上文我们看到了AutogradMetadata,DistAutogradContainer 和 DistAutogradContext 等一系列基础类。我们知道了分布式autograd如何基于RPC进行传递,如何在节点之间交互,节点如何区分维护这些Session。本文继续分析,主要目的是看看反向传播如何切入到引擎之中。
目录
[源码解析] PyTorch 分布式 Autograd (4) ---- 如何切入引擎
0x00 摘要
0x01 前文回忆
0x02 计算图
2.1 普通示例
2.2 分布式示例
2.3 分布式注释版
0x03 反向传播
3.1 发起反向传播
3.1.1 外部主动发起
3.1.1.1 示例
3.1.1.2 C++世界
3.1.2 内部隐式发起
3.1.2.1 BACKWARD_AUTOGRAD_REQ
3.1.2.2 PropagateGradientsReq
3.2 接受反向传播
3.2.1 接受消息
3.2.2 处理消息
3.3 总结
0xFF 参考
PyTorch分布式其他文章如下:
深度学习利器之自动微分(1)
深度学习利器之自动微分(2)
[源码解析]深度学习利器之自动微分(3) --- 示例解读
[源码解析]PyTorch如何实现前向传播(1) --- 基础类(上)
[源码解析]PyTorch如何实现前向传播(2) --- 基础类(下)
[源码解析] PyTorch如何实现前向传播(3) --- 具体实现
[源码解析] Pytorch 如何实现后向传播 (1)---- 调用引擎
[源码解析] Pytorch 如何实现后向传播 (2)---- 引擎静态结构
[源码解析] Pytorch 如何实现后向传播 (3)---- 引擎动态逻辑
[源码解析] PyTorch 如何实现后向传播 (4)---- 具体算法
[源码解析] PyTorch 分布式(1)------历史和概述
[源码解析] PyTorch 分布式(2) ----- DataParallel(上)
[源码解析] PyTorch 分布式(3) ----- DataParallel(下)
[源码解析] PyTorch 分布式(4)------分布式应用基础概念
[源码解析] PyTorch分布式(5) ------ DistributedDataParallel 总述&如何使用
[源码解析] PyTorch分布式(6) ---DistributedDataParallel -- 初始化&store
[源码解析] PyTorch 分布式(7) ----- DistributedDataParallel 之进程组
[源码解析] PyTorch 分布式(8) -------- DistributedDataParallel之论文篇
[源码解析] PyTorch 分布式(9) ----- DistributedDataParallel 之初始化
[源码解析] PyTorch 分布式(10)------DistributedDataParallel 之 Reducer静态架构
[源码解析] PyTorch 分布式(11) ----- DistributedDataParallel 之 构建Reducer和Join操作
[源码解析] PyTorch 分布式(12) ----- DistributedDataParallel 之 前向传播
[源码解析] PyTorch 分布式(13) ----- DistributedDataParallel 之 反向传播
[源码解析] PyTorch 分布式 Autograd (1) ---- 设计
[源码解析] PyTorch 分布式 Autograd (2) ---- RPC基础
[源码解析] PyTorch 分布式 Autograd (3) ---- 上下文相关
为了更好的说明,本文代码会依据具体情况来进行相应精简。
我们回忆一下前面几篇文章的内容。
首先,对于分布式 autograd,我们需要在前向传播期间跟踪所有 RPC,以确保正确执行后向传播。为此,当执行 RPC 时候,我们把 <code>send</code>和<code>recv</code> functions 附加到autograd图之上。
该<code>send</code>函数附加到 RPC 的发起源节点之上,其输出边指向 RPC 输入张量的 autograd 函数。在向后传播期间,<code>send</code>函数的输入是从目标接收的,是对应<code>recv</code>函数的输出。
该<code>recv</code>函数附加到 RPC 的接受目标节点之上,其输入从某些运算符得到,这些运算符使用输入张量在RPC接受目标上执行。在后向传播期间,<code>recv</code>函数的输出梯度将被发送到源节点之上,并且作为<code>send</code>方法的输入。
每<code>send-recv</code>对被分配一个全局唯一的<code>autograd_message_id</code> 以唯一地标识该<code>send-recv</code>对。这对于在向后传播期间查找远程节点上的相应函数很有用。
对于RRef,每当我们调用<code>torch.distributed.rpc.RRef.to_here()</code> 时,我们都为涉及的张量添加了一个适当的<code>send-recv</code>对。
其次,在前向传播的具体代码之中,我们在上下文中存储每个 autograd 传播的<code>send</code>和<code>recv</code>函数。这确保我们在 autograd 图中保存对适当节点的引用以使其保持活动状态。除此之外,这也使得在向后传播期间很容易查找到对应的<code>send</code>和<code>recv</code>函数。
再次,以下是 torch/csrc/distributed/rpc/message.h 之中的部分消息定义:
在前文,我们看到了 FORWARD_AUTOGRAD_REQ 在前向传播之中如何调用,假设如下代码:rpc.rpc_sync("worker1", torch.add, args=(t1, t2)),其调用序列是:
rpc_sync 调用 _invoke_rpc。
_invoke_rpc 调用 _invoke_rpc_builtin。
然后调用到 pyRpcBuiltin,继而调用到 sendMessageWithAutograd。
sendMessageWithAutograd 内部会构建 FORWARD_AUTOGRAD_REQ消息,最后使用RPC 发送。
至此,关于整体流程,我们就有了几个疑问:
在反向计算图的起始位置,如何发起反向传播,怎么传递给反向传播的下一个环节?
在反向传播的内部环节,BACKWARD_AUTOGRAD_REQ 是何时调用?recv 操作是何时被调用? 在上下文中,recvAutogradFunctions_ 是在哪里设置的?
以上两个环节分别如何进入分布式autograd引擎?
我们接下来就围绕这些疑问进行分析,核心就是如何进入 dist.autograd 引擎。
我们首先从计算图来通过几个示例来看看。
首先看看普通计算,这个是 dist.auto 官方图例的本地版本。可以看到是由 AddBackward0,AccumulateGrad 和 MulBackward0 等组成了计算图。
具体对应如下图:
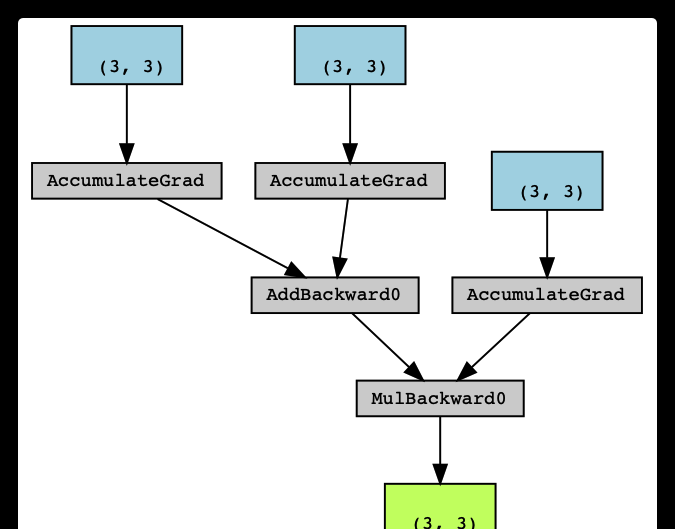
接下来看看分布式的例子,这个例子就是官方设计中图例大致对应的代码,我们把 torch.mul(t3, t4) 命名为 t5,加入了 loss。
在分布式之下,t3 是异地运行。
t5 对应的是 mul,t5.grad_fn 是 <MulBackward0 object at 0x7fbf18d297b8>。
t3.grad_fn 是 <CppFunction object at 0x7fbf18d11a20>,就是说,recv 对应的就是 CppFunction 。
loss 是 tensor(5.5680, grad_fn=)。
其余的都是 None。
我们把设计图例再展示出来,上面示例代码就是下图的左侧 worker 0,t3 实际就是运行在 worker 1,大家可以看到分布式上下文中的一些特点。

为了更好的说明,我们打印了一些log作为注释。
打印结果是:
加上分布式相关算子之后,图例如下:
我们接下来要看看如何进入dist autograd 引擎,结合我们图例,就是:
worker 0 如何主动发起反向传播,然后进入分布式引擎?
woker 0 在内部如何发起对 worker 1 的反向传播请求?
worker 1 如何被动接受反向传播消息,然后进入分布式引擎?
我们找一找如何发起反向传播,按照从下往上的顺序进行。这里也有两种:
一种是主动发起,比如上图之中 worker 0 的 loss 之上主动调用backward 方法。
一种是内部隐式发起,比如上图的 worker 0 之中的 t3 如何通过 recv 告诉 worker 1,你应该启动反向传播了。
我们从上往下看分布式 autograd 的 backward 如何主动调用,比如在示例之中会显示调用。
在 <code>torch/_C/_distributed_autograd.pyi</code> 之中我们可以看到如下注释:
因此我们去torch/csrc/distributed/autograd/init.cpp文件中看看。
省略了部分代码,这里能看到生成了上下文,定义了 backward,get_gradients等等。
具体 backward 定义在 torch/csrc/distributed/autograd/autograd.cpp。
可以看到,最终会调用到 DistEngine::getInstance().execute(context_id, roots, retain_graph) 完成反向传播。这就进入了引擎。
因为是隐式发起,所以代码比较隐蔽,我们这次采用从下至上的方式来剥丝抽茧。我们知道,如果节点之间要求反向传播,会发送BACKWARD_AUTOGRAD_REQ,所以我们从 BACKWARD_AUTOGRAD_REQ 开始发起寻找。
在 torch/csrc/distributed/autograd/rpc_messages/propagate_gradients_req.cpp 之中 PropagateGradientsReq::toMessageImpl 会调用到 BACKWARD_AUTOGRAD_REQ。
继续找谁发出来的 BACKWARD_AUTOGRAD_REQ,就是谁调用到了 toMessageImpl?原来在 torch/csrc/distributed/autograd/functions/recvrpc_backward.cpp 这里构建了 PropagateGradientsReq,会使用 toMessage 来构建一个消息。即,RecvRpcBackward 的调用会发送 BACKWARD_AUTOGRAD_REQ。
所以我们知道,在 RecvRpcBackward 的执行时候,会发送 BACKWARD_AUTOGRAD_REQ,发送给下一个节点。具体哪里调用 RecvRpcBackward?我们会在下一篇 DistEngine 之中介绍。
此时具体如下,对应就是 worker 0 的 t3 给 worker 1 发送 BACKWARD_AUTOGRAD_REQ 消息。
对应示例图就是:
我们接下来看看接收方如何处理反向传播,我们再次回到 worker 1,就是图上的 send 节点如何接受反向传播消息。
在生成 TensorPipeAgent 时候,把 RequestCallbackImpl 配置为回调函数。这是 agent 的统一响应函数。前面关于代理接收逻辑时候,我们也提到了,会进入 RequestCallbackNoPython::processRpc 函数。其中可以看到有对 BACKWARD_AUTOGRAD_REQ 的处理逻辑。
这种是 RPC 的正常流程。
在 processBackwardAutogradReq 之中会:
获取 DistAutogradContainer。
获取 上下文,该上下文是之前在前向传播过程之中建立的,从前文可知,本图例之中,worker 0 和 worker 1之中每个 autograd 传播都共享同一个上下文 context id。
通过发送方的 context id,从上下文之中获取到对应的 SendRpcBackward。这里我们看到了上下文是如何使用。
使用 sendFunction 作为参数,调用 executeSendFunctionAsync 进行引擎处理。
在 worker 1 的 DistEngine::executeSendFunctionAsync 内部,会进行辗转处理,最终发送 BACKWARD_AUTOGRAD_REQ 到其反向传播的下游,所以我们继续在示例图之上修改拓展,增加一个 BACKWARD_AUTOGRAD_REQ。
我们可以看到有两个途径进入 dist autograd 引擎,启动反向传播:
一个是示例代码显式主动调用 backward,进而调用到 DistEngine::getInstance().execute,就是 worker 0。
一个是被动调用 DistEngine::getInstance().executeSendFunctionAsync,就是 worker 1(当然,worker 0 的 send 也对应了一个被动调用)。
现在从上至下/自下而上两种查找反向传播的发起源头,都归结到了 DistEngine,所以我们下一篇就介绍 DistEngine。