最近在看QA,对dataset不是很了解,所以看了一下pytorch中的squad_convert_example_to_features。
以下为pytorch源代码:
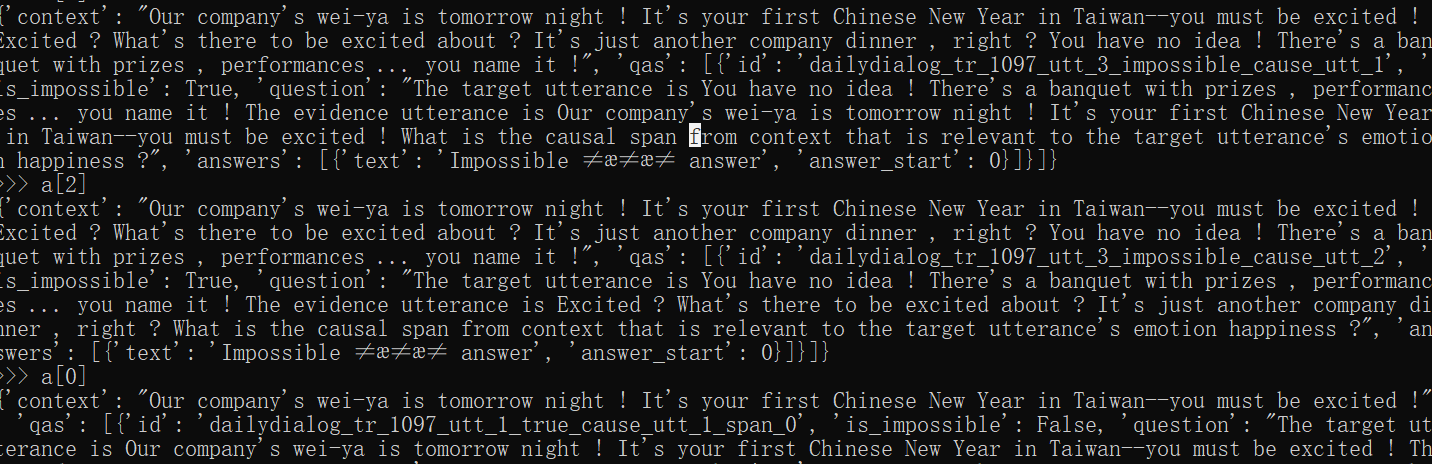
其中example数据大致呈现(不完整):
关于encode_plus的解释:
结果:
结果:此时doc_stride=0
{'overflowing_tokens': [7592, 1010, 2026, 2365, 2003, 3013, 2075, 1012], 'num_truncated_tokens': 6, 'input_ids': [101, 7592, 1010, 2026, 2365, 2003, 5870, 1012, 102, 7592, 1010, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
结果:此时doc_stirde=1
{'overflowing_tokens': [1010, 2026, 2365, 2003, 3013, 2075, 1012], 'num_truncated_tokens': 6, 'input_ids': [101, 7592, 1010, 2026, 2365, 2003, 5870, 1012, 102, 7592, 1010, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
结果:此时doc_stride=2
{'overflowing_tokens': [2026, 2365, 2003, 3013, 2075, 1012], 'num_truncated_tokens': 6, 'input_ids': [101, 7592, 1010, 2026, 2365, 2003, 5870, 1012, 102, 7592, 1010, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
pytorch中源代码:
在生成dataset的时候,若样本中的contetx长度过长,将会进行分段(question+context),当作一组训练数据。
![JAVA 系列——>开发工具IntelliJ IDEA的安装以及配置、快捷键IDEA 简介[图]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)