本節書摘來華章計算機《計算機網絡:自頂向下方法(原書第6版)》一書中的第1章 ,第1.3節,(美)james f.kurose keith w.ross 著 陳 鳴 譯 更多章節内容可以通路雲栖社群“華章計算機”公衆号檢視。
在考察了網際網路邊緣後,我們現在更深入地研究網絡核心,即由互聯網際網路端系統的分組交換機和鍊路構成的網狀網絡。圖1-10用加粗陰影線勾畫出網絡核心部分。
在各種網絡應用中,端系統彼此交換封包(message)。封包能夠包含協定設計者需要的任何東西。封包可以執行一種控制功能(例如,圖1-2所示例子中的“你好”封包),也可以包含資料,例如電子郵件資料、jpeg圖像或mp3音頻檔案。為了從源端系統向目的端系統發送一個封包,源将長封包劃分為較小的資料塊,稱之為分組(packet)。在源和目的之間,每個分組都通過通信鍊路和分組交換機(packet switch)(交換機主要有兩類:路由器和鍊路層交換機)傳送。分組以等于該鍊路最大傳輸速率的速度傳輸通過通信鍊路。是以,如果某源端系統或分組交換機經過一條鍊路發送一個l比特的分組,鍊路的傳輸速率為r比特/秒,則傳輸該分組的時間為l/r秒。
1.存儲轉發傳輸
多數分組交換機在鍊路的輸入端使用存儲轉發傳輸(store-and-forward transmission)機制。存儲轉發機制是指在交換機能夠開始向輸對外連結路傳輸該分組的第一個比特之前,必須接收到整個分組。為了更為詳細地探讨存儲轉發傳輸,考慮由兩個經一台路由器連接配接的端系統構成的簡單網絡,如圖1-11所示。一台路由器通常有多條繁忙的鍊路,因為它的任務就是把一個入分組交換到一條對外連結路。在這個簡單例子中,該路由器的任務相當簡單:将分組從一條(輸入)鍊路轉移到另一條唯一的連接配接鍊路。在圖1-11所示的特定時刻,源已經傳輸了分組1的一部分,分組1的前沿已經到達了路由器。因為該路由器應用了存儲轉發機制,是以此時它還不能傳輸已經接收的比特,而是必須先緩存(即“存儲”)該分組的比特。僅當路由器已經接收完了該分組的所有比特後,它才能開始向對外連結路傳輸(即“轉發”)該分組。為了深刻領悟存儲轉發傳輸,我們現在計算一下從源開始發送分組到目的地收到整個分組所經過的時間。(這裡我們将忽略傳播時延——指這些比特以接近光速的速度跨越線路所需要的時間,這将在1.4節讨論。)源在時刻0開始傳輸,在時刻l/r秒,因為該路由器剛好接收到整個分組,是以它能夠朝着目的地向對外連結路開始傳輸分組;在時刻2l/r,路由器已經傳輸了整個分組,并且整個分組已經被目的地接收。是以,總時延是2l/r。如果交換機一旦比特到達就轉發比特(不必首先收到整個分組),則因為比特沒有在路由器保持,總時延将是l/r。而如我們将在1.4節中讨論的那樣,路由器在轉發前需要接收、存儲和處理整個分組。

現在我們來計算從源開始發送第一個分組直到目的地接收到所有三個分組所需的時間。與前面一樣,在時刻l/r,路由器開始轉發第一個分組。而在時刻l/r源也開始發送第二個分組,因為它已經完成了發送整個第一個分組。是以,在時刻2l/r,目的地已經收到第一個分組并且路由器已經收到第二個分組。類似地,在時刻3l/r,目的地已經收到前兩個分組并且路由器已經收到第三個分組。最後,在時刻4l/r,目的地已經收到所有3個分組!
我們現在來考慮通過由n條速率均為r的鍊路組成的路徑(是以,在源和目的地之間有n-1台路由器),從源到目的地發送一個分組的總體情況。應用如上相同的邏輯,我們看到端到端時延是
你也許現在要試着确定p個分組經過n條鍊路序列的時延有多大。
2.排隊時延和分組丢失
每個分組交換機有多條鍊路與之相連。對于每條相連的鍊路,該分組交換機具有一個輸出緩存(output buffer)(也稱為輸出隊列output queue),它用于存儲路由器準備發往那條鍊路的分組。該輸出緩存在分組交換中起着重要的作用。如果到達的分組需要傳輸到某條鍊路,但發現該鍊路正忙于傳輸其他分組,該到達分組必須在該輸出緩存中等待。是以,除了存儲轉發時延以外,分組還要承受輸出緩存的排隊時延(queue delay)。這些時延是變化的,變化的程度取決于網絡中的擁塞程度。因為緩存空間的大小是有限的,一個到達的分組可能發現該緩存已被其他等待傳輸的分組完全充滿了。在此情況下,将出現分組丢失(丢包)(packet lost),到達的分組或已經排隊的分組之一将被丢棄。
圖1-12顯示了一個簡單的分組交換網絡。如在圖1-11中,分組被表示為3維切片。切片的寬度表示了該分組中比特的數量。在這張圖中,所有分組具有相同的寬度,是以有相同的長度。假定主機a和b向主機e發送分組。主機a和b先通過10mbps的以太網鍊路向第一個路由器發送分組。該路由器則将這些分組導向到一條1.5mbps的鍊路。如果在某個短時間間隔中,分組到達路由器的到達率(轉換為每秒比特)超過了1.5mbps,這些分組在通過鍊路傳輸之前,将在鍊路輸出緩存中排隊,在該路由器中将出現擁塞。例如,如果主機a和主機b每個都同時發送了5個緊接着的分組突發塊,則這些分組中的大多數将在隊列中等待一些時間。事實上,這完全類似于每天都在經曆的一些情況,例如當我們在銀行櫃台前排隊等待或在過路收費站前等待時。我們将在1.4節中更為詳細地研究這種排隊時延。
3.轉發表和路由選擇協定
前面我們說過,路由器從與它相連的一條通信鍊路得到分組,将其向與它相連的另一條通信鍊路轉發。但是該路由器怎樣決定它應當向哪條鍊路進行轉發呢?不同的計算機網絡實際上是以不同的方式完成的。這裡,我們簡要介紹在網際網路中所采用的方法。
在網際網路中,每個端系統具有一個稱為ip位址的位址。當源主機要向目的端系統發送一個分組時,源在該分組的首部包含了目的地的ip位址。如同郵政位址那樣,該位址具有一種等級結構。當一個分組到達網絡中的路由器時,路由器檢查該分組的目的位址的一部分,并向一台相鄰路由器轉發該分組。更特别的是,每台路由器具有一個轉發表(forwarding table),用于将目的位址(或目的位址的一部分)映射成為輸對外連結路。當某分組到達一台路由器時,路由器檢查該位址,并用這個目的位址搜尋其轉發表,以發現适當的對外連結路。路由器則将分組導向該對外連結路。
端到端選路過程與一個不使用地圖而喜歡問路的汽車駕駛員相類似。例如,假定joe駕車從費城到佛羅裡達州奧蘭多市的lakeside drive街156号。joe先駕車到附近的加油站,詢問怎樣才能到達佛羅裡達州奧蘭多市的lakeside drive街156号。加油站的服務員從該位址中抽取了佛羅裡達州部分,告訴joe他需要上i-95南州際公路,該公路恰有一個鄰近該加油站的入口。他又告訴joe,一旦到了佛羅裡達後應當再問當地人。于是,joe上了i-95南州際公路,一直到達佛羅裡達的jacksonville,在那裡他向另一個加油站服務員問路。該服務員從位址中抽取了奧蘭多市部分,告訴joe他應當繼續沿i-95公路到daytona海灘,然後再問其他人。在daytona海灘的另一個加油站服務員也抽取該位址的奧蘭多部分,告訴joe應當走i-4公路直接前往奧蘭多。joe走了i-4公路,并從奧蘭多出口下來。joe又向另一個加油站的服務員詢問,這時該服務員抽取了該位址的lakeside drive部分,告訴了joe到lakeside drive必須要走的路。一旦joe到達了lakeside drive,他向一個騎自行車的小孩詢問了到達目的地的方法。這個孩子抽取了該位址的156号部分,并訓示了房屋的方向。joe最後到達了最終目的地。在上述類比中,那些加油站服務員和騎車的孩子可類比為路由器。
我們剛剛學習了路由器使用分組的目的位址來索引轉發表并決定适當的對外連結路。但是這個叙述還要求回答另一個問題:轉發表是如何進行設定的?是通過人工對每台路由器逐台進行配置,還是網際網路使用更為自動的過程進行設定呢?第4章将深入探讨這個問題。但在這裡為了激發你的求知欲,我們現在将告訴你網際網路具有一些特殊的路由選擇協定(routing protocol),用于自動地設定這些轉發表。例如,一個路由選擇協定可以決定從每台路由器到每個目的地的最短路徑,并使用這些最短路徑結果來配置路由器中的轉發表。
怎樣才能實際看到分組在網際網路中所走的端到端路由呢?我們現在請你親手用一下traceroute程式。直接通路站點www.traceroute.org,在一個特定的國家中選擇一個源,跟蹤從這個源到你的計算機的路由。(參見1.4節有關traceroute的讨論。)
通過網絡鍊路和交換機移動資料有兩種基本方法:電路交換(circuit switching)和分組交換(packet switching)。上一節已經讨論過分組交換網絡,現在我們将注意力投向電路交換網絡。
在電路交換網絡中,在端系統間通信會話期間,預留了端系統間通信沿路徑所需要的資源(緩存,鍊路傳輸速率)。在分組交換網絡中,這些資源則不是預留的;會話的封包按需使用這些資源,其後果可能是不得不等待(即排隊)接入通信線路。一個簡單的類比是,考慮兩家餐館,一家需要顧客預訂,而另一家不需要預訂但不保證能安排顧客。對于需要預訂的那家餐館,我們在離開家之前必須承受先打電話預訂的麻煩。但當我們到達該餐館時,原則上我們能夠立即入座并點菜。對于不需要預訂的那家餐館,我們不必麻煩預訂餐桌,但也許不得不先等待一張餐桌空閑後才能入座。
傳統的電話網絡是電路交換網絡的例子。考慮當一個人通過電話網向另一個人發送資訊(語音或傳真)時所發生的情況。在發送方能夠發送資訊之前,該網絡必須在發送方和接收方之間建立一條連接配接。這是一個名副其實的連接配接,因為此時沿着發送方和接收方之間路徑上的交換機都将為該連接配接維護連接配接狀态。用電話的術語來說,該連接配接被稱為一條電路(circuit)。當網絡建立這種電路時,它也在連接配接期間在該網絡鍊路上預留了恒定的傳輸速率(表示為每條鍊路傳輸容量的一部分)。既然已經為該發送方-接收方連接配接預留了帶寬,則發送方能夠以確定的恒定速率向接收方傳送資料。
圖1-13顯示了一個電路交換網絡。在這個網絡中,用4條鍊路互聯了4台電路交換機。這些鍊路中的每條都有4條電路,是以每條鍊路能夠支援4條并行的連接配接。每台主機(例如pc和工作站)都與一台 圖1-13 由4台交換機和4條鍊路組成的
一個簡單電路交換網絡交換機直接相連。當兩台主機要通信時,該網絡在兩台主機之間建立一條專用的端到端連接配接(end-to-end connection)。是以,主機a為了向主機b發送封包,網絡必須在兩條鍊路之一上先預留一條電路。因為每條鍊路具有4條電路,對于由端到端連接配接所使用的每條鍊路而言,該連接配接在連接配接期間獲得鍊路帶寬的1/4部分。例如,如果兩台鄰近交換機之間每條鍊路具有1mbps傳輸速率,則每個端到端電路交換連接配接獲得250kbps專用的傳輸速率。
1.電路交換網絡中的複用
鍊路中的電路是通過頻分複用(frequency-division multiplexing,fdm)或時分複用(time-division multiplexing,tdm)來實作的。對于fdm,鍊路的頻譜由跨越鍊路建立的所有連接配接所共享。特别是,在連接配接期間鍊路為每條連接配接專用一個頻段。在電話網絡中,這個頻段通常具有4khz的寬度(即4000赫茲或每秒4000周)。毫無疑問,該頻段的寬度稱為帶寬(bandwidth)。調頻無線電台也使用fdm來共享88~108mhz的頻譜,其中每個電台被配置設定一個特定的頻段。
對于一條tdm鍊路,時間被劃分為固定區間的幀,并且每幀又被劃分為固定數量的時隙。當網絡跨越一條鍊路建立一條連接配接時,網絡在每個幀中為該連接配接指定一個時隙。這些時隙專門由該連接配接單獨使用,一個時隙(在每個幀内)可用于傳輸該連接配接的資料。
圖1-14顯示了一個支援多達4條電路的特定網絡鍊路的fdm和tdm。對于fdm,其頻率域被分割為4個頻段,每個頻段的帶寬是4khz。對于tdm,其時域被分割為幀,在每個幀中具有4個時隙,在循環的tdm幀中每條電路被配置設定相同的專用時隙。對于tdm,一條電路的傳輸速率等于幀速率乘以一個時隙中的比特數量。例如,如果鍊路每秒傳輸8000個幀,每個時隙由8個比特組成,則每條電路的傳輸速率是64kbps。
分組交換的支援者總是争辯說,電路交換因為在靜默期(silent period)專用電路空閑而效率較低。例如,打電話的一個人停止講話,空閑的網絡資源(在沿該連接配接路由的鍊路中的頻段或時隙)不能被其他進行中的連接配接所使用。作為這些資源被無效利用的另一個例子,考慮一名放射科醫師使用電路交換網絡遠端存取一系列x射線圖像。該放射科醫師建立一條連接配接,請求一幅圖像,然後判讀該圖像,然後再請求一幅新圖像。在放射科醫師判讀圖像期間,網絡資源配置設定給了該連接配接但沒有使用(即被浪費了)。分組交換的支援者還津津樂道地指出,建立端到端電路和預留端到端帶寬是複雜的,需要複雜的信令軟體以協調沿端到端路徑的交換機的操作。
圖1-14 對于fdm,每條電路連續地得到部分帶寬。對于tdm,每條電路在短時間間隔(即時隙)中周期性地得到所有帶寬
在結束讨論電路交換之前,我們讨論一個用數字表示的例子,它更能說明問題的實質。考慮從主機a到主機b經一個電路交換網絡需要多長時間發送一個640000比特的檔案。假如在該網絡中所有鍊路使用24時隙的tdm,具有1.536mbps的比特速率。同時假定在主機a能夠開始傳輸該檔案之前,需要500ms建立一條端到端電路。它需要多長時間才能發送該檔案?每條鍊路具有的傳輸速率是1.536mbps/24=64kbps,是以傳輸該檔案需要(640kb)/(64kbps)=10s。對于這個10s,再加上電路建立時間,這樣就需要10.5s發送該檔案。值得注意的是,該傳輸時間與鍊路數量無關:端到端電路不管是通過一條鍊路還是100條鍊路,傳輸時間都将是10s。(實際的端到端時延還包括傳播時延,參見1.4節。)
2.分組交換與電路交換的對比
在描述了電路交換和分組交換之後,我們來對比一下這兩者。分組交換的批評者經常争辯說,分組交換不适合實時服務(例如,電話和視訊會議),因為它的端到端時延是可變的和不可預測的(主要是因為排隊時延的變動和不可預測所緻)。分組交換的支援者卻争辯道:①它提供了比電路交換更好的帶寬共享;②它比電路交換更簡單,更有效,實作成本更低。分組交換與電路交換之争的有趣讨論參見[molinero-fernandez 2002]。概括而言,嫌餐館預訂麻煩的人甯可要分組交換而不願意要電路交換。
分組交換為什麼更有效呢?我們看一個簡單的例子。假定多個使用者共享一條1mbps鍊路,再假定每個使用者活躍周期是變化的,某使用者時而以100kbps恒定速率産生資料,時而靜止——這時使用者不産生資料。進一步假定該使用者僅有10%的時間活躍(餘下的90%的時間空閑下來喝咖啡)。對于電路交換,在所有的時間内必須為每個使用者預留100kbps。例如,對于電路交換的tdm,如果一個1s的幀被劃分為10個時隙,每個時隙為100ms,則每幀将為每個使用者配置設定一個時隙。
是以,該電路交換鍊路僅能支援10(=1mbps/100kbps)個并發的使用者。對于分組交換,一個特定使用者活躍的機率是0.1(即10%)。如果有35個使用者,有11或更多個并發活躍使用者的機率大約是0.0004。(課後習題p8概述如何得到這個機率值。)當有10個或更少并發使用者(以機率0.9996發生)時,到達的聚合資料率小于或等于該鍊路的輸出速率1mbps。是以,當有10個或更少個活躍使用者時,通過該鍊路的分組流基本上沒有時延,這與電路交換的情況一樣。當同時活躍使用者超過10個時,則分組的聚合到達率超過該鍊路的輸出容量,則輸出隊列将開始變長。(一直增長到聚合輸入速率重新低于1mbps,此後該隊列長度才會減少。)因為在本例子中同時活躍使用者超過10個的機率極小,分組交換差不多總是提供了與電路交換相同的性能,并且允許在使用者數量是其3倍時情況也是如此。
我們現在考慮第二個簡單的例子。假定有10個使用者,某個使用者突然産生1000個1000比特的分組,而其他使用者則保持靜默,不産生分組。在每幀具有10個時隙并且每個時隙包含1000比特的tdm電路交換情況下,活躍使用者僅能使用每幀中的一個時隙來傳輸資料,而每個幀中剩餘的9個時隙保持空閑。該活躍使用者傳輸完所有106比特資料需要10s的時間。在分組交換情況下,活躍使用者能夠連續地以1mbps的全部鍊路速率發送其分組,因為沒有其他使用者産生分組與該活躍使用者的分組進行複用。在此情況下,該活躍使用者的所有資料将在1s内發送完畢。
上面的例子從兩個方面表明了分組交換的性能能夠優于電路交換的性能。這些例子也強調了兩種形式的在多個資料流之間共享鍊路傳輸速率的關鍵差異。電路交換不考慮需求,而預先配置設定了傳輸鍊路的使用,這使得已配置設定而并不需要的鍊路時間未被利用。另一方面,分組交換按需配置設定鍊路使用。鍊路傳輸能力将在所有使用者之間逐分組地被共享,這些使用者有分組需要在鍊路上傳輸。
雖然分組交換和電路交換在今天的電信網絡中都是普遍采用的方式,但趨勢無疑是朝着分組交換方向發展。甚至許多今天的電路交換電話網正在緩慢地向分組交換遷移。特别是,電話網經常在昂貴的海外電話部分使用分組交換。
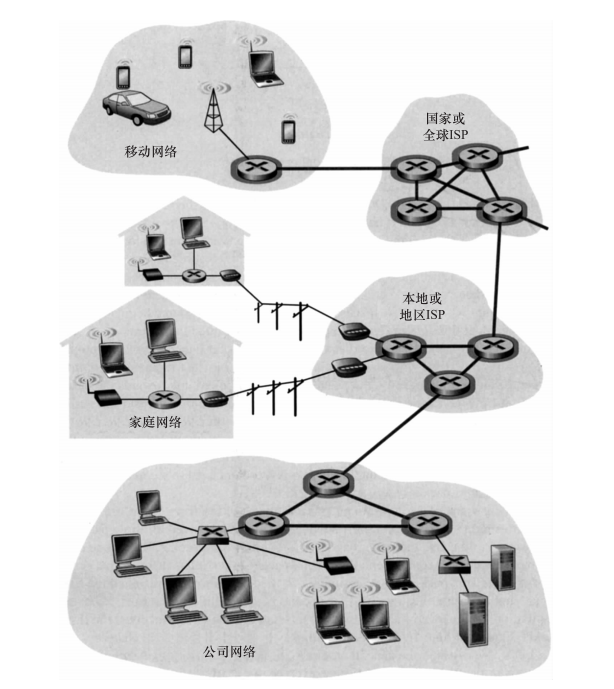
我們在前面看到,端系統(pc、智能手機、web伺服器、電子郵件伺服器等)經過一個接入isp與網際網路相連。該接入isp能夠提供有線或無線連接配接,使用了包括dsl、電纜、ftth、wifi和蜂窩等多種接入技術。值得注意的是,接入isp不必是本地電信局或電纜公司,相反,它能夠是如大學(為學生、教職員工和從業人員提供網際網路接入)或公司(為其雇員提供接入)這樣的機關。但為端使用者和内容提供商提供與接入isp的連接配接僅解決了連接配接難題中的很小一部分,因為網際網路是由數以億計的使用者構成的。要解決這個難題,接入isp自身必須互聯。通過建立網絡的網絡可以做到這一點,了解這個短語是了解網際網路的關鍵。
年複一年,構成網際網路的“網絡的網絡”已經演化成為一個非常複雜的結構。這種演化很大部分是由經濟和國家政策驅動的,而不是由性能考慮驅動的。為了了解今天的網際網路網絡結構,我們來逐漸遞進建造一系列網絡結構,其中的每個新結構都更好地接近我們現有的複雜網際網路。回顧前面互聯接入isp的目标,是使所有端系統能夠彼此發送分組。一種幼稚的方法是使每個接入isp直接與每個其他接入isp連接配接。當然,這樣的網狀設計對于接入isp費用太高,因為這将要求每個接入isp與世界上數十萬個其他接入isp有一條單獨的通信鍊路。
我們的第一個網絡結構即網絡結構1,用單一的全球承載isp互聯所有接入isp。我們假想的全球承載isp是一個由路由器和通信鍊路構成的網絡,該網絡不僅跨越全球,而且至少具有一個路由器靠近數十萬接入isp中的每一個。當然,對于全球承載isp,建造這樣一個大規模的網絡将耗資巨大。為了有利可圖,自然要向每個連接配接的接入isp收費,其價格反映(并不一定正比于)一個接入isp經過全球isp交換的流量大小。因為接入isp向全球承載isp付費,故接入isp被認為是客戶(customer),而全球承載isp被認為是提供商(provider)。
如果某個公司建立并運作了一個可赢利的全球承載isp,其他公司建立自己的全球承載isp并與最初的全球承載isp競争則是一件自然的事。這導緻了網絡結構2,它由數十萬接入isp和多個全球承載isp組成。接入isp無疑喜歡網絡結構2勝過喜歡網絡結構1,因為它們現在能夠根據價格和服務的函數,在多個競争的全球承載提供商之間進行選擇。然而,值得注意的是,這些全球承載isp之間必須是互聯的:不然的話,與某個全球承載isp連接配接的接入isp将不能與連接配接到其他全球承載isp的接入isp通信。
剛才描述的網絡結構2是一種兩層的等級結構,其中全球承載提供商位于頂層,而接入isp位于底層。這假設了全球承載isp不僅能夠接近每個接入isp,而且發現經濟上也希望這樣做。現實中,盡管某些isp确實具有令人印象深刻的全球覆寫,并且确實直接與許多接入isp連接配接,但世界上沒有isp是存在于每個城市中的。相反,在任何給定的區域,可能有一個區域isp(reginal isp),區域中的接入isp與之連接配接。每個區域isp則與第一層isp(tier-1 isp)連接配接。第一層isp類似于我們假想的全球承載isp;盡管第一層isp不是在世界上每個城市中都存在,但它确實存在。有大約十幾個第一層isp,包括level 3通信、at&t、sprint和ntt。有趣的是,沒有組織正式認可第一層狀态。俗話說:如果必須問你是否是一個組織的成員,你可能不是。
傳回到網絡的網絡,不僅有多個競争的第一層isp,而且在一個區域可能有多個競争的區域isp。在這樣的等級結構中,每個接入isp向區域isp支付其連接配接費用,并且每個區域isp向它連接配接的第一層isp支付費用。(一個接入isp也能直接與第一層isp連接配接,這樣它就向第一層isp付費。)是以,在這個等級結構的每層,有客戶-提供商關系。值得注意的是,第一層isp不向任何人付費,因為它們位于該等級結構的頂部。使事情更為複雜的是,在某些區域,可能有較大的區域isp(可能跨越整個國家),區域中較小的區域isp與之相連,較大的區域isp則與第一層isp連接配接。例如,在中國,每個城市有接入isp,它們與省級isp連接配接,省級isp又與國家級isp連接配接,國家級isp最終與第一層isp連接配接[tian 2012]。這個多層等級結構仍然僅僅是今天網際網路的粗略近似,我們稱它為網絡結構3。
為了建造一個與今天網際網路更為相似的網絡,我們必須在等級結構的網絡結構3上增加存在點(point of presence,pop)、多宿、對等和網際網路交換點(internet exchange point,ixp)。pop存在于等級結構的所有層次,但底層(接入isp)等級除外。一個pop隻是提供商網絡中的一台或多台路由器(在相同位置)群組,其中客戶isp能夠與提供商isp連接配接。對于要與提供商pop連接配接的客戶網絡,它能從第三方通信提供商租用高速鍊路直接将它的路由器之一連接配接到位于該pop的一台路由器。任何isp(除了第一層isp)可以選擇為多宿(multi-home),即可以與兩個或更多提供商isp連接配接。例如,一個接入isp可能與兩個區域isp多宿,或者可以與兩個區域isp多宿,也可以與多個第一層isp多宿。當一個isp多宿時,即使它的提供商之一出現故障,它仍然能夠繼續發送和接收分組。
正如我們剛才學習的,客戶isp向它們的提供商isp付費以獲得全球網際網路互聯能力。客戶isp支付給提供商isp的費用數額反映了它通過提供商交換的流量。為了減少這些費用,位于相同等級結構層次的鄰近一對isp能夠對等(peer),這就是說,能夠直接将它們的網絡連到一起,使它們之間的所有流量經直接連接配接而不是通過上遊的中間isp傳輸。當兩個isp對等時,通常不進行結算,即任一個isp不向其對等付費。如前面提到的那樣,第一層isp也與另一個第一層isp對等,它們之間無結算。對于對等和客戶-提供商關系可讀性的讨論,參見[van der berg 2008]。沿着這些相同路線,第三方公司建立一個網際網路交換點(internet exchange point,ixp)(通常在一個有自己的交換機的獨立建築物中),ixp是一個彙合點,多個isp能夠在這裡共同對等。在今天的網際網路中有大約300個ixp[augustin 2009]。我們稱這個系統為生态系統——由接入isp、區域isp、第一層isp、pop、多宿、對等和ixp組成,這個系統作為網絡結構4。
我們現在最終到達了網絡結構5,它描述了2012年的網際網路。在圖1-15中顯示了網絡結構5,它通過在網絡結構4頂部增加内容提供商網絡(content provider network)建構而成。谷歌是目前這樣的内容提供商網絡的一個突出例子。在本書寫作之時,谷歌估計有30~50個資料中心部署在北美、歐洲、亞洲、南美和澳洲。其中的某些資料中心容納了超過十萬台的伺服器,而另一些資料中心則較小,僅容納數百台伺服器。谷歌資料中心都經過專用的tcp/ip網絡互聯,該網絡跨越全球,但仍然獨立于公共網際網路。重要的是,谷歌專用網絡僅承載出入谷歌伺服器主機的流量。如圖1-15所示,谷歌專用網絡通過與較低層isp對等(無結算)嘗試“繞過”網際網路的較高層,采用的方式可以是直接與它們連接配接,或者在ixp處與它們連接配接[labovitz 2010]。然而,因為許多接入isp通過第一層網絡的承載仍能到達,是以谷歌網絡也與第一層isp連接配接,并就與它們交換的流量向這些isp付費。通過建立自己的網絡,内容提供商不僅減少了向頂層isp支付的費用,而且對其服務最終如何傳遞給端使用者有了更多的控制。谷歌的網絡基礎設施在7.2.4節中進行了較長的描述。
總結一下,今天的網際網路是一個網絡的網絡,其結構複雜,由十多個第一層isp和數十萬個較低層isp組成。isp覆寫的區域有所不同,有些跨越多個大洲和大洋,有些限于很小的地理區域。較低層的isp與較高層的isp相連,較高層isp彼此互聯。使用者和内容提供商是較低層isp的客戶,較低層isp是較高層isp的客戶。近年來,主要的内容提供商也已經建立自己的網絡,直接在可能的地方與較低層isp互聯。