本節書摘來自華章計算機《scala機器學習》一書中的第1章,第1.5節,作者:[美] 亞曆克斯·科茲洛夫(alex kozlov),更多章節内容可以通路雲栖社群“華章計算機”公衆号檢視。
通常,這五種數字彙總方式不足以對資料形成初步認識。描述性統計(descriptive statistics)的術語非常通用,并且可以采用非常複雜的方法來描述資料。分位數和帕雷托圖(pareto chart)都是描述性統計的例子,當分析一個以上的屬性時,相關性也是。在大多數情況下都能查閱到這些資料彙總的方法,但通過具體的計算來了解這些方法也很重要。
spark可以運作在本地模式下,這是一種特殊情形。即使在本地模式下,spark也可以在單機上進行分布式計算,不過會受機器的cpu核(或超線程)的數量限制。對配置進行簡單修改後,spark就可在一個分布式叢集上運作,并能使用多個分布式節點上的資源。
下面這組指令可用于下載下傳spark notebook,并從代碼庫中複制所需的檔案:
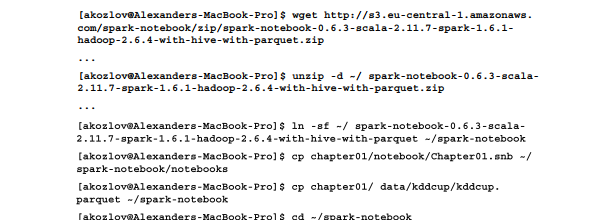

圖1-2 以清單形式來展示spark notebook的首頁
通過點選來打開chapter01 notebook。語句被組織成多個單元,并可通過點選頂部那個向右的小箭頭來執行每個單元(其結果如圖1-3所示)。也可通過菜單cell→run all來一次性運作所有的單元。
首先來觀察一下離散的變量。比如得到另一些觀察屬性。如果像下面的代碼影響了标簽的分布,就不可能這樣做:
在macbook pro上第一次讀入這個資料集可能需要幾分鐘,但是spark會把資料緩存在記憶體中,随後的彙總隻需要一秒鐘左右。spark notebook給出了資料值的分布,如圖1-4所示。
圖1-3 執行notebook中的前幾個單元任務
圖1-4 計算分類字段的值的分布
從這裡可以看出:最流行的服務是private,并且和sf 标志相關。分析依賴關系的另一種方法是看為0的項。比如,s2和s3标志明顯和smtp以及ftp流量相關,因為其他項的值都是0。
當然,最有趣的是與目标變量的相關性,但這些都可通過監督學習算法(在第3章和第5章會詳細介紹)來更好地得到。
類似地,可以通過dataframe.stat.corr()和dataframe.stat.cov()函數計算數值變量的相關性(見圖1-6)。該類支援皮爾森相關系數。另外,也可以直接在parquet檔案上使用标準的sql語句:
最後計算百分數。這通常會對整個資料集排序,其代價非常大。但如果要比較的是第一個或最後一個,通常可對計算進行優化:
從spark notebook的部分示例代碼可看出計算更通用的精确百分位數會有更高的代價。