1 由损失函数引出一堆“风险”
1.1 损失函数
在机器学习中,所有的算法模型其实都依赖于最小化或最大化某一个函数,我们称之为“目标
最小化的这组函数被称为“损失函数”。什么是损失函数呢?
损失函数描述了单个样本预测值和真实值之间误差的程度。用来度量模型一次预测的好坏。
损失函数是衡量预测模型预测期望结果表现的指标。损失函数越小,模型的鲁棒性越好。
常用损失函数有:
0-1损失函数:用来表述分类问题,当预测分类错误时,损失函数值为1,正确为0
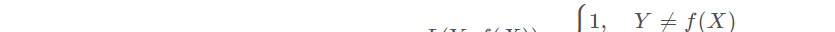
平方损失函数:用来描述回归问题,用来表示连续性变量,为预测值与真实值差值的平方。(误差值越大、惩罚力度越强,也就是对差值敏感)

绝对损失函数:用在回归模型,用距离的绝对值来衡量
对数损失函数:是预测值Y和条件概率之间的衡量。事实上,该损失函数用到了极大似然估计的思想。P(Y|X)通俗的解释就是:在当前模型的基础上,对于样本X,其预测值为Y,也就是预测正确的概率。由于概率之间的同时满足需要使用乘法,为了将其转化为加法,我们将其取对数。最后由于是损失函数,所以预测正确的概率越高,其损失值应该是越小,因此再加个负号取个反。
以上损失函数是针对于单个样本的,但是一个训练数据集中存在N个样本,N个样本给出N个损失,如何进行选择呢?
这就引出了风险函数。
1.2 期望风险
期望风险是损失函数的期望,用来表达理论上模型f(X)关于联合分布P(X,Y)的平均意义下的损失。又叫期望损失/风险函数。
1.3 经验风险
模型f(X)关于训练数据集的平均损失,称为经验风险或经验损失。
其公式含义为:模型关于训练集的平均损失(每个样本的损失加起来,然后平均一下)
经验风险最小的模型为最优模型。在训练集上最小经验风险最小,也就意味着预测值和真实值尽可能接近,模型的效果越好。公式含义为取训练样本集中对数损失函数平均值的最小。
1.4 经验风险最小化和结构风险最小化
期望风险是模型关于联合分布的期望损失,经验风险是模型关于训练样本数据集的平均损失。根据大数定律,当样本容量N趋于无穷时,经验风险趋于期望风险。
因此很自然地想到用经验风险去估计期望风险。但是由于训练样本个数有限,可能会出现过度拟合的问题,即决策函数对于训练集几乎全部拟合,但是对于测试集拟合效果过差。因此需要对其进行矫正:
结构风险最小化:当样本容量不大的时候,经验风险最小化容易产生“过拟合”的问题,为了“减缓”过拟合问题,提出了结构风险最小理论。结构风险最小化为经验风险与复杂度同时较小。
1.5 小结
1、损失函数:单个样本预测值和真实值之间误差的程度。
2、期望风险:是损失函数的期望,理论上模型f(X)关于联合分布P(X,Y)的平均意义下的损失。
3、经验风险:模型关于训练集的平均损失(每个样本的损失加起来,然后平均一下)。
4、结构风险:在经验风险上加上一个正则化项,防止过拟合的策略。
2 最小二乘法
2.1 什么是最小二乘法
最小二乘法源于法国数学家阿德里安的猜想:
对于测量值来说,让总的误差的平方最小的就是真实值。这是基于,如果误差是随机的,应该围绕真值上下波动。
即:
为了求出这个二次函数的最小值,对其进行求导,导数为0的时候取得最小值:
进而:
正好是算数平均数(算数平均数是最小二乘法的特例)。
这就是最小二乘法,所谓“二乘”就是平方的意思。
(高斯证明过:如果误差的分布是正态分布,那么最小二乘法得到的就是最有可能的值。)
2.2 线性回归中的应用
1 matlab版本
2014a
2 参考文献
[1] 包子阳,余继周,杨杉.智能优化算法及其MATLAB实例(第2版)[M].电子工业出版社,2016.
[2]张岩,吴水根.MATLAB优化算法源代码[M].清华大学出版社,2017.
[3]周品.MATLAB 神经网络设计与应用[M].清华大学出版社,2013.
[4]陈明.MATLAB神经网络原理与实例精解[M].清华大学出版社,2013.
[5]方清城.MATLAB R2016a神经网络设计与应用28个案例分析[M].清华大学出版社,2018.