如果覺得有幫助的話就頂下吧
在統計的時候經常會用到排重,比如想統計每日登陸使用者,但是一個使用者一次多次登陸情況,或者一個産品被多少個使用者下載下傳。。等等情況
截圖一是我之前寫的代碼:
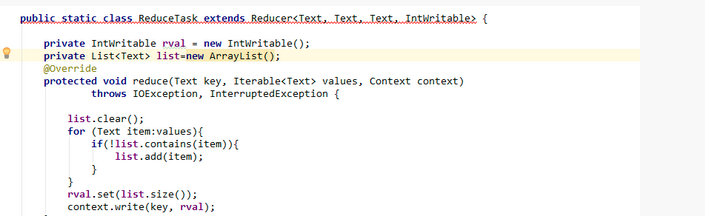
下面是我優化後代碼
multiset,會将相同的key,存到value種,隻要将key周遊出來取值的個數就是排重後的資料。
前者是循環嵌套查找但是占用記憶體少 ,1179個組,平均每個組被分到6萬條,最壞情況下(6w/2)^2*1179級别的循環,後者利用hashmap高效的存取值方式,是o(n)的級别,但是占用記憶體比較大
性能對比,下圖是輸入的資料,經過map的篩選,,

下圖是代碼1執行的用時
執行了一小時還沒結束,下圖是代碼二的時間 隻要倆分鐘不到,執行速度有大幅提升