论文动机
而在最近公布的 ICLR 2018 入围名单中,另一篇数据增广相关论文脱颖而出,而 SamplePairing 出局。仔细阅读 Mixup 的论文,发现它其实是对 SamplePairing 的更进一步延伸。
名词解释
Empirical Risk Minimization (ERM):机器学习的经验风险最小化,ERM 策略认为,经验风险最小化的模型是最优化的模型。可参照李航的《统计学习方法》[1] 进行理解。
Βeta分布:既然概率论中的贝塔分布,是指一组定义在是指一组定义在(0,1)区间的连续概率分布,有两个参数 α 和 β。论文中 α 和 β 相等。Βeta 分布的定义、概率密度函数和性质可参考 PRML [2]。
为了理解 Beta 分布,使用 Python 可视化 Beta 的模型。论文选择的超参数是 α=0.2 和 0.4,此处主要观察 α 变化对应的概率分布变化。
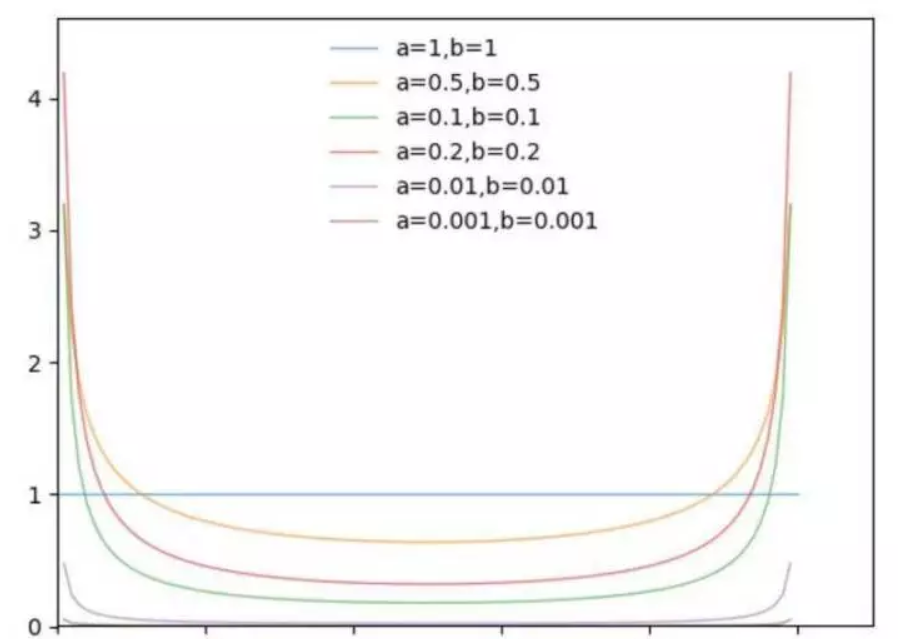
从上图可以看出,α 趋近于 0 时,概率分布趋近于 x-0 和 x=1 两种情况,在论文中代表 ERM。
模型细节
SamplePairing
SamplePairing 的实现很简单,两幅图片直接像素相加求平均,监督的 label 不变。但是在训练过程中,先用 ILSVRC 数据集普通数据增广方式,完成多个 epoch 后间歇性禁止 SamplePairing,在训练损失函数和精度稳定后,禁止 SamplePairing 进行微调。
个人认为相当于随机引入噪声,在训练样本中人为引入误导性的训练样本。
mixup

△ mixup实现公式、Python源代码和可视化实现
其中 (xi, yi) 和 (xj, yj) 是训练集随机选取的两个数据,λ ∈ [0,1],λ ∼ Beta(α,α)。
mixup 扩展训练集分布基于这样的先验知识:线性特征向量的混合导致相关目标线性混合。混合超参数 α 控制特征目标之间的插值强度,α→0 时表示 ERM。
mixup 模型实现方式简单,PyTorch 7 行代码即可实现。上图中的可视化表明,mixup 导致决策边界模糊化,提供更平滑的预测。
实验
论文的实验过程很丰富,包括 CIFAR-10,CIFAR-100,和 ImageNet-2012,随机噪音测试,语音数据,facing adversarial examples 黑盒攻击和白盒攻击,UCI 数据集,以及稳定训练 GAN 网络。
对于具有代表性的 ImageNet-2012,Top-1 的精度至少提高 1.2%。
讨论
论文提出,在训练过程中,随着 α 增加,训练误差越来越大,而在验证验证集测试中泛化误差反而减少。这与论文提出的假设相同:mixup 隐含控制模型的复杂度。但是论文没有提出 bias-variance trade-off 的理论解释。
论文提出一些进一步探索的可行性:
mixup 是否可以应用在其他监督学习问题,比如回归和结构化预测。mixup 可能在回归问题容易实现,结构化预测如图像分割等问题,实验效果不明显。
mixup 是否可以用于半监督学习、无监督学习或强化学习。当然作者是假设,希望有后来者证明 mixup 是理论可行的。
mixup 来自 MIT 和 Facebook AI Research。ICLR 是双盲评审,官网上的匿名评审意见普遍认为 mixup 缺乏理论基础,但是实验效果具有明显优势。笔者个人认为在 mixup 基础上,还有很多坑可以填。
原文发布时间为:2018-03-7
本文作者:陈泰红