本節書摘來自華章出版社《高并發oracle資料庫系統的架構與設計》一書中的第2章,第2.1節,作者 侯松,更多章節内容可以通路雲栖社群“華章計算機”公衆号檢視
如果把我們的資料庫比喻成一座圖書館,那表作為資料的載體,則是一本一本的圖書,而索引則是圖書的目錄。目錄不僅讓圖書閱讀和查找變得友善,更是圖書成敗的關鍵。
也許有人會說,我翻閱的是一本雜志,内容本就不多,我甚至不需要目錄。是的,oracle資料庫也考慮到了這一點,對于資料量很小的表,我們可以不建索引,在查詢時可以進行全表掃描(full table scan),這種方式對于小表來說更适合。但是,如果我們手上是一本大字典呢?你甚至一個人都搬不動它,當然你也不必像看雜志一樣每頁都去翻閱,隻需要查詢到真正需要的内容即可。這個時候我們就需要目錄了,甚至是多樣類别的目錄,比如:拼音目錄、部首目錄等,這樣我們可以根據不同的需求選擇不同的目錄。同樣,oracle資料庫也為不同的查詢者提供了不同類别的索引,最常用的也是預設的索引就是接下來要說的b樹索引。
b樹索引的掃描就像目錄的翻閱,高效的掃描方式才能帶來快速的資訊擷取,本節将給讀者介紹b樹索引的幾種常見掃描方式。
在正式開始之前,我們先來介紹一下什麼是b樹索引。顧名思義,b樹索引是一種樹形結構的資料庫對象,它由根節點、分支節點、葉節點三部分組成。如圖2-1所示,根節點存儲着指向分支節點的指針,分支節點則存儲着指向葉節點的指針,索引的條目最終是存儲在各個葉節點上的。根節點和分支節點一方面是作為索引條目快捷的資料路由,另一方面也是通過算法将索引條目分布均勻。
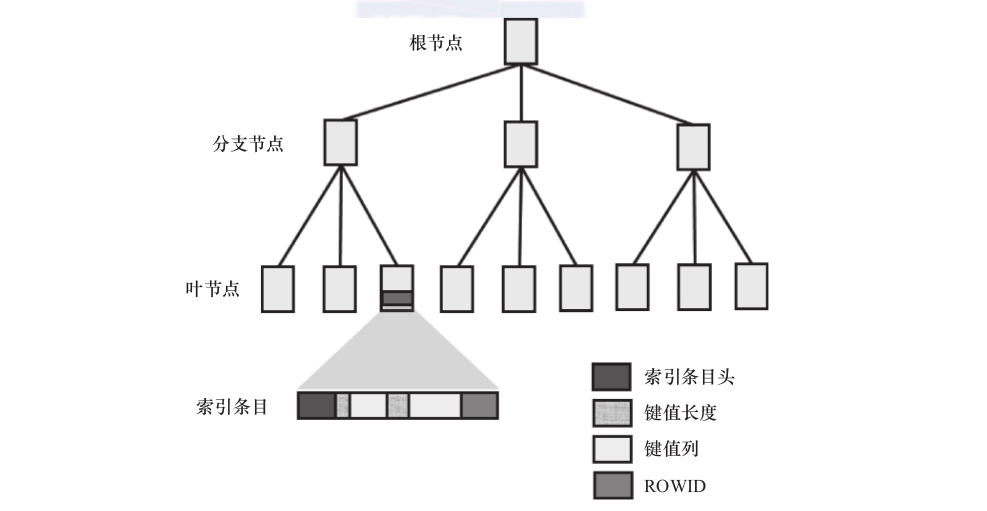
我們說過索引就像表的目錄,那目錄條目會有哪些内容呢,其中我們最關心的是什麼呢?毋庸置疑,我們最關心的必是對應章節的開始頁碼。在b樹索引的葉節點索引條目中也包含了這個頁碼——rowid,它指明了對應資料實際存儲的實體位置,也是我們進行索引掃描的目的。
說到索引掃描,不得不提的就是全表掃描(full table scan)了,因為在一定程度上,引進索引掃描就是為了取代全表掃描。
全表掃描(full table scan)就是在資料查詢過程中,對整張表的全部低于高水位标記(high water mark,hwm)的資料塊(data block)進行讀取。如圖2-2所示,可以說單次查詢需要讀取全表的資料,對于小表來說,這是無可厚非的,甚至可能是最優的方式。但如果是一張資料量較大的表,這将導緻很多非必要的資料塊讀取,造成過多的i/o開銷。
從另一方面來講,判斷一次索引掃描是否高效的标準就是将其與全表掃描進行比較,如果較之成本更低,那麼索引掃描可以被視為高效的,反之則是需要優化的。

通過一個例子來簡單對比一下吧。從傳回結果來看,表alex_t00有10萬行記錄,不算一個小表了,執行計劃的成本開銷(cost)中,全表掃描cost=84,而索引掃描cost=44,全表掃描的執行效率是非常低的。兩種掃描的效率對比如下所示:
全表掃描,對于小表來說是最優選擇,對于沒有合适的索引的大表來說,也是不錯的選擇。
我們已經了解到rowid其實就是索引的“頁碼”,它是oracle提供的僞列,一般說來每一行資料都對應一個固定且唯一的rowid,在這一行資料存入資料庫的時候就确定了。rowid掃描查詢示例如下所示:
從上面這個查詢例子可以看到,rowid是基于64位編碼的18個字元顯示,它記錄了資料對象的編号、檔案編号、塊編号、行編号,即資料行存儲的實體位置,如表2-1所示:
利用rowid來查詢記錄,其實就是根據資料行實際存儲的位置來擷取資料。通過rowid查詢記錄是查詢速度最快的查詢方法,比任何索引掃描方式都要快速。為什麼這麼說呢?我們說索引掃描實質上可以分解成兩個動作:
索引結構掃描,擷取待傳回資料行的rowid;
根據擷取的rowid掃描表,擷取對應資料行,并傳回。
rowid的掃描方式其實就是索引掃描的第二個動作,換而言之,索引掃描的目标就是通過rowid掃描的方式從表中擷取查詢資料行。
通過dbms_rowid這個包,可以直接得到具體的rowid所包含的資訊:
rowid掃描方式是查詢取數最快的方式,索引檢索的本質也是轉換為rowid掃描取數。
從上面的介紹,我們可以了解到索引掃描的過程其實是掃描索引結構擷取rowid的過程。索引唯一掃描(index unique scan)隻能發生在唯一鍵索引(主鍵索引實質即為唯一鍵索引)上,通過唯一索引查找數值往往傳回單個rowid,如圖2-3所示,從索引的根(root)節點到枝(branch)節點,再到葉(leaf)節點上存儲着一個對應的rowid,即對應的查詢結果也隻傳回一行,這種存取方法稱為“索引唯一掃描”。如果該唯一索引是由多個列組成的組合索引,則至少要有組合索引的前導列參與到該查詢中,同樣sql語句隻傳回一行記錄,這也屬于索引唯一掃描。
下面通過一些執行個體來了解一下該掃描方式的特點。在正式開始之前,我們需要做一點準備工作:
步驟1 建立一下相關的表和主鍵索引:
步驟2 初始化資料,順序地插入10萬行資料:
步驟3 最重要的是收集一下表和主鍵索引的統計資訊和直方圖資訊(預設開啟直方圖收集),在缺失統計資訊和直方圖的情況下,cbo優化器可能無法正确地計算sql語句的執行成本,直接導緻執行計劃跑偏,影響性能:
sql> exec dbms_stats.gather_table_stats('alex','alex_t01')
sql> exec dbms_stats.gather_index_stats('alex','pk_alex_t01')
準備工作完成後,可以實際執行一下查詢sql語句,進行如下所示的驗證。
我們看到查詢篩選條件為id=400,是一個等值查詢,傳回唯一資料行,執行計劃走的是索引唯一掃描方式。
如果這裡不是等值查詢呢?那麼,執行計劃将無法按索引唯一掃描方式。換而言之,有且僅當唯一鍵索引列上發生等值查詢時,才會觸發索引唯一掃描,傳回單行資料。這種索引掃描方式也是最高效的索引掃描方式,常見于主鍵索引的應用場景。
我們也可以通過給sql語句添加hint關鍵字的方式,改變執行計劃,強制sql語句走索引掃描,如下所示:
索引唯一掃描是最高效的索引掃描方式,其隻對唯一鍵索引上的等值查詢有效。
在索引的使用過程中,更多的情況是傳回多個資料行。當使用一個索引存取多行資料時,這種索引掃描方式稱為“索引範圍掃描”(index range scan)。與索引唯一掃描不同,索引範圍掃描可以發生在唯一鍵索引上,也可以發生在非唯一鍵索引上。
哪些情況會發生索引範圍掃描呢?
在唯一索引列上使用了範圍操作符(如:>、<、<>、>=、<=、between,即不等值查詢);
對非唯一索引列上進行的查詢。
先來看看第一種情況,在主鍵索引列上進行非等值查詢,篩選條件為id<4,傳回了3行資料,此時的執行計劃走的不是索引唯一掃描了,而是索引範圍掃描,如下例所示:
再來測試一下第二種情況,為表alex_t01追加一個單列索引和一個組合索引,并收集相關統計資訊和直方圖:
sql> create index idx_alex_t01_id_ab on alex_t01 (a, b);
sql> create index idx_alex_t01_id_c on alex_t01 (c);
sql> exec dbms_stats.gather_index_stats('alex','idx_alex_t01_id_ab')
sql> exec dbms_stats.gather_index_stats('alex','idx_alex_t01_id_c')
在非唯一鍵索引idx_alex_t01_id_c的索引列c上進行查詢,其執行計劃走的是索引範圍掃描。而在普通索引上的查詢,不論是否等值查詢,也不論傳回的資料行數是多少,其執行計劃均為索引範圍掃描。索引範圍掃描示例如下所示:
我們也可以通過給sql語句添加hint關鍵字的方式,改變執行計劃,強制sql語句走索引範圍掃描,如下所示:
當發生索引範圍掃描的時候,對索引列有一個自動排序操作,預設情況下是正序(asc)輸出傳回的結果集的,也就是index range scan asc。對于本例來說,以下兩句sql語句是等效的:
如果在sql語句中要求反序排序輸出結果集呢?索引排序具體内容将在接下來的章節展開。
索引範圍掃描是最常見的一種索引掃描方式,在做優化時,需要盡可能使用的一種方式。
對于表來說,有全表掃描,同樣對于索引來說,也是存在索引全掃描的。索引全掃描(index full scan)與全表掃描是非常類似的,如圖2-5所示,它将先掃描索引全部節點和條目,再選擇對應資料進行排序輸出。索引全掃描隻在cbo模式下才有效。cbo根據統計數值得知進行索引全掃描比進行全表掃描更有效時,才進行索引全掃描,而且此時查詢出的資料都必須從索引中可以直接得到。
一般來說哪些情況會使用到索引全掃描呢?
表和表進行排序合并聯立(sort-merge join)查詢的時候,排序的列必須是存在于索引中的;
查詢中有order by和group by子句的時候,子句中所有的列是必須存在于索引中的。
下面是一個簡單索引全掃描的例子:
我們也可以通過給sql語句添加hint關鍵字的方式,改變執行計劃,強制sql語句走索引全掃描,如下所示:
與全表掃描相比,索引全掃描的優勢在哪裡呢?
全表掃描過程是不進行排序的,必須将資料全部取出後再進行排序輸出,其掃描目标表hwm下所有資料塊,包括沒有必要的空塊。
因為索引結構本身就是一個有序的結構,索引全掃描在周遊索引的同時就已經完成了排序操作,在輸出結果的時候是不需要再排序的,再者其通過rowid擷取行資料,避免了空塊的讀取。
索引全掃描過程是單塊讀取,其不支援多塊并行的讀取,輸出結果是有序排列的。
索引快速全掃描(index fast full scan)是掃描索引中的所有資料塊,與index full scan很類似,最顯著的差別就是它不對查詢出的資料進行排序,即資料不是以排序順序被傳回。在這種存取方法中,可以使用多塊讀功能,也可以使用并行讀,以便獲得最大吞吐量并縮短執行時間。
看一看下面的例子,複合索引idx_alex_t01_id_ab的索引列為(a,b),查詢的傳回列a,b都包含在索引列上,這個時候的取數操作直接就能在索引上完成了,不需要再根據rowid去表中取數了,而且沒有排序的需求。這時執行計劃走的就是index fast full scan的操作了。
當我們取count(*)的時候,同樣是不關心順序的,也不需要排序操作,該查詢隻需要統計索引葉節點上的索引條目數量就可傳回結果了,index fast full scan是一個非常好的選擇。在下面的執行計劃示例中,我們可以看到,sort aggregate操作是沒有意義的,因為排序行數隻有1行。
我們也可以通過給sql語句添加hint關鍵字的方式,改變執行計劃,強制sql語句走索引快速全掃描,如下所示:
再來對比一下索引全掃描和索引快速全掃描,如表2-2所示:
索引跳躍掃描(index skip scan)是oracle 9i引進的一個新特性,其發生在複合索引上,如果sql語句中where子句隻包含索引中的部分列,且這些列不是索引的第一列,就可能發生index skip scan。如果在查詢時,第一列沒有被指定,就跳過它。
index skip scan除了需要cbo,并且對表進行過分析外,還需要保證第一列的distinct值非常小。oracle會對複合索引進行邏輯劃分,分為多個子索引,可以了解為索引從邏輯上被劃分為第一列distinct值的數量的子索引,每次對一個子索引進行掃描。
下面通過一個例子來分析一下,在表alex_t01上,有一個複合索引idx_alex_t01_id_ab,索引列為(a,b),查詢一下該表a列的distinct值的數量為2,即隻有“0”和“1”兩個鍵值,是滿足了先決條件的。
再進行一次index skip scan類型的查詢,示例如下所示:
但是,換一個角度來思考,我們會在設計索引的時候設計一個前導列區分度極低的複合索引嗎?一般情況下,我們是不會這麼做的。這又意味着什麼呢?這意味着在執行計劃中,如果看到index skip scan,其cost開銷将會非常大的,反而成了我們需要優化的對象。
在複合索引設計中,盡可能選擇區分度較大的列作為前導列。如果為了使用index skip scan這個索引掃描方式而選擇區分度極低的列作為前導列,就是本末倒置了。
如果一個查詢語句中,where子句包含兩個篩選條件,這兩個條件都有其單獨的索引,我們是不是可以同時使用兩個索引呢?答案是肯定的。我們可以通過兩個獨立的索引分别掃描,再組合起來。在oracle早期的版本中,我們可以通過and_equal方式來實作。從oracle 10g開始,and_equal方式已經被廢棄,由index_combine方式取而代之。
索引組合(index combine)最早是出現在位圖索引上的,從oracle 9i開始,預設可以使用在b樹索引上,這個特性是由隐藏參數_b_tree_bitmap_plans來控制的。oracle将b樹索引中獲得的rowid資訊通過bitmap conversion from rowids的步驟轉換成位圖進行比對,完成後通過bitmap conversion to rowids再轉換出rowid獲得資料或者回表獲得資料。
通過一個例子來看一下吧。在開始之前,我們需要修改一下表alex_t01上的索引,我們需要删除掉組合索引idx_alex_t01_id_ab,為b列建立一個單列索引idx_alex_t01_id_b,并重新收集統計資訊。sql語句如下:
此時,b列和c列都有了其獨立的單列索引,且此兩列區分度都較高。我們再來做一次基于b列和c列的組合查詢試試:
如果你因為看到bitmap conversion的字樣而感到擔憂的話,那大可不必,這部分的cost基本可以忽略,這是一個典型的index_combine例子。
我們要是強制查詢隻走其中一個索引呢,情況會如何呢?看一個示例:
從上例可以看到,不論是走b列的索引還是走c列的索引,其cost開銷都不如index_combine方式更優。
換而言之,如果我們知道索引組合掃描的方式會更優,也可以通過給sql語句添加hint關鍵字的方式,改變執行計劃,強制sql語句走索引組合掃描,示例如下所示:
2.1.9節說到,若一個查詢語句中,where子句包含兩個都有單獨的索引篩選條件,則我們可以用index_combine掃描的方式來進行優化,但是index_combine仍然是需要有回表取數的操作。如果我們查詢傳回的列都包含在該兩個索引中,我們就可以不用回表取數了,直接通過兩個索引的hash join來完成就可以了。這個時候需要用另一個索引相關的hint關鍵字index_join。
通過下面的例子來看一下,cbo優化器更傾向于cost更低的index_combine掃描,強制執行計劃走index_join掃描,cost較index_combine掃描要高一些,但是相對單一索引的使用來說,卻是有優勢的。
嚴格意義上講,index_combine和index_join都不能算是一種獨立的索引掃描方式,它們是對現有五種索引掃描方式的優化和補充,使其獲得更好的性能優勢。
index combine和index join掃描方式各自有其适用場景,合理的使用索引組合和索引聯立會帶來性能的大幅提升。
如果索引結構設計比較合理,則能在索引掃描過程中完成取數的操作,盡量在索引掃描中完成,避免回表取數的開銷,這個技巧叫做索引覆寫應用(index covering),它覆寫了查詢的所有字段(select、 where、 order by、group by),用來提高查詢的效率。
縱觀各種索引掃描方式的介紹和分析,每種掃描方式都有其特點和适用場景,不能單純地說哪種掃描方式更優。在優化的工作中,更不能簡單地用某種掃描方式去替代另一種掃描方式,我們需要分析清楚具體的應用場景,根據業務需求選擇合适的索引掃描方式。
如果統計資訊和直方圖收集得準确的話,cbo優化器會提供準确的cost開銷估算,可以作為索引掃描方式選擇的參考。在實際優化的工作中,我們往往不能獲得足夠準确的統計資訊和直方圖資訊,就需要通過比較不同索引掃描方式下,sql語句執行的響應時間來判斷。