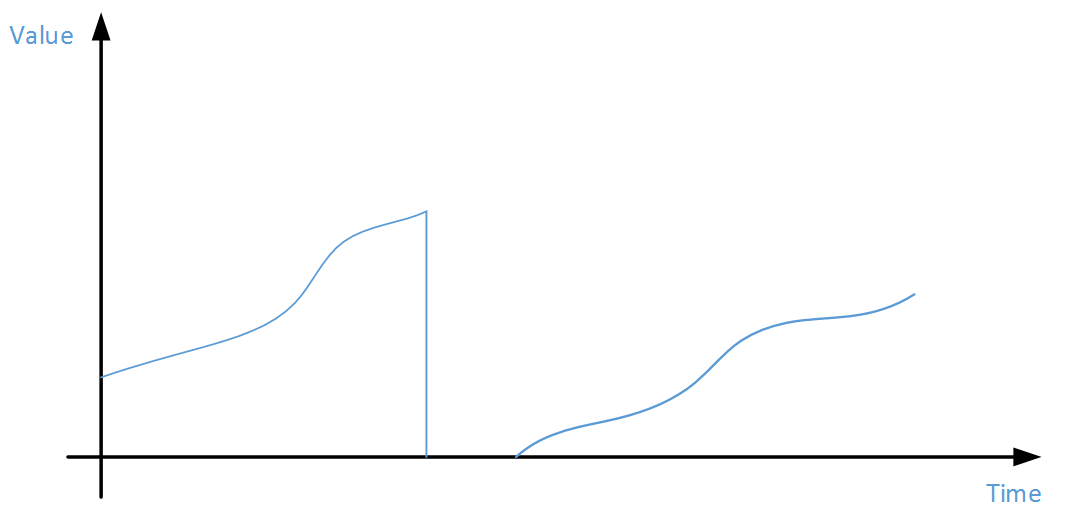
這種累積型資料的計算方式應該如下圖,計算多個分段分别的diff值,最後彙總。

具體的算法也非常簡單:
對資料集按照PID聚合
對于每個聚合子集,按照TIMESTAMP進行ASC排序
對于排序過後的VALUE序列 V1, V_2, V_3 …… ,V(n-1), V_n 計算:
從最後一個VALUE開始,計算Vt – V(t-1) 的值并求和,當遇到內插補點為負的情況,也就是出現了程序重新開機清零的情況,就加零。
對GrpID聚合,求出一個分組下所有程序SUM_Diff的求和值。
上述算法很簡單,用腳本可以很快搞定。但如果需要用PIG任務來寫,第3個步驟就沒有這麼容易實作了。不過好在PIG腳本可以調用其他語言編寫的UDF(User Define Function)來完成某些複雜的計算邏輯,我們就采用此種方案。如何使用Jython實作PIG UDF請參考官方文檔
https://pig.apache.org/docs/r0.9.1/udf.html
先來看PIG腳本代碼:
我們選用Jython來實作UDF,主要是實作第3步的邏輯,Python代碼如下: