矩阵乘法中的共享内存($C = AA^T$)
先前矩阵乘法的一个变体可以用来说明如何处理对全局存储器的分步访问以及共享存储器组冲突。 这个变体只是使用A的转置来代替B,所以$C = AA^T$。
$C = AA^T$的简单实现在Unoptimized处理对全局内存的跨步访问中显示
未经优化的对全局存储器的分步访问的处理:
在未优化的对全局存储器的逐行访问的处理中,C的第row,th col元素是通过取A的第th行和第col行的点积获得的。该内核的有效带宽为3.64 GB / s在NVIDIA Tesla M2090上。 这些结果远远低于C = AB内核的相应测量结果。 不同之处在于,对于每个迭代i,在第二项中A的线程如何访问A中的元素[col TILE_DIM + i]。 对于线程变形,col表示A的转置的顺序列,因此col TILE_DIM表示跨度为w的跨步存取,导致大量浪费的带宽。
避免跨越访问的方式是像以前一样使用共享内存,除非在这种情况下,warp会将一行A读入共享内存块的列中,如使用来自全局内存的合并读取的优化处理跨步访问。
使用来自全局内存的合并读取优化处理跨度访问:
使用来自全局内存的合并读取对跨步访问进行优化处理时,使用共享transposeTile来避免点积中第二项中的未合并访问以及前一示例中共享的aTile技术,以避免第一项中的未合并访问。在NVIDIA Tesla M2090上,该内核的有效带宽为27.5 GB / s。这些结果略低于最终内核对于C = AB所获得的结果。造成差异的原因是共享内存组冲突。
for循环中transposedTile中元素的读取没有冲突,因为每个半变形的线程都会读取瓦片的行,从而导致跨单元的单元跨度。但是,从全局内存复制磁贴到共享内存时发生银行冲突。为了使来自全局存储器的加载能够合并,数据从全局存储器中顺序读取。然而,这需要以列的形式写入共享内存,并且由于在共享内存中使用了wxw磁贴(tile),这导致了w个银行的线程之间的跨度 - 每个线程都经历了同一个银行。 (回想一下,对于计算能力为2.0或更高的设备,w选为32)。这些多路银行冲突非常昂贵。简单的补救措施是填充共享内存数组,使其具有额外的列,如下面的代码行所示。
这种填充消除了冲突,因为现在线程之间的跨度是w + 1个存储体(即对于当前设备是33个),由于用于计算存储体索引的模算术,这相当于单位步长。 此次更改之后,NVIDIA Tesla M2090上的有效带宽为39.2 GB / s,与上一次C = AB内核的结果相当。
表3总结了这些优化的结果。
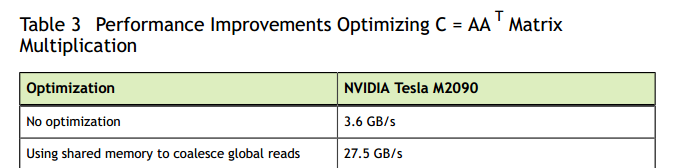
应该将这些结果与表2中的结果进行比较。从这些表中可以看出,合理使用共享内存可以显着提高性能。
本节中的示例说明了使用共享内存的三个原因:
为了能够对全局内存进行合并访问,特别是为了避免大步幅(对于一般矩阵,步幅远远大于32)
消除(或减少)来自全局内存的冗余负载
避免浪费带宽
![数据库设计理论及应用(4)——概念结构设计1.概念模型 2.销售子系统的分E-R图 3.视图的集成 4.设计基本E-R图[图]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)