本節書摘來自華章計算機《大規模java平台虛拟化與調優》一書中的第1章,第1.3節,作者:(美)emad benjaminliang) 更多章節内容可以通路雲栖社群“華章計算機”公衆号檢視。
當設計大規模java平台時,需要考慮很多的技術因素。例如,對于建構良好的大規模java平台來說,需要很好地了解java垃圾回收(garbage collection,gc)以及jvm架構、硬體和hypervisor架構。本節中,概要讨論了gc、非一緻記憶體架構(non-uniform memory architecture,numa),以及在理論和實際操作中的記憶體限制。稍後的章節會給出更為詳細的描述,但首先在整體上了解圍繞大規模java平台設計有哪些問題是非常必要的。
1.3.1 java平台在理論和實際中的限制
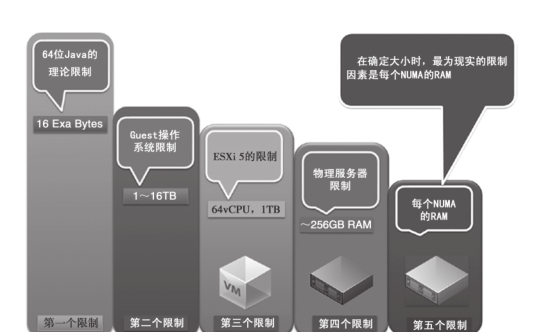
圖1-1展現了java負載在理論和實際中的規模限制,當對jvm負載進行規模劃分時,這些關鍵的限制條件是需要謹記的。
需要強調的很重要的一點就是,jvm的理論限制是16艾位元組(exabyte)。但是,并沒有實際的系統能夠提供這麼大數量的記憶體。是以,我們将其視為第一個理論限制。
第二個限制是guest作業系統所能支援的記憶體量。在大多數場景下,能夠達到多個tb(terabyte),這取決于所使用的作業系統。
第三個限制是esxi 5中每個vm中最多有1tb的ram,對于我們在客戶那裡所遇到的任何負載這都是足夠的。
第四個限制(實際上也是第一個實際的限制)就是典型的esx伺服器上可用的ram數量。我們發現, vsphere主機平均來講會有128~144gb,最多可以達到196~256gb。當然從可行性的角度來看,硬性的限制可能在256gb左右。我們當然也會有更大的基于ram的vsphere主機,如384gb~1tb。但是,這類主機可能更适合于第2類的記憶體資料庫工作負載和傳統的關系型資料庫管理系統(relational database management system,rdbms),它們會使用到如此巨大的計算資源。這些系統需要如此大的vsphere主機的主要原因是大多數(稍微有一些是例外的,如oracle rac)傳統關系型資料庫不會橫向擴充(scale out),而會縱向擴充(scale up)。在第1類和第2類java平台的場景中,橫向擴充是一種可行的方式,是以選擇更為劃算的vsphere主機是可以承受的。在第1類的java負載中,你應當考慮讓vsphere主機有一個更為合理的ram,它的範圍應該在128gb以内。
第五個限制就是伺服器ram的總量以及如何将其劃分為多個numa節點,每個處理器插槽(processor socket)都會是一個numa節點,節點具有numa本地記憶體。numa本地記憶體可以用伺服器ram的總量除以處理器插槽的數量計算得到。我們知道為了獲得最佳的性能,你應該在numa節點的記憶體邊界範圍内确定vm的大小。毫無疑問,esx提供了很多的numa優化選項,但是最好始終要做到numa本地通路。例如,在esx主機中,兩個處理器插槽一共具有256gb的ram(也就是說,它具有兩個numa節點,每個numa節點具有128gb(256gb/2)的ram),這表明,當你确定vm的規模時,它不應該超過128gb,因為這樣就能實作numa的本地通路。
在圖1-1中展現的限制因素能夠幫助你在确定大型jvm規模時,如何做出務實且可行的設計和劃分決策。但是在确定大型jvm規模時,還有其他的考量因素,如gc調優的複雜性以及維護大型jvm所需的知識。實際上,我們客戶群體中絕大多數jvm都是使用4gb ram左右的典型企業級web應用,也就是本書中所述的第1類工作負載。但是,更大的jvm也是存在的,我們有的客戶在jvm上運作大規模的監控系統和大型的分布式資料平台(記憶體資料庫),其規模在4~128gb。對于像vfabric gemfire和sqlfire這樣的記憶體資料
庫同樣如此,在這裡,叢集中單個jvm成員可以達到128gb,而整個叢集的規模可以達到1~3tb。這樣大型的jvm就需要更多關于gc調優的知識。在vmware,過去的幾年中,盡管實體機上的gc調優與虛拟機上并沒有任何差别,但我們依然為很多客戶在gc優化方面提供了很多幫助。原因在于我們将vfabric java以及vsphere的專業知識內建到了一起,這樣就能幫助很多客戶将運作vsphere上的java工作負載實作最優化。當決定是否要垂直擴充jvm和vm的大小時,首先應該要考慮的是水準擴充的方式,我們發現具有水準擴充能力的平台可以獲得更好的可擴充性。如果水準擴充的方案不可行,那就要考慮增加jvm記憶體的大小,并據此增加vm的記憶體。當選擇通過增加堆空間/記憶體來加大jvm的規模時,下一個需要考量的點就是gc調優和處理大型jvm的知識。
考慮到本書所述的第三個限制,esxi 5.1是官方的ga釋出版本;但是,到本書出版之時,vsphere的一些最大限制可能會發生變化。通過官方的vmware産品文檔來了解其最新的最大值。同時要注意,這些vm限制使用成本不菲的硬體,會需要數量衆多的vcpu,但是對于需要這種環境的場景來說,這才能夠確定其價值。
如本章前文所述,在企業級領域,大型java平台可以劃分為3類。圖1-2展現了各種工作負載的類型及其相對的規模。一個流行的趨勢是随着jvm規模的增長,對jvm gc調優知識的需求也在不斷增長。

記住以下幾點是非常重要的(對應圖檔從左到右):
在如今的工作負載中,堆大小小于4gb的jvm最為常見。4gb是一個特殊的場景,因為在64位的jvm空間中,它預設具備32位位址指針的優勢(是以會具有非常高效的記憶體分布機制)。這會需要一些調優,但是并不會很多。這種類型的工作負載屬于本章所定義的第1類的範疇。在伺服器級别的機器上,使用預設的gc算法就足夠了。隻有當響應時間不能滿足要求時,你才需要對其進行調優。如果發生了這樣的場景,你可以遵循第3章,以及第6章中所提供的gc調優指導。
第二種工作負載場景也屬于前文所述的第1類,但可能面對的是組織内部重要的使用者。在這種負載的應用中,我們一般會看到被大規模使用(1000~10 000的使用者)的企業級java web應用。該類型環境的标準是gc調優以及稍大于4gb的jvm。devops團隊通常會具有良好的gc調優知識,并且配置jvm不再使用預設的gc吞吐(throughput)收集器。在這裡我們會看到對于這種類型的工作負載會使用cms(concurrent mark and sweep)gc算法,進而為使用者提供更短的響應時間。cms gc算法由oracle jvm(也就是之前的sun jvm)所提供。關于oracle jvm或ibm jvm中其他gc算法的相關細節和資訊,請參閱第3章和第6章。
第三種工作負載的場景可以劃分到前文所述的第2類,但它是第2類中的一個特殊場景,因為應用程式有時候會因為不能進行水準擴充,而使用更大的jvm。如本章前文所述,一般來講第2類的工作負載通常會是記憶體資料庫。在這種類型中,需要深入地了解jvm gc調優的知識。你的devops團隊必須能夠清晰區分不同的gc收集器并選擇最适合提高吞吐量的收集器(吞吐收集器)(與之相對的是對于延遲性敏感的工作負載應用,則要使用cms gc以獲得更好的響應時間)。
第四種工作負載的場景可以同時劃分為前文所述的第2類和第3類。在這裡,可能會有大型的分布式系統,用戶端的企業級java應用所使用的資料來源于後端的資料fabric,在後端會有一組或更多的記憶體資料庫jvm節點在運作。在這種場景下,需要專家級别的gc調優能力。
除了簡單地維護一個大型的jvm,你必須要了解工作負載的類型。畢竟,客戶經常會垂直擴充jvm,因為他們認為這是一種簡單的部署方式,最好保持已有jvm程序的現狀。讓我們考慮一些jvm的部署和使用場景(可能有一些存在于你目前的部署環境中,也有一些你過去可能遇到過):
某位客戶最初部署了一個jvm程序。随着需要部署的應用不斷增加,這位客戶并沒有通過增加第二個jvm和vm的方式進行水準擴充。與之相反,客戶采取了垂直擴充的方式。所造成的結果就是,已有的jvm必須進行垂直擴充,以承載多個不同類型且需求各異的工作負載。
有一些工作負載,如任務排程器(job scheduler),需要高的吞吐量,而公開通路的web應用則需要很快的響應時間。是以,如果将這些類型的應用放在同一個jvm之中,會使得gc調優的過程複雜化。當對gc進行調優以擷取更高的吞吐量,所付出的代價通常是犧牲響應時間,反之亦然。
即便你可以同時實作更高的吞吐量和更好的響應時間,但這無疑會增加不必要的gc優化行為。當面臨這類的部署選擇時,通常最好的方式是将不同類型的java負載劃分到它們自己的jvm之中。一種方式就是将運作任務排程器的工作負載放到自己的jvm和vm中(對基于web的java應用同樣如此)。
在圖1-3中,jvm-1部署到一個vm上,這個jvm中具有混合的應用負載類型,當試圖縱向擴充jvm-2中的應用時,gc調優和擴充性都會變得更為複雜。更好的方式是将web應用劃分到jvm-3中,而任務排程器劃分到jvm-4中(也就是,水準擴充,并且在必要時具備垂直擴充的靈活性)。如果将jvm-3和jvm-4的垂直可擴充性與jvm-2的垂直可擴充性進行對比,你會發現jvm-3和jvm-4可擴充性更好并且更容易進行調優。
1.3.2 numa
非一緻記憶體架構(non-uniform memory architecture,numa)是一種用于多處理器環境的計算機記憶體設計,在這種環境下,記憶體的通路時間取決于記憶體相對于處理器的位置。在numa中,處理器通路本地記憶體要快于通路非本地記憶體(也就是,其他處理器的本地記憶體或處理器共享的記憶體)。
了解numa的邊界對于确定vm和jvm的大小是非常重要的。理想情況下,vm的大小應該限制在numa邊界之内。圖1-4展現了一個兩插槽的vsphere主機,是以會有兩個numa節點。圖中所展現的工作負載是兩個vfabric sqlfire的vm,每個vm的記憶體和
cpu的規模都調整在了numa節點的邊界之内。如果某一個vm的大小超出了numa邊界,它可能會與其他的numa節點産生記憶體交錯(interleave),以滿足額外記憶體的請求,因為本地numa節點無法提供這些記憶體。圖中使用紅色箭頭标示了記憶體交錯(虛線箭頭展示了這種交錯),以此強調這種類型的記憶體交錯是應當避免的,因為它會嚴重影響性能。
為了計算每個numa節點中可用的ram數量,可以使用公式1-1中的等式。
公式1-1 每個numa節點的ram大小(numa本地記憶體)
例如,如果一個伺服器配置了128gb的ram,并且具有兩個插槽(如圖1-4所示),這表明每個numa的ram是128/2,也就是64gb。這并不完全準确,因為還需要考慮esx的消耗。是以,一個更為精确的估算結果可以由公式1-2得出。這個公式中考慮到了esxi的記憶體消耗(不管伺服器的規模大小,始終是1gb的常量)以及1%的vm記憶體消耗,也就是總可用記憶體的1%。這是一個保守的近似公式,每個vm和工作負載會略有不同,但是這個近似值非常接近于最壞的場景。
公式1-2 基于esxi的消耗進行調整後,每個numa節點的ram(numa本地記憶體)
以下描述了公式的不同組成部分:
numa本地記憶體:實作最優記憶體吞吐和查找定位的本地numa記憶體量,已經考慮到了vm和esxi 的消耗。
主機上的ram總量:實體伺服器上所配置的實體ram數量。
nvms:在vsphere主機上所規劃部署的vm數量。
1gb:運作esxi所需要的記憶體消耗。
插槽數:實體伺服器上可用的插槽數,2個插槽或4個插槽。
公式1-2假設的是最為悲觀的開銷範圍,尤其當vm的數量增加的時候,顯然你增加的vm越多,你就會有更多的消耗。對于較少數量vm的場景,公式1-2的近似值是相當準确的。同時,公式中假設的是沒有過量使用記憶體的情況。這個公式的結果對更大的vm更為有利,在這種情況下,numa是最重要的考量内容。當劃分為更大的vm時,一般來講你會維護更少數量要配置的vm,是以這個開銷公式完全适用。實際上,對較大的vm來講,它們具有依賴記憶體的工作負載,其最佳的配置是每個numa節點對應一個vm。如果你将這個公式應用到超過6個vm的部署環境,比如說10個vm,那麼這個公式會過高估算所需的消耗量。更為精确的做法是,你可以使用6%規則,也就是不管vm的數量多少,總是假設6%的記憶體消耗是足夠的,而不用關心是10個vm還是20個vm。
如果你沒有時間來了解公式,而是想快速開始進行配置,那麼可以将記憶體的大約6%作為消耗。有很多的場景,并不是所有的計算方式都會被用到。例如:
樣例1—使用6%估算方式:這表明如果你有一個具備128gb實體ram的伺服器(雙插槽的主機,每個插槽上有8個核心),并且在配置主機上的2個vm時,采用6%消耗的計算方式,那麼每個vm總的numa本地記憶體将會是=> ((128 0.94) – 1) / 2 => 59.7gb。因為有2個vm,那麼提供給這2個vm的記憶體大約是59.7 2 => 119.32gb。
你也可以采用公式1-2的方式,如下面的樣例2所示:
樣例2—使用公式1-2來計算numa本地可用記憶體:同樣,我們假設有一個具有雙插槽(每個插槽上有8個核心)且128gb的主機,要在上面配置2個vm,numa本地記憶體= (128-(128 2 0.01)-1)/ 2 => 62.22gb。注意,這是針對2個vm進行的計算。假設你想配置16個具有單個vcpu(1vcpu = 1個核心)的vm,那麼numa本地記憶體=(128-(128 16 0.01)-1) / 2 => 53.26gb。這很可能過于保守了,更為精确的應該是6%消耗估算方式。
對于最佳實踐,估算消耗最好的方式是總實體ram的6%(再加上esxi所需的1gb),也就是如樣例1所示。
在前面的例子中,展現的計算過程是基于一個具有128gb ram的伺服器,真正的本地記憶體可能是((128 * 0.99)-1gb) / 2 => 62.86gb,這是你可以配置的最大的vm。在這種場景下,你可以非常安全地配置2個具有62.68gb ram的vm,每個vm具有8個vcpu,因為每個vm都會部署到一個numa節點上。還有另外一種可行的選擇,如果你願意部署更小的vm,那麼你可以部署4個vm。每個vm具有62.86gb / 2 => 31.43gb的ram以及4個vcpu,numa的排程算法依然會将vm放置到本地numa節點之上。
在超線程(hyperthreaded)的系統中,vm所具有的vcpu數量大于numa節點内實體核心的數量,但是會小于邏輯處理器的數量(邏輯處理器通常是實體核心數量的2倍,但更為實際的做法是,讓邏輯處理器的數量是實體核心的1.25倍),每個實體numa節點上的這些vm可能會從使用本地記憶體的邏輯處理器中受益,而不是全部的核心都使用遠端的記憶體
為了進一步詳細闡述esxi numa排程算法,圖1-5展現了具有雙插槽且每個插槽6核心的伺服器。
https://yqfile.alicdn.com/c73b33529ed1ac6b0ac86bdcc659e90ea6d1bfce.png" >
在這個圖中,最初有4個vm,每個vm有2個vcpu以及大約20gb的ram。最初的esxi排程算法将會遵循輪詢(round-robin)的模式。首先,會發生第一步(如圖中帶有數字1的黑色圓圈),然後,接下來2個vcpu的vm會在另一個可用的空numa節點上排程,随後同樣的方式(第三步和第四步)排程第三個和第四個vm。此時,4個2vcpu 20gb vm都已經排程過了,排程的結果就是4個vm将會占用每個插槽的4個核心,如圖中的紅針所示(紅針就是最初esxi排程4個2vcpu vm的結果)。稍後,部署了第五個vm,它具有4vcpu以及40gb ram,現在,esxi會試圖在一個numa節點上排程這個vm。這是因為這個vm是4vcpu,并不會被認為是跨numa節點的vm,是以它的全部4個vcpu會被安排在一個numa節點上,盡管此時隻有2個vcpu是可用的。按照numa的平衡感覺算法(balancing awareness algorithm),可能會發生的事情是:esxi排程器将會最終強制要求其中一個2vcpu vm遷移到另外一個numa節點上,進而試圖将第五個4vcpu vm放置到一個numa節點上。esxi排程器采用這種行為是因為它使用一種被稱為numa用戶端的理念,會以每個numa用戶端的方式排程vm,在這裡numa用戶端的預設大小就是實體numa節點的大小。在本例中,預設值就是6,是以任何6vcpu或更小的vm将會排程到一個numa節點上,因為它屬于一個numa用戶端。如果你想改變這種行為,應該強制要求numa用戶端的計算更為細粒度。numa用戶端的計算是通過numa.vcpu.maxperclient控制的,它可以通過advanced host attributes -> advanced virtual numa attributes進行設定,如果你将其值修改為2,那麼在我們的樣例中,每個插槽會有3個numa用戶端,每個2vcpu的vm将會排程到一個numa用戶端之中,而第五個4vcpu vm的排程将會跨2個numa用戶端,如果需要的話,它可能會跨2個插槽。你很少需要進行這種級别的調優,但是這個例子闡述了vsphere中numa算法的強大之處,在這一點上遠超過任何非虛拟化的java平台。
通常,當虛拟機啟動時,esxi會為其配置設定一個home節點,這是其初始安置(initial placement)算法的一部分。虛拟機隻能運作其home節點上的處理器,它新配置設定的記憶體也來自于home節點。除非虛拟機的home節點發生了變更,否則它隻會使用本地記憶體,這就避免了遠端通路其他numa節點所帶來的性能損耗。當虛拟機啟動時,它會配置設定一個初始home節點,這樣numa節點間整體的cpu和記憶體負載就能保持平衡。鑒于在大型numa系統中,跨節點所造成的延遲會有很大的差異,是以esxi會在啟動的時候來确定這些節點間的延遲,并且在安置大于nvma節點的虛拟機時會用到這些資訊。這些更大的虛拟機放置到多個numa節點上,這些節點彼此接近,進而達到最低的記憶體通路延遲。隻進行初始安置時設定(initial placement-only)的方式對于隻運作一個工作負載的系統來說足夠了,比如基準配置在系統的運作過程中保持不變的情況。但是,對于資料中心級别的系統來說,這種方式無法保證達到好的性能和公平性,因為這種級别的系統要支援工作負載的修改。是以,除了初始化安置過程以外,esxi 5.0确實也提供了在numa節點間動态遷移虛拟cpu和記憶體的功能,進而提高cpu的平衡性并增強記憶體的本地化。esxi結合了傳統的初始安置方式以及動态重平衡的算法。系統會階段性(預設每兩秒鐘)檢查各種節點的負載并确定是否要通過将虛拟機從一個節點遷移到另一個節點以實作負載的重平衡。
這個計算會考量到虛拟機的資源設定和資源池來提升性能,而不會違反公平性和資源的權限設定。重平衡器會選擇合适的虛拟機并将其home節點修改為負載最小的節點。如果它能做到這一點,重平衡器會将已經具有一些記憶體的虛拟機轉移到目标節點上。從這一刻開始,虛拟機會在其新的home節點上配置設定記憶體,虛拟機的運作也會依賴于新home節點中的處理器。重平衡是維護公平性并確定所有節點完全使用的有效方案。重平衡器可能需要将虛拟機遷移到一個配置設定了很少甚至沒有記憶體的節點上。在這種情況下,虛拟機會引起性能損耗,這與大量的遠端記憶體通路有關。esxi可以消除這種損耗,這是通過透明地将記憶體從虛拟機的原始節點遷移到新home節點實作的。
在vsphere 4.1/esxi 4.1中,hypervisor并沒有将底層的實體numa架構暴露給作業系統,是以運作在這種vm上的應用程式工作負載并不能充分利用額外的numa挂鈎(hook)所提供的優勢。但是在vsphere5中,引入了vnuma的理念,通過配置你可以暴露底層的numa架構給作業系統,是以能夠感覺numa的應用就能充分使用它了。在java中,可以使用-xx:+usenuma這個jvm參數,但是,它隻相容于吞吐型的gc,而不相容cms gc。沖突的是,在大多數記憶體敏感的應用中,numa是重要的因素,而延遲敏感也是很大的考量因素,是以cms收集器更為合适。這表明你不能同時使用cms與-xx:+usenuma可選項。而好消息是vsphere numa算法對于提供本地化來講已經足夠好了,尤其是當你遵循numa規模劃分最佳實踐時更是如此—如在記憶體和vcpu方面,使vm的規模大小适應numa的邊界。
1.3.3 在生産環境中,最為常見的jvm規模
前面已經讨論了你可以部署的各種jvm規模(在一些場景中,是非常大的jvm),但是要記住的很重要的一點就是,在資料中心裡面,堆大小為4gb的jvm最為常見。這可能是相當繁忙的jvm,具有100~250個并發線程(實際上的線程數可能差異很大,因為這取決于工作負載的特性),4gb的堆大小,那麼jvm程序大約是4.5gb,再加上0.5gb的guest作業系統,是以該vm推薦的預留記憶體是5gb,這個vm具有兩個vcpu且隻包含一個jvm程序,如圖1-6所示。
https://yqfile.alicdn.com/dec7d5724a05e7cd56543600c27a691adf276a07.png" >
1.3.4 jvm和vm的水準擴充與垂直擴充
當考慮水準擴充與垂直擴充時,你可以有3種可選方案,如圖1-7所示。
下面的章節會詳細介紹這3種方案的利弊。
方案1
在方案1中,jvm引入java平台中是通過建立新的vm并在上面部署新的jvm實作的(是以,橫向擴充vm和jvm的模型)。
方案1的優勢
這種方案提供了最佳的可擴充性,因為vm和jvm會作為一個整體單元被esxi排程器所排程。實際上esxi排程的是vm,但因為這個vm上隻有一個jvm,是以造成的實際效果就是vm和jvm會作為一個整體進行排程。
這種方案也提供了最佳的靈活性,能夠獨立地關閉任何vm和jvm而不會影響java平台的其他部分。但毫無疑問這是相對而言,因為大多數java平台都是可水準擴充的,即便jvm執行個體被關閉,也會有足夠的執行個體來服務于通路流量。更多的執行個體會有更好的可擴充性,這種相對的比較基于完全相同的系統使用100個jvm和vm還是150個jvm和vm。對某一個特定執行個體,如果你正在比較和對比平台設計方案并試圖在使用100個jvm還是150個jvm中做出選擇,不管是100個還是150個jvm都具有相應的ram總量。很明顯,具有150個jvm的系統具有更好的靈活性和可擴充性。在150個jvm的場景中,因為你有更多的jvm,是以相對于100個jvm的情況,jvm可能會更小。在這種情況下,如果150個jvm平台中的某一個jvm遇到了問題,所造成的影響可能會更小,因為這個jvm所持有的資料比100個jvm場景所持有的資料更少。是以,150個jvm橫向擴充的健壯性使其成為更為合适的可選方案。
如果系統進行了精化(refined),之前所提到的水準可擴充的優勢就能得以發揮了。這裡的精化指的是基于64位的架構采用vm和jvm的最佳實踐,jvm具有較為合理的大小,也就是大緻4gb的最小堆空間,而不是圍繞着32位jvm所形成的碎片化的1gb堆空間(有一些遺留的32位jvm能夠大于1gb,但是對于實際使用來講,32位jvm會有一個遺留的1gb限制)。
方案1的劣勢
這種方案的成本會更為昂貴,因為它會導緻更多的作業系統副本,許可證費用很快就會變得更為高昂。管理這種系統的成本也會更高,因為需要監控更多的vm和jvm。
并沒有什麼技術原因強制要求你每個vm上面隻放一個jvm。唯一的例外情況是記憶體資料庫系統(如第2類工作負載),這類系統需要從本地numa節點上獲得高吞吐量的記憶體。在這種情況下,vm的大小需要進行調整以便安裝在一個numa節點之内并且上面隻安裝一個jvm。另外,還要注意記憶體資料庫中的jvm通常會相當大,有時會達到128gb,這與第1類工作負載中jvm的大小(一般是1~4gb的堆空間)截然不同。方案1對于第1類工作負載(本章前文進行了定義)是很重要的,但是你也會有很多的機會去合并jvm,進而消除浪費的jvm和vm執行個體。
對遺留的32位jvm來說,這是一種通用的模式,在這種情況下,32位jvm的1gb限制會要求java平台的工程師安裝更多的jvm執行個體,以處理不斷增長的請求流量。這裡的缺點在于你需要支付額外的cpu/許可費用。如果你将jvm遷移為64位,同時增加堆空間的大小,你可以用更少的jvm服務于相同數量的網絡流量,是以會帶來成本的節省。當然,jvm的大小會随着增長,比如從1gb增長到4gb。
方案2
方案2涉及通過合并較小的jvm縱向擴充jvm的堆大小,同時也會形成合并的vm。
方案2的優勢
采用方案2的優勢如下:
因為jvm和vm的數量更少,是以減少了管理的成本。
因為作業系統副本的數量會更少,是以降低了許可證的費用。
因為更多的事務(更可能)在同一個堆空間内執行,而不用跨網絡通路其他jvm時所需的排列(marshaling),是以改善了響應時間。
降低了硬體的成本。
如果你檢視一下圖1-7中的方案2,它展示的2個jvm(jvm-1a與jvm-2a)是由方案1中的4個jvm(jvm-1、2、3和4)合并而成。在這個過程中,如圖所示,4個vm也被合并成了2個vm。例如,如果jvm-1、2、3和4的堆大小都是2gb,每個jvm都運作在具有2vcpu的vm上,這意味着所有jvm中服務于堆的ram也就是服務于應用的ram總和是8gb。所有vm的vcpu數量是8。現在,合并為2個vm和2個jvm時,在方案2中jvm(jvm-1a與jvm-2a)每個都是4gb的堆空間,總計是8gb,每個vm上有2個vcpu。這表明2個vm上一共有4個vcpu,節省了4個vcpu,因為在最初的方案1中,4個vm都具有2個vcpu。
還可能減少vcpu,同時依然保持相等數量的ram(jvm堆空間),因為對于更大的jvm堆空間,gc可以非常好地進行垂直擴充而不會過多消耗cpu。這很大程度上依賴于工作負載的行為,有一些工作負載确實會随着jvm的擴充而增大cpu的使用。但是,大多數第1類工作負載表現出的行為是當合并為更大的jvm堆時,可以釋放不必要的vcpu。64位jvm是功能很強的運作時容器,盡管啟動時會有一些初始成本,但是它們的确可以在更大的堆空間中處理大量的事務。當你考慮建立新的jvm時,同時你會問是否要建立新vm這樣的問題。如果有人需要添加新的vm,vsphere管理者通常會問為何需要它。因為jvm是具有較強能力的機器(正如vm是具有很強能力的計算資源一樣),vsphere管理者和devops工程師通常都會仔細檢查建立新的jvm是否是必要的(而不是采納合理地利用已有的jvm執行個體,為其增加堆空間以應對更大的流量的方案)。
方案2的劣勢
使用方案2的劣勢如下:
因為使用了更大的jvm,如果發生jvm崩潰而沒有恰當地進行備援或持久化事務,你會有失去更多資料的風險(相對于方案1中的更小的jvm)。
因為合并,可能會有更少高可用性(high-availability,ha)的jvm執行個體。
合并會局限于業務線。你并不想将來自不同業務線的應用混合到同一個jvm之中。如果你将兩個業務線的應用放到了同一個jvm中,那麼如果這個jvm崩潰,将會同時影響到這兩個業務線。
更大的jvm可能會需要更多的gc調優。
方案3
如果方案1和方案2都是不可行的,那麼考慮方案3。在這種情況下,你在一個更大的vm上部署了多個jvm。現在,jvm-1b和jvm-2b可以是合并後的jvm副本,如方案2中的那樣,也可以是沒有合并前的副本,如方案1中那樣。不管是哪種情況,你都可以将這些jvm堆積(stack)到一個或多個更大的vm之中。
方案3的優勢
使用方案3的優勢如下:
如果目前的平台與方案1類似,那麼這種方案可能會有一定的優勢,鑒于維護的原因,保持目前數量的jvm在部署環境中的完整性,然後再去考慮更大的vm,讓多個jvm堆積到上面。
減少作業系統許可證的數量。
減少vm執行個體的數量。
因為更少的vm,是以減少了管理成本。
你可以為每個業務線建構專用的jvm,也可以部署多個業務線的jvm到同一個vm上。隻有vm合并的成本節省大于某一個vm崩潰給多個業務線所帶來的影響時,你才應該選擇這種方案。
大的vm可以為jvm配置更多的vcpu。如果vm上有兩個來自不同業務線的jvm,例如,它們的高峰期在不同的時間段,那麼繁忙的jvm就有可能使用所有的vcpu,當另一個jvm到達通路高峰時也會發生類似的事情。
方案3的劣勢
較大的vm很可能是必需的,但是相對于小的vm,排程更大的vm需要更多的調優。
各種性能案例顯示,對于第1類工作負載來說,最恰當的vm規模是2~4個vcpu,而對于第2類的工作負載,會需要多于4個vcpu,或者說最少4個vcpu。不過,從ha的角度來看,會消除排程的機會。但需要記住的是,作為記憶體資料庫的第2類工作負載很可能需要容錯、備援以及磁盤持久化,是以不會那麼依賴于vmware ha以及自動化的分布式資源排程(distributed resource scheduler,drs)。
因為這種方案會試圖合并vm,那麼很可能不同業務線的jvm會部署到相同的vm之中。你必須要正确地對其進行管理,因為無意中對某個虛拟機進行重新開機可能會影響到多個業務線。
你可以将jvm進行合并,然後将其堆積到同一個vm上。但是,這就要求jvm要足夠大才能完全使用底層的記憶體。如果你配置少量的更大的vm,那就意味着你的vm會有更多來自于底層硬體的ram,為了充分使用這些ram,你可能會需要更大的jvm堆空間。因為jvm的規模更大一些,是以當jvm崩潰時,如果你沒有進行适當備援和持久化事務,那麼你會失去更多的資料。
這種方案可能會需要大型的vsphere主機和更大的伺服器,是以成本會更高。