本節書摘來自華章社群《clojure資料分析秘笈》一書中的第1章,第1.8節從網頁表中抓取資料,作者(美)eric rochester,更多章節内容可以通路雲栖社群“華章社群”公衆号檢視
1.8 從網頁表中抓取資料
網際網路上資料無處不在。遺憾的是,許多網際網路上的資料不易獲得。這些資料深埋于表、文章或者深層嵌套的标簽中。網絡抓取是一件讓人讨厭的體力活,但是它通常又是唯一能将這些資料取出用于分析的手段。本方法描述如何加載網頁并挖掘其内容以便取出資料。
1.8.1 準備工作
首先,需要将enlive添加到項目的依賴中:
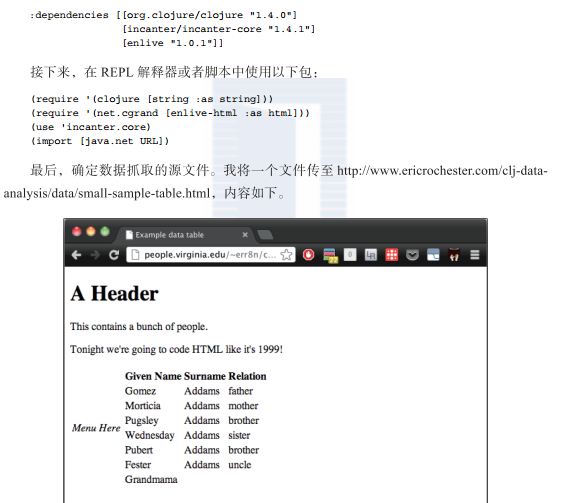
有意地去掉檔案的其他内容,并使用表的布局。
1.8.2 具體實作
由于任務稍有些複雜,這裡将每步的工作寫成函數。

現在,選擇所有表頭單元,抽取其中的文本,将每個轉換為關鍵詞,然後将整個序列裝入向量。得到了資料集的頭部:
需要注意的是,在此展示的代碼是多次試錯後的結果。螢幕抓取的過程是這樣的。通常我将下載下傳并儲存頁面,進而不需要持續向web伺服器發送請求。然後啟動repl并在其中解析網頁。可以通過浏覽器的“檢視源代碼”功能檢視網頁和html,并且可以在repl解釋器中互動式地檢查網頁中的資料。由于比較友善,在工作過程中,我可以不斷地在repl解釋器和文本編輯器中複制、粘貼代碼。這種工作流程和環境使得螢幕抓取這樣一個即使一切正常都需要精細操作的困難任務變得很輕松。