<a href="http://www.cnblogs.com/zhaopei/p/4368417.html#autoid-0-0">效果图:</a>
<a href="http://www.cnblogs.com/zhaopei/p/4368417.html#autoid-0-2">第一、分析url</a>
<a href="http://www.cnblogs.com/zhaopei/p/4368417.html#autoid-1-0">智联招聘:</a>
<a href="http://www.cnblogs.com/zhaopei/p/4368417.html#autoid-1-1">猎聘网:</a>
<a href="http://www.cnblogs.com/zhaopei/p/4368417.html#autoid-1-2">前程无忧:</a>
<a href="http://www.cnblogs.com/zhaopei/p/4368417.html#autoid-1-3">第二、用到了HtmlAgilityPack.DLL ...</a>
<a href="http://www.cnblogs.com/zhaopei/p/4368417.html#autoid-2-0">1.设置访问url页面的编码</a>
<a href="http://www.cnblogs.com/zhaopei/p/4368417.html#autoid-2-1">2.元素路径下的元素集合</a>
<a href="http://www.cnblogs.com/zhaopei/p/4368417.html#autoid-2-2">3、取标签的属性值 Attributes</a>
<a href="http://www.cnblogs.com/zhaopei/p/4368417.html#autoid-2-3">4.取标签的中间的文本 InnerText</a>
<a href="http://www.cnblogs.com/zhaopei/p/4368417.html#autoid-2-4">5.过滤选择特定的id 或 class</a>
<a href="http://www.cnblogs.com/zhaopei/p/4368417.html#autoid-2-5">第三、浏览器滚动条的onscroll事件</a>
<a href="http://www.cnblogs.com/zhaopei/p/4368417.html#autoid-3-0">取窗口可视范围的高度[浏览器可见区域高度]</a>
<a href="http://www.cnblogs.com/zhaopei/p/4368417.html#autoid-3-1">取窗口滚动条高度[滚动条距离顶部的高度]</a>
<a href="http://www.cnblogs.com/zhaopei/p/4368417.html#autoid-3-2">取文档内容实际高度</a>
<a href="http://www.cnblogs.com/zhaopei/p/4368417.html#autoid-3-3">滚动条距离底部的高度</a>
合并查询本来就是为了简单方便,所以也就没有弄很复杂了,一个页面搞定。如果同学们有什么好的想法,可以建议建议。
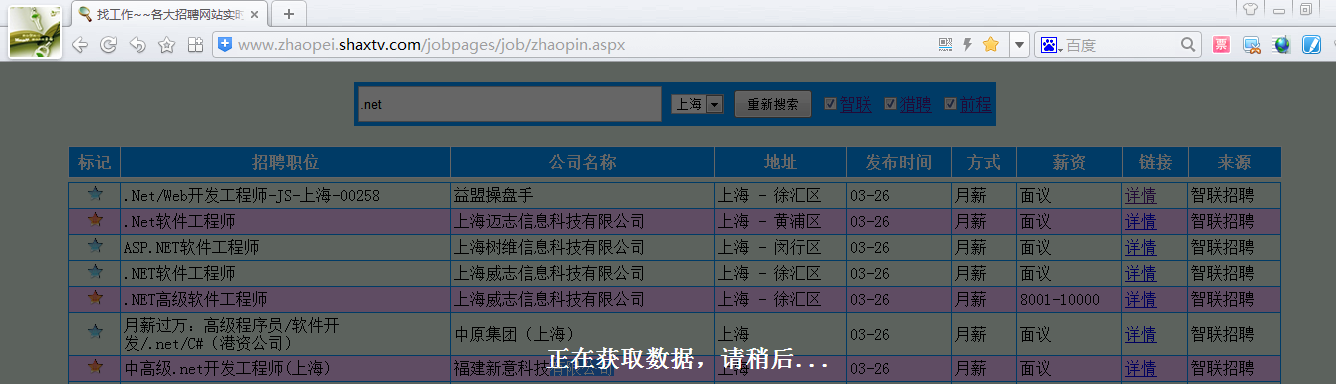
就一个简单的关键字输入框、工作地点的选择和信息来源网站。
其实看上去很简单,实现起来也很简单。~~代码不多,难度也很小。很多时候需要的技术不是很多,想法更重要。
进入招聘网站的时候url大串大串的,我们需要用的的就三个。搜索关键字、地址和页码。
http://sou.zhaopin.com/jobs/searchresult.ashx?jl=地址&kw=关键字&p=页码
jl=地址
kw=关键字
p=页码
然后地址的话 直接中文地址就ok了
http://www.liepin.com/zhaopin/?key=关键字&dqs=地址&curPage=页码
key=关键字
dqs=地址
curPage=页码
地址有一个对应的编号
("北京", "010");
("上海", "020");
("广州", "050020");...等等 也是在猎聘网选择地址的地方右键 审查元素可以看到,如下:

http://search.51job.com/jobsearch/search_result.php?jobarea=地址&keyword=关键字&curr_page=页码
jobarea=地址 [和猎聘一样的查找方法]
keyword=关键字
curr_page=页码
htmlWeb.OverrideEncoding = Encoding.GetEncoding("UTF-8");
设置编码为UTF-8,具体看对应页面采用的编码。
var ulS = response.DocumentNode.SelectNodes("//*[@id='sojob']/div[2]/div/div/ul/li");
SelectNodes方法里面的这串字符串怎么来?
右键审查元素 Copy XPath 就ok了。不过如果js有动态修改document树的话 那么这个路径就不准了,需要自己微调下。
如:取a标签的title值。
titleName = item.SelectSingleNode(xpath + "/a").Attributes["title"].Value;
company = item.SelectSingleNode(xpath + "/a/dl/dt[@class='company']").InnerText;
XPath 中 标签名后面加上中括号 和@ 如: "/a/dl/dt[@class='company']"
<a href="http://www.phpernote.com/javascript-function/755.html" target="_blank">js获取滚动条距离浏览器顶部,底部的高度,兼容ie和firefox</a>
取滚动条距离底部的高度,当滚动条到最底部的时候,通过ajax异步请求后台,加载下一页数据,这样就可以免了翻页的麻烦了。
本文转自张昺华-sky博客园博客,原文链接:http://www.cnblogs.com/sky-heaven/p/5775761.html,如需转载请自行联系原作者