> 趣店的容器化进程经历过三个里程碑:docker、单集群脚本化管理、多集群平台化管理。为了兼顾日常业务的需求开发,每一个里程均是由小部分人主导推动,由点及面地进行推广,并通过在小范围的试错中寻找最适合趣店业务场景的容器化方案。容器化为趣店的服务隔离及服务器统一化管理提供了基础条件,并且通过容器化迁移为趣店每月节省至少10万元服务器费用。(由于迁移工作以PHP服务作为试点,因此本文中的案例亦是以PHP为主)
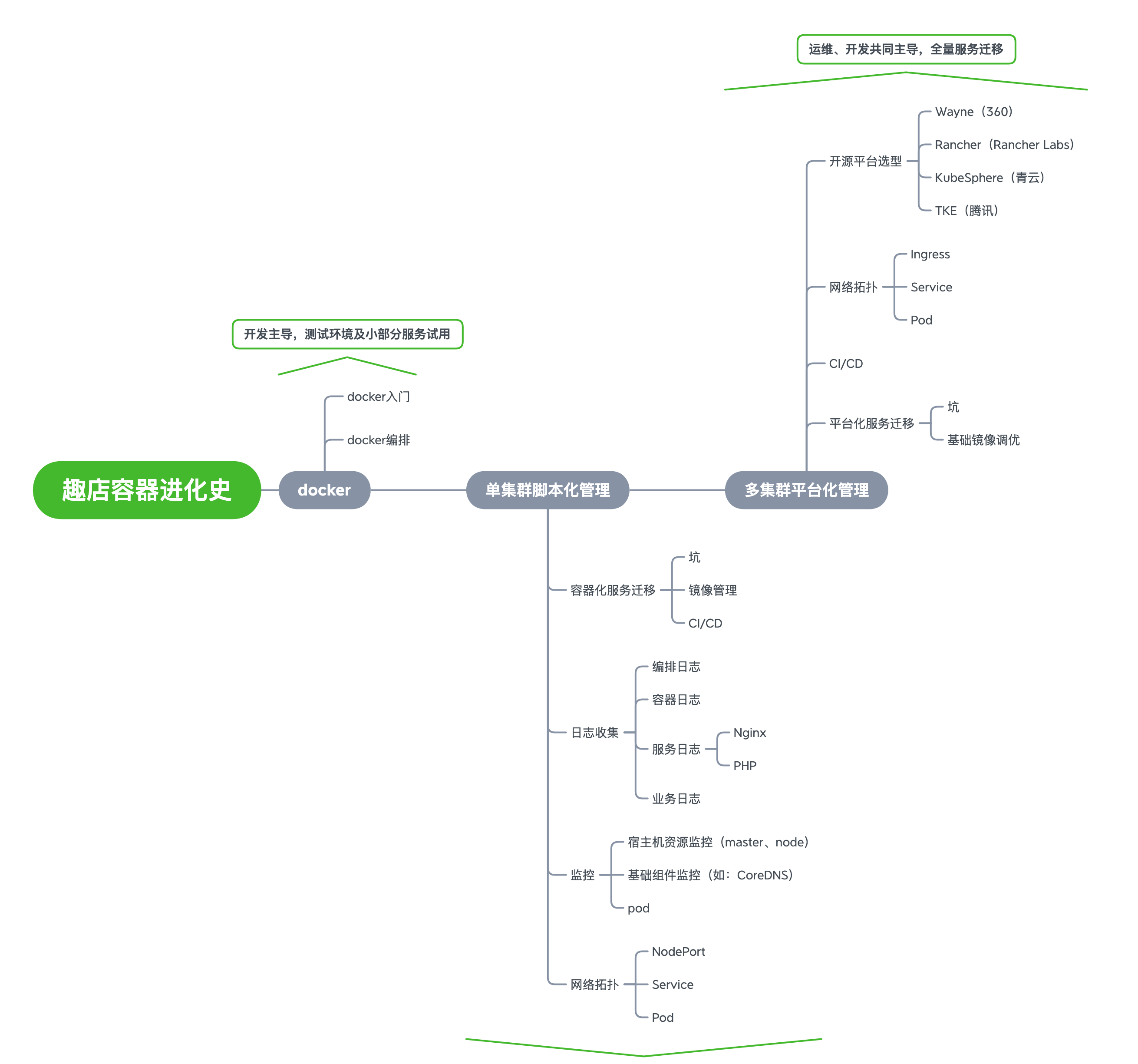
趣店容器进化史快速预览图
> 作为容器化推进的第一阶段,此阶段由开发主导,推广开发及测试环境容器化使用,并进行小部分服务线上容器化试用。
> 容器化推进初期,此时我们内部对于容器较为了解的人员并不多,开发不知道应该如何使用容器,运维对于如何维护容器下的服务也没有经验,因此在这个阶段我们着重对全体开发人员及运维人员进行初级容器入门分享,分享主要包括以下几个方面:
Docker环境搭建
> 主要用于引导开发人员搭建本地Docker开发环境,进行初步的容器概念建模。
Docker命令解析

docker命令解析分享资料
> 该分享主要讲解Docker的常用指令、拆解容器的部署流程并简要介绍通过Swarm进行集群部署的方式。
Dockerfile最佳实践
> 参考《Best practices for writing Dockerfiles》,分享如何以更优雅的方式编写Dockerfile。
> 我们的部分开发人员尝试更深层次地应用容器化,例如基于docker-compose推广docker在本地开发环境落地。这一推广对于微服务一类单个项目依托于多个服务的开发环境部署提供了极大的便利,同时也在开发环境的使用中进一步深化大家对容器的理解。在这一阶段开发了简易的K8s编排脚本,对新上线的小服务尝试使用K8s部署服务。
> 考虑到容器化仍处于尝试阶段且需要进行定制化脚本开发,因此第二阶段仍是以开发作为主导。本阶段开始对主要服务的小流量环境进行容器化迁移,通过开发更完善的K8s编排脚本以优化服务的持续集成与部署。
> 随着全员对容器认知水平的提高,在这一阶段我们的小部分开发开始尝试进行线上小流量环境的迁移,迁移过程也曾遇到一些问题。
CoreDNS负载异常导致部分请求错误
> 现象:在这一阶段的迁移过程中由于K8s的CoreDNS负载异常,我们已迁移服务曾出现短暂的不可用(因服务分区部署的关系我们及时将部署于K8s服务的服务流量摘除) > > 解决方案:容器化迁移是各方(运维、开发、K8s服务提供商)的磨合阶段,在这一阶段应提前准备及演练运行于K8s的服务异常情况下的流量切换方案。由于业务服务对K8s基础服务的强依赖关系,基础服务的监控、异常转移均需提前完善及演练。
> 镜像管理作为容器化迁移不可或缺的一部分,自建的镜像仓库能够更好的保障内部服务镜像的安全性(镜像可能包含服务源码),且部署于内网的镜像仓库能够极大提高部署速度。为简化镜像的管理与维护,我们在内网部署开源的Harbor服务管理内部镜像。
> 在这一阶段我们通过自研的脚本(集成编排文件生成、镜像构建、部署)及Jenkins实现服务的CI/CD。由于这一阶段的CI/CD流程仍是试验阶段并无十分完善,这里暂时不展开叙述,较为完善的流程可参考下一阶段迁移的CI/CD。
编排日志
> 编排日志目前我们没有特意收集,大部分情况下还是部署或者调度出现问题的时候由运维进入集群内通过Kubectl查看日志情况。
容器日志
> 由于大部分服务的日志都是往指定目录输出,目前并没有很好的利用容器的标准输出作为容器内部服务日志输出的统一出口,所以容器日志当前仍处于待挖掘阶段。
服务日志
- Nginx
- PHP
> 除去常规的Nginx access_log,我们在迁移过程中还需要重点关注Nginx error_log及PHP error_log,极少部分请求可能会因迁移过程中的操作不当而引发异常,此时可通过排查服务的错误日志及时发现并修复问题。
业务日志
> 由于我们的业务日志输出并无统一规范,因此无法通过常规的容器标准输出采集日志,而是通过Volume的方式将Pod的输出日志挂载至节点主机目录,再通过节点主机的Filebeat + Kafka将日志统一收集至日志服务器。
宿主机资源监控(Master、Node)
> 主机的资源监控包括:CPU、内存、磁盘、网卡流量等等,尽可能详细地收集主机监控信息对于异常情况下的问题排查有着极大的帮助。
基础组件监控(如:CoreDNS)
> 围绕于集群服务的各种基础组件:kube-apiserver、kube-controller-manager、kube-scheduler、kubelet、kube-proxy、CoreDNS等等,也需要纳入监控范围,避免因为单个基础组件的异常影响整个集群内部业务服务的稳定性。
Pod
- PHP-FPM
> Pod部署了可用于输出Nginx-FPM和PHP实时状态的Exporter,通过常规的Prometheus + Grafana方案实现K8s服务的监控。
NodePort
Service
> 在这一阶段考虑到现有服务是逐步迁移,为保持原有线上灰度测试方案的可用性,并未使用常规的Ingress作为外部流量的入口。
> 最终阶段我们基于开源平台进行二次定制化开发,由运维、开发共同主导。这一阶段的主要工作是通过定制化开发打通 开发-测试-审批-线上部署 的完整流程,并对现有的线上服务全量迁移至K8s集群。
Wayne(360)
Rancher(Rancher Labs)
KubeSphere(青云)
tke(腾讯)
K8s多集群管理平台对比
> 在最开始的开源平台选型阶段我们综合对比了目前较为主流的4大开源平台:Wayne、Rancher、KubeSphere、tke,由于我们现有业务均为多区部署因此平台是否支持多集群管理成为我们最重要的考察因素。各项因素综合对比后最终我们选用Wayne作为基础进行二次定制化开发。但是由于我们基于Wayne开发的版本360团队有较长时间未更新维护,导致最新版需要修复少量bug后才能正常使用。 > > 说明:此对比截止时间为2019年12月,此期间各平台可能有新的功能迭代
Ingress
> 由于我们的服务大部分为微服务,继续使用Nodeport的方式每个项目均需要占用大量的集群端口号,因此在全量服务迁移阶段我们调整为使用常规的Ingress作为外部流量的入口。
> 在这一阶段我们进一步对CI/CD流程进行了完善,镜像通过CI Runner的方式自动构建,减少上线过程的等待时间,并通过界面化的方式完成多集群部署,打通从镜像构建、审批、部署上线的完整流程。
镜像构建流程
> 由上图可以看出,通过Gitlab的CI流程我们完善了代码合并后自动构建镜像并推送镜像至镜像仓库的流程。在K8s接口化的服务端我们已提前配置好每个服务的Deployment基础模板,构建成功后调用接口写入对应版本信息即可生成待发布的Deployment模版。
代码上线流程
> 由于我们的代码上线过程需要监测每次上线是否会对线上数据造成波动,因此上线环节全程由开发手动在平台化后台操作没有实现全流程自动化。
配置上线流程
ENV上线流程
> 配置上线则相对简单大部分配置变更后只需要重启Pod即可,因此这一部分做了自动化处理。
> 平台化服务迁移对于运维的工作量较大,由于各服务配置差异较大,运维需要根据每个服务的不同配置Deployment基础模板。而我们数百个微服务由于种种历史原因没有保持环境统一,运维梳理环境迁移服务的过程中容易疏漏一些细微的环境配置差异,有些差异可能又是在小部分场景下才会触发异常,因此也列出来便于大家避坑。
Pod可用连接数不足预期
> 现象:在线上压测过程发现部署于K8s中的服务当单Pod QPS达到1万左右开始出现TCP连接异常,无法继续增压。 > > 解决方案:单Pod可用的连接数极大的依赖于节点服务器,单Pod无法支撑更大连接数时需考虑调优各节点服务器的内核参数,如调整最大打开文件限制(包括用户级别与系统级别)、最大追踪TCP连接数、系统TIME_WAIT数量等。
单行大日志
> 现象:Filebeat采集的日志中出现部分业务日志丢失。 > > 解决方案:由于Kafka对单条消息大小的限制,如果单行日志过大会导致日志无法被采集,此时应规范业务日志的输出,避免出现单行大日志。
上传文件/POST大小限制
> 现象:流量从物理机器迁移至K8s后部分服务请求出现 HTTP Code 413 或下游服务接收到的请求数据为空。 > > 解决方案:Nginx及PHP-FPM层面对上传文件大小、POST body大小均有限制,因此需要将限制大小配置值调整至与原物理机器一致。
服务内存大小限制
> 现象:服务从物理机器迁移至K8s后部分计划任务无法正常执行,部分后台异步导出队列执行异常。 > > 解决方案:通常情况下我们会使用一台物理服务器同时部署服务喝执行计划任务,而大部分计划任务、队列可能需要使用大量的内存用于统计之类的逻辑,此时应调整K8s计划任务及队列Pod的内存上限限制,同时可能还需要修改PHP的内存大小限制,并视计划任务情况调整最大执行时间避免因计划任务超时触发失败重试。
部分节点资源负载异常
> 现象:单K8s集群中出现小部分节点资源负载较高,而其余节点较为空闲。 > > 解决方案:此时可通过K8s的反亲和性配置将重资源的Pod分散部署在各节点服务器中,避免小部分节点服务器同时部署重资源Pod出现资源争抢。
理论与实践(单服务容器 VS 多服务容器)
> 对于单Pod是部署单服务还是多服务应视业务情况而定。例如,对于需要提供界面的PHP服务我们推荐使用多服务的方式,依赖Supervisor将Nginx、PHP-FPM部署于同一个Pod中,这样可以降低Nginx需同时处理FastCGI请求及静态资源请求带来的K8s部署模板配置复杂度。但是单Pod部署多服务的场景需额外注意对各服务的可用性监控,避免出现其中的某个服务异常而K8s无法探测的情况。
可配置
> 基础镜像的可配置对于容器化迁移至关重要,我们建议用尽可能少的基础镜像通过可配置的方式实现对各种不同服务部署环境的兼容,降低服务环境差异带来的基础镜像维护成本。例如将Nginx、PHP-FPM的上传文件大小限制、内存大小限制等参数通过环境变量的方式,利用Entrypoint机制在启动Supervisor前先执行shell完成对环境配置的定制化替换。
运行模式可切换
- CLI(队列/计划任务)
- Swoole
> 由于PHP服务通常以多种方式结合使用,因此通过环境变量配置的方式,我们的基础镜像亦支持多种运行模式按需切换,提高基础镜像的可复用性。
PHP7基础镜像示例
- Dockerfile示例
- Entrypoint示例
> 通过上面的示例可以看出为了实现可配置我们使用了大量的环境变量,结合Entrypoint的替换脚本提高基础镜像的兼容性。
以上是我们趣店容器化历程的一些经验分享,整个容器化遵循循序渐进的原则,在大面积推广前需对开发及运维(甚至测试)人员进行知识普及,避免在只有少数人掌握容器、K8s等知识体系的情况下强行线上推广。当然容器化并不是一味治百病的药,我们目前依然有小部分服务因为一些考量因素部署在物理服务器。容器化是为了提高各方的效率,切不可为了容器化而容器化。/[email protected]